寒假作业2/2
| 这个作业属于哪个课程 | 2021春软工实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 1.阅读《构建之法》并提问 2.完成词频统计个人作业 |
| 其他参考文献 | CSDN、博客园、Git |
GitHub:项目地址
part1:阅读《构建之法》并提问
1.阅读《构建之法》并提问
- Q1:我看了这一段文字(软件系统是给用户使用的,用户的需求并不是要看这个机构的内部组织架构图,而是要解决用户的问题。 一个合适的团队结构,能更大地改进交流的效率,让团队更能把注意力集中在最主要的目标——解决用户需求上面。),有这个问题针对每个团队各自队员不同的脾性、能力,怎么在一开始选择一个“合适” 的团队模式。我查了资料,有这些说法(1.团员组成之际大家都应当有各自擅长的方面 2.多进行一些拓展活动让大家迅速的熟悉起来 3.根据大家的特点去挑选适合这个项目组的团队模式),根据我的实践,我得到这些经验(就以团队成员的身份而言,一个人要学会融入,不管一个人技术怎么过硬,都是需要团队的帮助的,但是还是很难避免团队之中有个别人员不太配合)。 但是我还是不太懂,我的困惑是(如若,既定了一个尽可能优的团队模式下,还是有个别团队成员不愿意配合,又该如何)。
- Q2:我看了这一段文字(如果使用QWERTY键盘,那么只有10%的英语单词能在手指不离开键盘中列(Home Row,即ASDFG那一排)的情况下敲出来。但是如果使用Dvorak键盘布局,你可以在键盘中列打出60%的常用单词。但是,长期以来,人们已经习惯了QWERTY键盘,所谓先入为主),有这个问题如果我有一个更好的创新性想法,改变某一原有事物,使得它的效率大提高,但由于人们总是习惯于先入为主,我的创新性行为失去了意义,我还要继续吗?我查了资料,有这些说法(让别人清楚的看到创新想法与之前之间的区别,展示创新想法的优势,并勇敢尝试),根据我的实践,我得到这些经验(就我自己而言,在我用惯了一个软件之后,别人告诉我另一个软件其实更好用,我也依旧懒于尝试。)。 但是我还是不太懂,我的困惑是(如果我花费了大量心思完成了我的创新想法,但依旧没什么接受度,怎么办)。
- Q3:我看了这一段文字(软件工程专家Paul Rook说,“我们其实并不是不会估计,我们真正不会的,是把估计后面藏着的种种假设全部列举出来”。),有这个问题我们在平时编程作业布置下来时,也常常错误估计了自己的预期完成时间,导致尝尝在ddl前疯狂挣扎,所以到底如何正确预估项目所需时间?。我查了资料,有这些说法(1.降低任务的分解粒度 2.使用任务列表,列表包括任何测试和集成工作),根据我的实践,我得到这些经验(就我目前依照PSP表格估计作业时间,但依旧和实践花费时间存在不小的差距)。
- Q4:我看了这一段文字(每个人每天的高效率工作时段不超过3—4个小时。结对编程中驾驶员和领航员的角色要经常互换,避免长时间紧张工作而导致观察力和判断力下降。),有这个问题在结对编程中,两个经常交换角色不会导致打断思路,降低效率吗。我查了资料,有这些说法(一定时间周期地打乱配对,让参与项目的人员相互转换位置,容易让所有人都熟悉每个模块,这样对于公司也很有好处),根据我的实践,我得到这些经验(经常的角色交换虽然如何资料而言可以使大家对各模块更熟悉,但对我自己而言,角色的交换很多时候会把我既定的思路打乱,再次回到原来的位置时还要重新进入状态,效率降低了些许)。
- Q5:我看了这一段文字(我们都用过各种电视/DVD播放器的遥控器,功能很强,按钮很多吧?你有没有注意到老人家使用遥控器时的困难?我们常说做产品要从用户的角度考虑问题,这需要有“同理心”。),有这个问题一个产品它的受众是许多的,每个人的适应度不同,虽有“同理心”,但大家感受不一,最后的设计到底该如何抉择。我查了资料,有这些说法(针对主要受众人群来抉择),根据我的实践,我得到这些经验(就如遥控器而言,功能展示在按钮上进行,于我来说感觉还是很方便,但我的家长就觉得如果简单些更好)。 但是我还是不太懂,我的困惑是(如果两个适应方向达到近1:1,如何抉择)。
2.附加题
