centos 7 安装Ranchar 2.6
Rancher介绍
Rancher 是为使用容器的公司打造的容器管理平台。Rancher 简化了使用 Kubernetes 的流程,开发者可以随处运行 Kubernetes(Run Kubernetes Everywhere),满足 IT 需求规范,赋能 DevOps 团队
01 准备Linux主机
准备一台已安装64位Ubuntu 20.04或18.04的Linux主机(或其他Rancher所支持的Linux发行版),要求至少4GB内存。在该主机上安装Rancher支持的Docker版本。
02 运行Server
在主机上执行以下Docker命令,完成Rancher的安装与运行:
sudo docker run --privileged -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher:stable
打开浏览器,输入https://<安装容器的主机名或IP地址>,访问Rancher Server的UI。

03 打开UI&获取密码
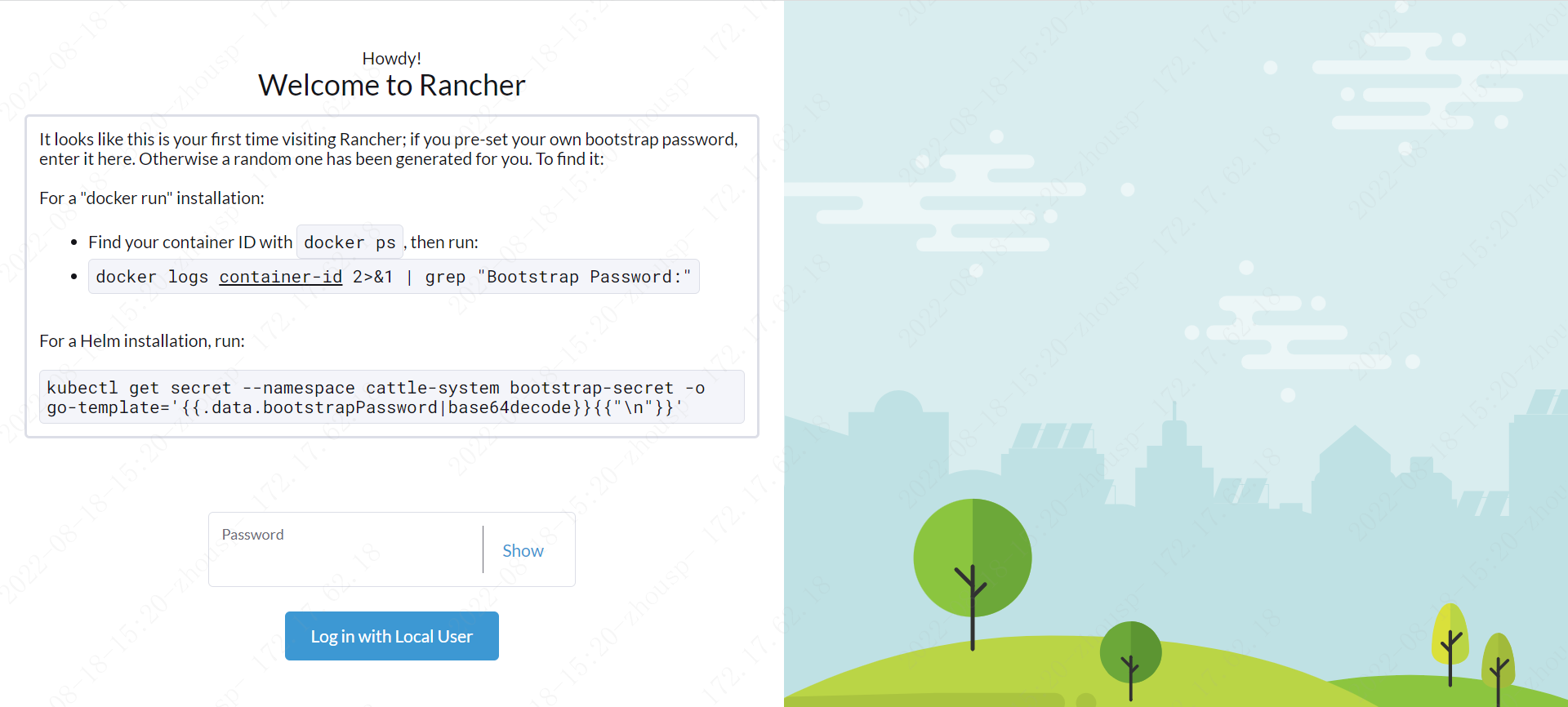
//获取容器id docker ps //获取密码 container-id 为刚刚获取的容器id docker logs container-id 2>&1 | grep "Bootstrap Password:"
04 设置密码 密码必须最少12个字符
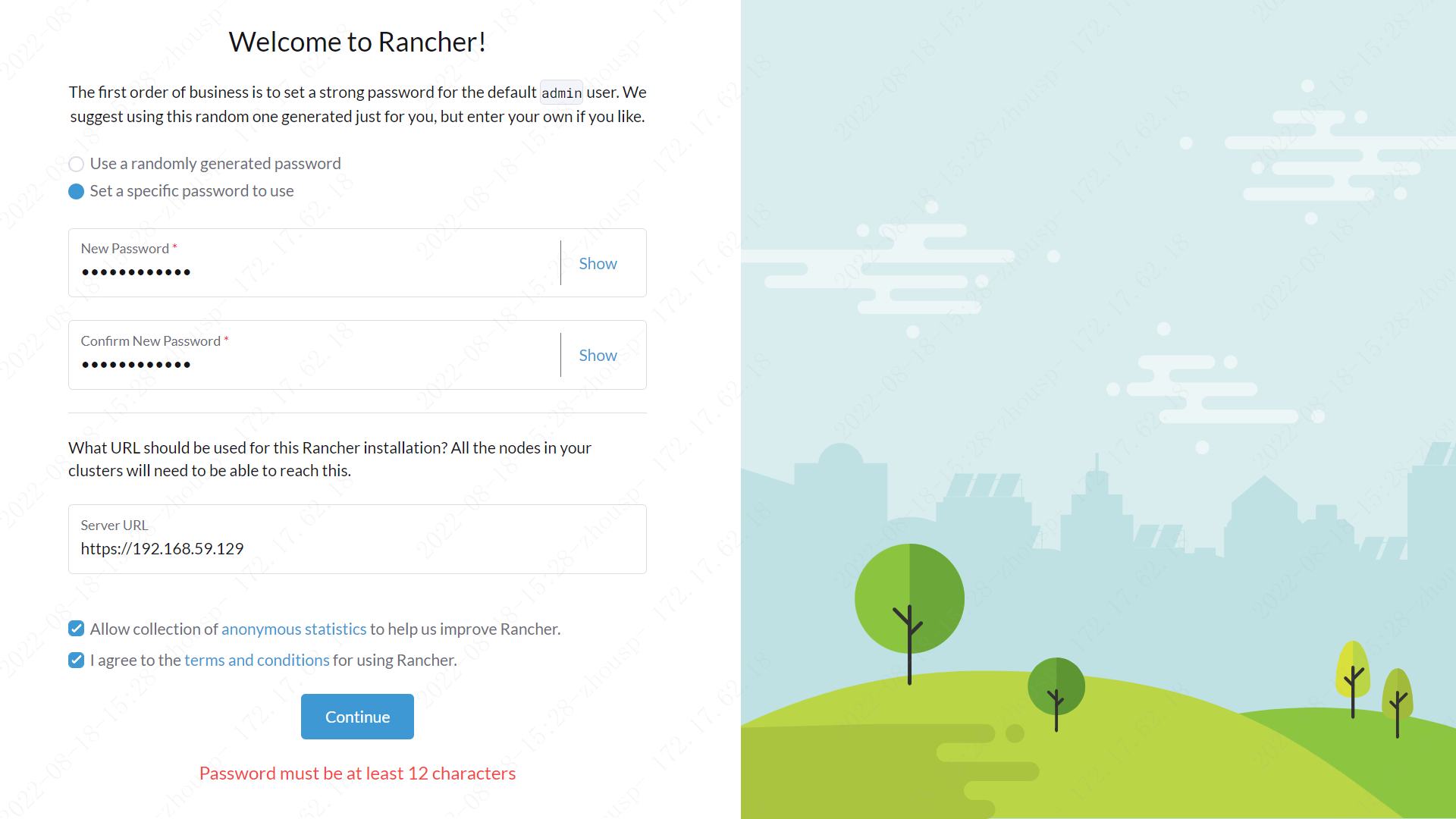
05 修改语言
06 创建集群
06.01 集群管理=>集群=>自定义
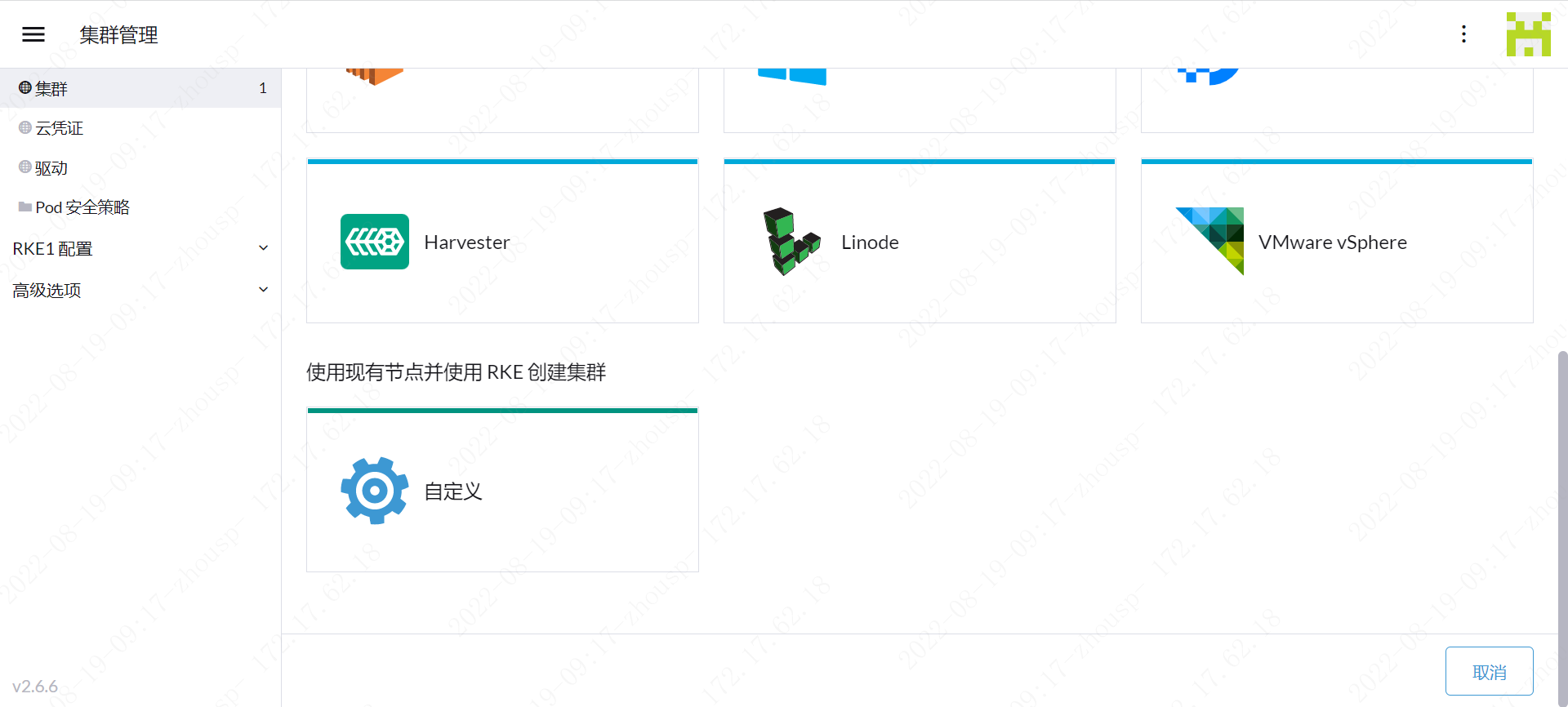
06.02 添加集群
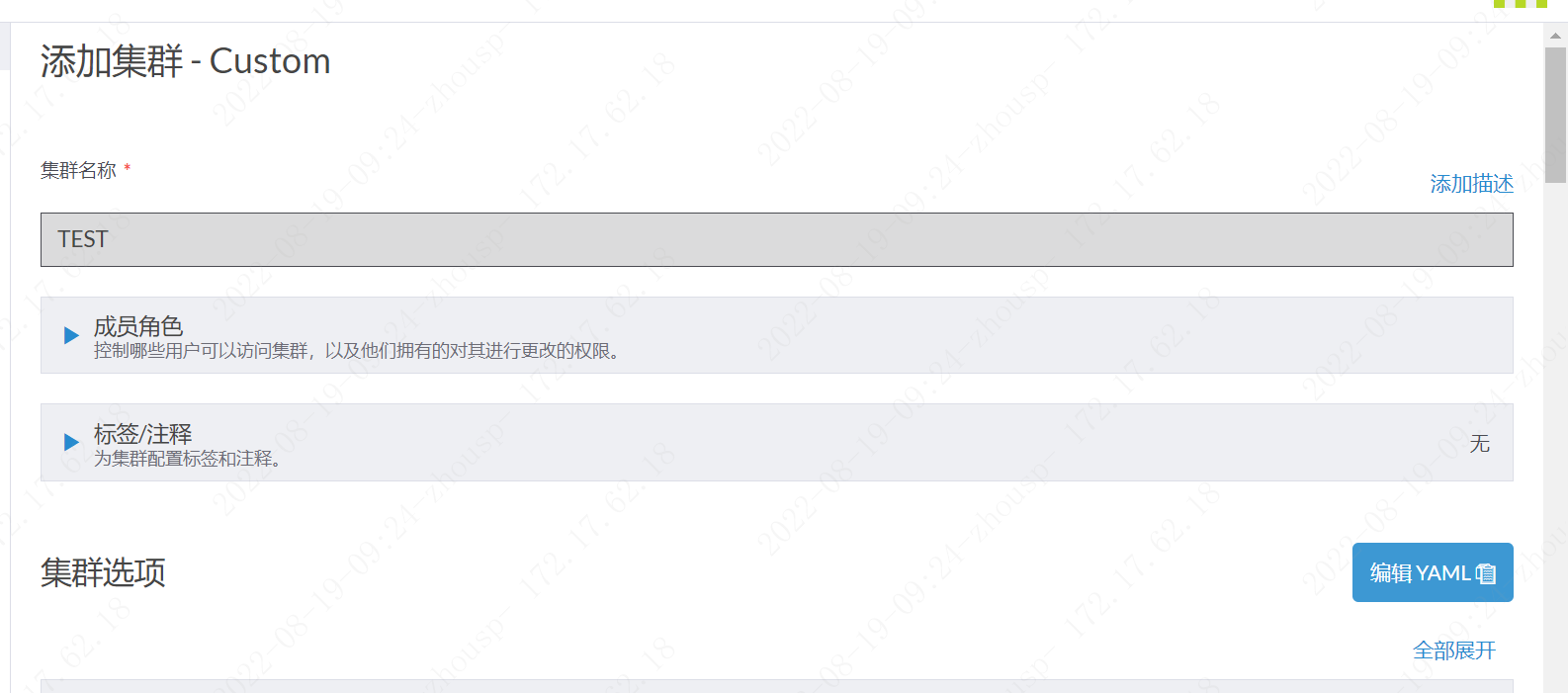
