
scrapy-redis
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,即:
* 请求对象的持久化
* 去重的持久化
* 和实现分布式
scrapy_redis的流程
在scrapy_redis中,所有的带抓取的对象和去重的指纹都存在所有的服务器公用的redis中
所有的服务器公用一个redis中的request对象
所有的request对象存入redis前,都会在同一个redis中进行判断,之前是否已经存入过
在默认情况下所有的数据会保存在redis中
具体流程:
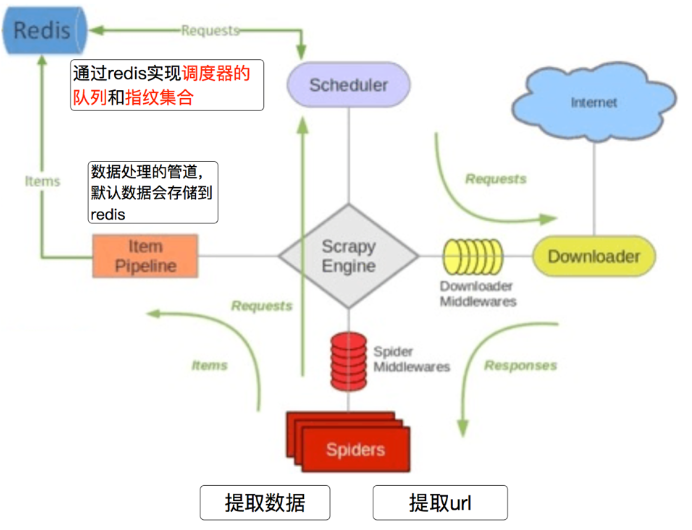
通过redis实现请求对象的持久化、去重持久化、分布式
具体:
请求对象持久化:如果没有存到redis中,程序运行时通过调度器保存到队列中,一旦遇意外情况,数据就没有了,但是如果要是存到redis中,即使程序断开了,下次重新启动,redis中的数据依然存在,会从redis中读request对象出来
去重持久化:引擎把request对象传到调度器的时候,会计算出每一个request对象的指纹,然后指纹默认情况下是存在内存中的,程序断了也就没有了,如果存到redis中的话,下次request对象存到redis之前的时候会进行判断指纹存不存在,如果存在即可不保存
分布式:因为默认情况下所有的数据都存在redis中,只要保证同一个redis,程序A如果去redis中获取url之后,程序B再去获取url的话,就会先行进行判断,如果获取过了即不获取了
数据处理的管道默认情况下数据也是会存到redis中,为什么不存到mysql和mongodb中?因为获取数据的时候,如果每秒获取的数据量过大,会发生阻塞情况,因为redis处理速度比较快,即可很好的解决这个问题,如果后期还要往mysql和mongodb中存的话,可以再写其他程序进行保存,但是如果每秒获取的数据量不大的情况下也可以存到mysql和mongodb中


 浙公网安备 33010602011771号
浙公网安备 33010602011771号