也许最令人难以置信的是,历史上第一位程序员是位女性。她的名字是Ada Lovelace。在1843年,这位英国数学家Ada Lovelace,翻译了意大利工程师Luigi Menabreaw撰写的分析引擎文章。在翻译过程中,她把自己的理解都批注到每篇文章下,而这举动加快了计算机编程技术的发展。在这之后,她又设计出了第一种能够利用分析引擎计算伯努利数的算法,这也是第一个用电脑编写的算法。
参考链接
见解: 无论何人,其能力与创造力都是不容小觑的。
part2:WordCount编程
1.Github项目地址
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| • Estimate | • 估计这个任务需要多少时间 | 15 | 20 |
| Development | 开发 | 400 | 460 |
| • Analysis | • 需求分析 (包括学习新技术) | 40 | 60 |
| • Design Spec | • 生成设计文档 | 20 | 20 |
| • Design Review | • 设计复审 | 10 | 15 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| • Design | • 具体设计 | 20 | 20 |
| • Coding | • 具体编码 | 200 | 220 |
| • Code Review | • 代码复审 | 30 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 70 |
| Reporting | 报告 | 70 | 90 |
| • Test Repor | • 测试报告 | 45 | 60 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 15 | 20 |
| 合计 | 485 | 570 |
3.解题思路描述
仔细阅读完作业题目要求后,发现题目要实现6个功能,具体需求为:
- 1.读取txt文件中的内容
- 2.统计文件的字符数
- 3.统计文件的单词总数
- 4.统计统计文件的有效行数
- 5.统计文件中各单词的出现次数,并输出频率最高的10个
- 6.将输出结果写入txt文件
分析完需求后,问题首先要解决的就是如何进行文件的读写
针对第二个需求统计文件的字符数,我首先想到的就是采用一个字符一个字符的读取文件内容,这样可以更好的对每一个字符进行判断。而后的几个需求,我认为采用行方式读取文件内容,对于功能的实现会简单些。
对于第三个需求,我的想法是将文件每行的内容采用分割法,以非字母、数字的分割符将其分割保存在数组中,在对每个划分后的词进行判断是否为有效单词,但这个分割的方法一开始让我无从下手,后面在CSDN上查找资料发现了正则表达式,这样单词的分割就简单了许多。
第四个需求也是对文件的每行单独判断,想着尝试将字符串中的空字符以空字符串代替,后面查找资料发现了replaceAll("\s*","")方法。
针对第五个需求,采用同需求三一样的方法先划分单词,然后再将有效单词转换为小写保存在Map中,每次有效单词出现就先判断是否存在,存在则将value+1,否则就存入新的有效单词。词频的统计我是在CSDN上查找了Map<String,Integer>的排序方法,并且修改排序规则从而实现的。
4.代码规范制定链接
5.设计与实现过程
相关类的设计
根据程序功能要求,划分为一个主函数,两个类
- WordCount 主函数
- FileIO 实现文件的读取,以及将结果写入文件
- DoWordCount 实现字符、单词、函数、单词词频的计算
相关函数的设计
1. FileIO:
getReader(String filePath) //返回文件读取的Reader
readFile(String filePath) //以ArrayList<String>形式返回文件读取内容
writeToFile(String filePath, String str) //将结果写入指定的文件中
2. DoWordCount:
countChars(String filePath) //统计字符数
countWords(ArrayList<String> lines) //统计有效单词数