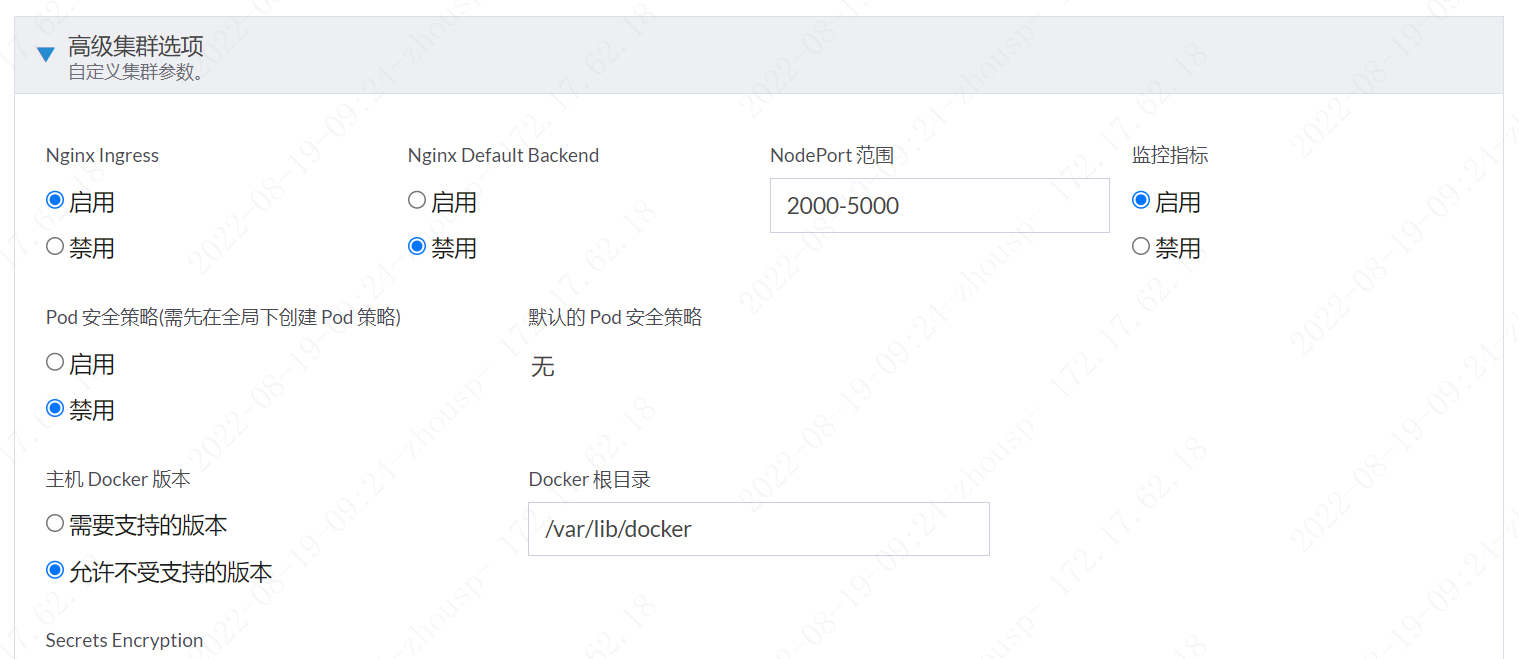
集群yaml


# # Cluster Config # docker_root_dir: /var/lib/docker enable_cluster_alerting: false enable_cluster_monitoring: false enable_network_policy: true local_cluster_auth_endpoint: enabled: true name: TEST # # Rancher Config # rancher_kubernetes_engine_config: addon_job_timeout: 45 authentication: strategy: x509 dns: nodelocal: ip_address: '' node_selector: null update_strategy: {} enable_cri_dockerd: false ignore_docker_version: true # # # 当前仅支持 nginx 的 ingress # # 设置`provider: none`禁用 ingress 控制器 # # 通过 node_selector 可以指定在某些节点上运行 ingress 控制器,例如: # provider: nginx # node_selector: # app: ingress # ingress: default_backend: false default_ingress_class: true http_port: 0 https_port: 0 provider: nginx kubernetes_version: v1.23.6-rancher1-1 monitoring: provider: metrics-server replicas: 1 # # # 如果您在 AWS 上使用 calico # # network: # plugin: calico # calico_network_provider: # cloud_provider: aws # # # 指定 flannel 网络接口 # # network: # plugin: flannel # flannel_network_provider: # iface: eth1 # # # 指定 canal 网络插件的 flannel 网络接口 # # network: # plugin: canal # canal_network_provider: # iface: eth1 # network: mtu: 0 options: flannel_backend_type: vxlan plugin: canal rotate_encryption_key: false # # # 自定义服务参数,仅适用于 Linux 环境 # services: # kube-api: # service_cluster_ip_range: 10.43.0.0/16 # extra_args: # watch-cache: true # kube-controller: # cluster_cidr: 10.42.0.0/16 # service_cluster_ip_range: 10.43.0.0/16 # extra_args: # # 修改每个节点子网大小(cidr 掩码长度),默认为 24,可用 IP 为 254 个;23,可用 IP 为 510 个;22,可用 IP 为 1022 个; # node-cidr-mask-size: 24 # # 控制器定时与节点通信以检查通信是否正常,周期默认 5s # node-monitor-period: '5s' # # 当节点通信失败后,再等一段时间 kubernetes 判定节点为 notready 状态。这个时间段必须是 kubelet 的 nodeStatusUpdateFrequency(默认 10s)的 N 倍,其中 N 表示允许 kubelet 同步节点状态的重试次数,默认 40s。 # node-monitor-grace-period: '20s' # # 再持续通信失败一段时间后,kubernetes 判定节点为 unhealthy 状态,默认 1m0s。 # node-startup-grace-period: '30s' # # 再持续失联一段时间,kubernetes 开始迁移失联节点的 Pod,默认 5m0s。 # pod-eviction-timeout: '1m' # kubelet: # cluster_domain: cluster.local # cluster_dns_server: 10.43.0.10 # # 扩展变量 # extra_args: # # 与 apiserver 会话时的并发数,默认是 10 # kube-api-burst: '30' # # 与 apiserver 会话时的 QPS,默认是 5 # kube-api-qps: '15' # # 修改节点最大 Pod 数量 # max-pods: '250' # # secrets 和 configmaps 同步到 Pod 需要的时间,默认一分钟 # sync-frequency: '3s' # # kubelet 默认一次拉取一个镜像,设置为 false 可以同时拉取多个镜像,前提是存储驱动要为 overlay2,对应的 Docker 也需要增加下载并发数 # serialize-image-pulls: false # # 拉取镜像的最大并发数,registry-burst 不能超过 registry-qps ,仅当 registry-qps 大于 0(零)时生效,(默认 10)。如果 registry-qps 为 0 则不限制(默认 5)。 # registry-burst: '10' # registry-qps: '0' # # 以下配置用于配置节点资源预留和限制 # cgroups-per-qos: 'true' # cgroup-driver: cgroupfs # # 以下两个参数指明为相关服务预留多少资源,仅用于调度,不做实际限制 # system-reserved: 'memory=300Mi' # kube-reserved: 'memory=2Gi' # enforce-node-allocatable: 'pods' # # 硬驱逐阈值,当节点上的可用资源少于这个值时,就会触发强制驱逐。强制驱逐会强制 kill 掉 POD,不会等 POD 自动退出。 # eviction-hard: 'memory.available<300Mi,nodefs.available<10%,imagefs.available<15%,nodefs.inodesFree<5%' # # 软驱逐阈值 # ## 以下四个参数配套使用,当节点上的可用资源少于这个值时但大于硬驱逐阈值时候,会等待 eviction-soft-grace-period 设置的时长; # ## 等待中每 10s 检查一次,当最后一次检查还触发了软驱逐阈值就会开始驱逐,驱逐不会直接 Kill POD,先发送停止信号给 POD,然后等待 eviction-max-pod-grace-period 设置的时长; # ## 在 eviction-max-pod-grace-period 时长之后,如果 POD 还未退出则发送强制 kill