countLines(ArrayList<String> lines) //统计有效行数
sortWords(ArrayList<String> lines) //单词词频统计并排序后输出Top10
printTop10(List<Map.Entry<String, Integer>> maplist) //将词频Top10以字符串形式返回
isValidWord(char[] word) //判断是否为有效单词
isAlpha(int temp) //判断是否为字母
函数关系
- countChars调用getReader,得到其返回的Reader进行以单个字符形式的文件读取
- countWords、countLines、sortWords的参数皆为readFile返回的ArrayList
- countWords中在判断是否为有效单词时,调用了isValidWord函数,isValidWord函数中判断单词前四位是否为字母时调用了isAlpha函数
- printTop10的参数为sortWords函数Map排序后返回的List<Map.Entry<String, Integer>>
运行结果
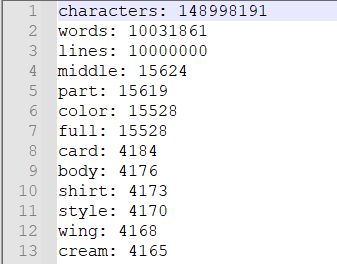
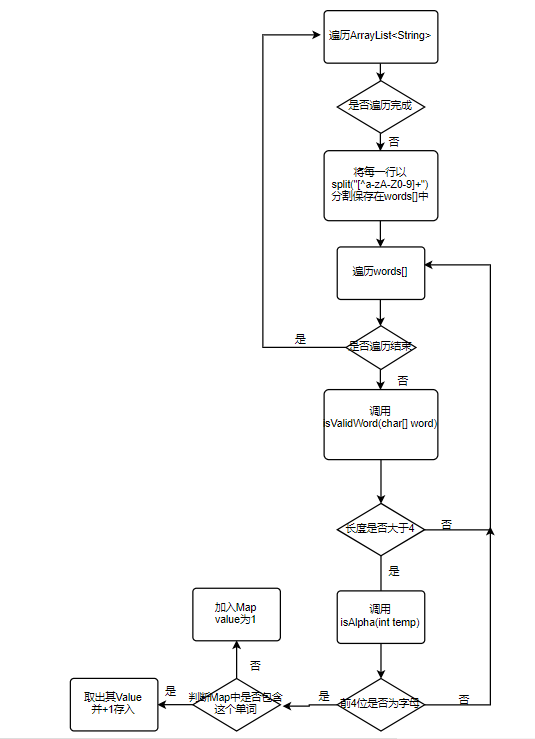
流程图
统计文件中各单词的出现次数
关键代码
//统计字符数,空格,水平制表符,换行符,均算字符
while ((tempChar = reader.read()) != -1) {
sum++;
}
在单词分割上,我使用了正则表达式(这应该就是我这代码里面唯一的独到之处了) ,使用非字母和数字来分割文件内容的每一行,在对分割后的单词逐一进行判断,调用isValidWord(word)方法判断其长度是否满足要求,isValidWord(word)方法里面又调用了isAlpha()方法判断前四位是否为字母。
//统计文件的单词总数 单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
for (int i = 0; i < lines.size(); i++) {
line = lines.get(i);
words = line.split("[^a-zA-Z0-9]+");
for (int j = 0; j < words.length; j++) {
char[] word = words[j].toCharArray();
if (isValidWord(word)) {
sum++;
}
}
}
将文件的每一行中的空白符以空字符串代替,在将其与空字符串比较,若非空,则为有效行。
//统计文件的有效行数:任何包含非空白字符的行,都需要统计。
for (int i = 0; i < lines.size(); i++) {
line = lines.get(i);
line = line.replaceAll("\\s*", "");
if (!(line.equals(""))) {
sum++;
}
}
同前面一样,先判断是否为有效单词,若有效,将其转换为小写,然后使用map进行储存,因为map的key不可重复,所以每次写入前判断map之前是否存在过该数据,若没有存在过,则该value值为1,否则,在其value值上再加1.最后将map改为list存储,再用Collections.sort进行排序,通过重写comparator来实现要求的排序,当单词的数量一致时,则比较单词在字典序的先后。
//统计文件中各单词的出现次数并排序
if (isValidWord(word)) {
tempWord = words[j].toLowerCase();
if (!map.containsKey(tempWord)) {
map.put(tempWord, Integer.valueOf(1));
} else {
map.put(tempWord, Integer.valueOf(map.get(tempWord).intValue() + 1));
}
}
//通过ArrayList构造函数把map.entrySet()转换成list