POD # eviction-soft: 'memory.available<500Mi,nodefs.available<50%,imagefs.available<50%,nodefs.inodesFree<10%' # eviction-soft-grace-period: 'memory.available=1m30s' # eviction-max-pod-grace-period: '30' # ## 当处于驱逐状态的节点不可调度,当节点恢复正常状态后 # eviction-pressure-transition-period: '5m0s' # extra_binds: # - "/usr/libexec/kubernetes/kubelet-plugins:/usr/libexec/kubernetes/kubelet-plugins" # - "/etc/iscsi:/etc/iscsi" # - "/sbin/iscsiadm:/sbin/iscsiadm" # etcd: # # 修改空间配额为$((4*1024*1024*1024)),默认 2G,最大 8G # extra_args: # quota-backend-bytes: '4294967296' # auto-compaction-retention: 240 #(单位小时) # kubeproxy: # extra_args: # # 默认使用 iptables 进行数据转发 # proxy-mode: "" # 如果要启用 ipvs,则此处设置为`ipvs` # services: etcd: backup_config: enabled: true interval_hours: 12 retention: 6 safe_timestamp: false timeout: 300 creation: 12h extra_args: election-timeout: 5000 heartbeat-interval: 500 gid: 0 retention: 72h snapshot: false uid: 0 kube_api: always_pull_images: false pod_security_policy: false secrets_encryption_config: enabled: false service_node_port_range: 2000-5000 ssh_agent_auth: false upgrade_strategy: max_unavailable_controlplane: '1' max_unavailable_worker: 10% node_drain_input: delete_local_data: false force: false grace_period: -1 ignore_daemon_sets: true timeout: 120 windows_prefered_cluster: false
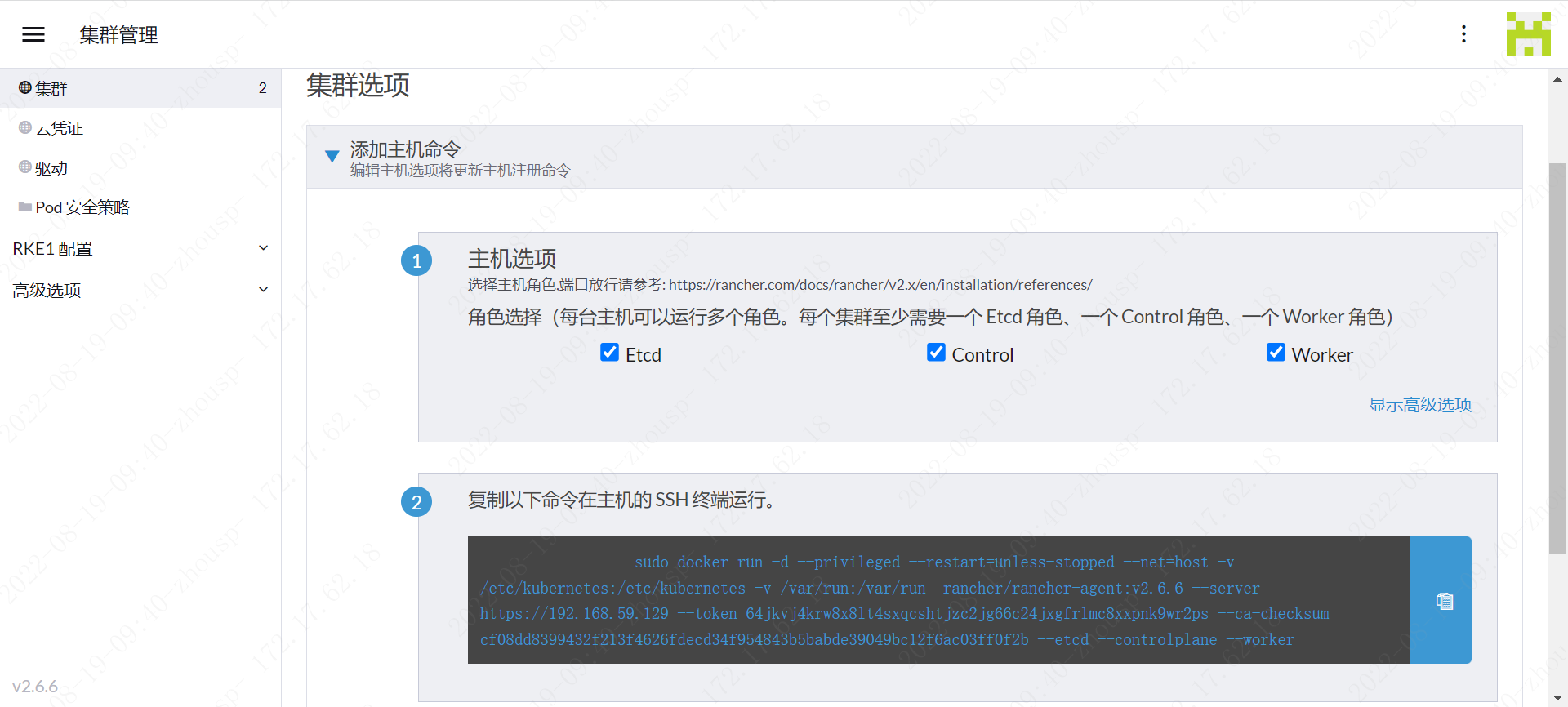
复制主机选项到对应服务器执行,高可用集群条件ETCD Control节点在三台或以上,只有一台服务器全部勾选即可,ETCD 是Kubernetes的主数据存储,Control 控制节点,Worker节点是用于部署应用的节点。
传送门:
docker安装:https://www.cnblogs.com/zspwf/p/16598589.html
rancher文档:https://www.rancher.cn/products/rancher/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号