List<Map.Entry<String, Integer>> mappingList = new ArrayList<>(map.entrySet());
//通过比较器实现比较排序
Collections.sort(mappingList, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if (o1.getValue().equals(o2.getValue())) {
return o1.getKey().compareTo(o2.getKey());
} else {
return o2.getValue().compareTo(o1.getValue());
}
}
});
6.性能改进
- 程序中,我在判断是否为有效单词时使用了较多的char[],并在循环中进行判断,是致成性能瓶颈的一部分。就目前没有想到别的更优解决方法。
- 用BufferedWriter代替FileWriter:FileWriter继承了OutputStreamWriter,这意味着它的写入是由FileOutputStream实现的;而BufferedWriter直接继承于java.io.Writer。FileWriter每次调用write()方法,就会调用一次OutputStreamWriter中的write()方法;而BufferedWriter只有在缓冲区满了才会调用OutputStreamWriter中的write()方法。但由于我们此次的输出到文件的数据量并不多,所以在时间上产生的差异并不大。
7.单元测试
1.单元测试数据:
- 构造思路:尽量涵盖所有可能出错的范围
- 单元测试数据:空文本、文本只包含空格,换行符与制表符、大小写单词、非法单词、空格分割单词、其他符号分割单词、同频单词以字典序排序、小于10个单词、多于10个单词、只含空白符行、大量数据 (上述测试全部通过)
2.测试覆盖率截图:

3.如何优化覆盖率:
- 文件数据等测试,加快速度可以一次性加入内存跑
- 有些测试比较重要,但又影响速度(高并发,多线程,高计算,高频访问redis,memcached等等),可以考虑自己跑完后,直接@Ignore或者拆分小方法,慢的部分Ignore。
- 方法体尽量小,一入一出,不要使用变量传递。
4.单元测试代码: 将测试函数的结果与预期结果使用assertEquals(xxx,xxx)进行比较
@org.junit.Test
public void countChars() {
String inFile = "C:\\Users\\yy\\IdeaProjects\\WordCount\\src\\input1.txt";
int characters=0;
try {
characters=DoWordCount.countChars(inFile);
assertEquals(44, characters);
} catch (IOException e) {
e.printStackTrace();
}
}
8.异常处理说明
- 异常处理命令行参数无输入/输出文件的情况:
if(args.length!=2){
System.out.println("参数输入个数有误,请重新输入");
return ;
}
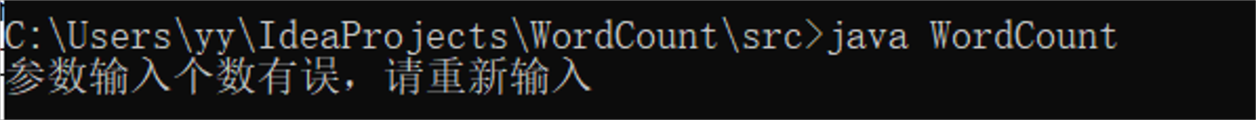
- 输出文件不存在时,系统会自动创建输出文件。
- 剩余的输入流异常,抛出到最外面同一处理。
9.心路历程与收获
在这次的作业中,我学到了很多编写代码以外其他的很多内容,也更加体会到了软件工程这门课的重要性。接触了Git和GitHub,并了解了如何使用github发布项目和控制版本,不在只是停留在纸面上的认识,一旦项目有进展便签入GitHub,也使我更加深刻感到它带来的好处。在此次的实践中,我也学会了按照PSP表格对项目进行一步一步的构建完成,不像之前一股脑就开始进入编程阶段,按照这样的方式写出来的程序可靠性也要来的强得多。并且在此次的作业中,也严格规范了自己的代码风格,对我来说有又是一次成长。虽然一开始感觉好多东西都在我的知识盲区中,但是每次作业的完成,对未知知识的探索,都是一次极好的体验。
