存储过程模糊搜索,按匹配率排序初探
最近的项目中有个搜索的功能,本来说,搜索简单做就可以了,直接like百分号就Ok了。但想了想,咱必须做点高大上的东西出来啊,再加上想练习下我并不熟练的存储过程,所以,决定搞得高大上些。以前做搜索的时候没有考虑那么多,但毕竟项目的使用者是广大用户,为了增加用户体验,所以应该提供给用户最想搜索的结果给用户,这里就涉及到了排序,而且是按匹配率排序,也可以说是精确度吧。网上找了会也没找到合适的。所以就自己写了。
首先说下我的思维原理:第一步,将要搜索的关键词进行分割,单独进行模糊匹配。例如:“我是中国人”分割成"我","我是","我是中","我是中国",“我是中国人”,分别对这些关键词进行匹配,第二步,将匹配结果分配到对应的字段,然后按最长的关键词进行排序,就得到了我们想要的结果。
分配关键词的逻辑本来也是打算写到程序代码中的,然后动态生成sql语句,发送到数据库进行执行,但之前不知道在哪儿看到的一篇文章,大概意思就是这样会增加网络的吞吐量(现在也无从考证了,知道的告诉我一下吧。)。所以就把整个逻辑写到了存储过程中。
下面直接上sql代码
1 create proc [dbo].[sp_Fuzzy_Search] 2 @keyword nvarchar(15),--将关键词限制在15个字。主要出于性能的原因。再者是匹配一个的搜索词差不多已经可以满足用户的搜索需求了。 3 @tablename varchar(20),--要搜索的表明 4 @cellname varchar(20)--要匹配的字段。此处就写了一个字段,多个字段的匹配不在考虑范围内。 5 as 6 begin 7 declare @sql nvarchar(500), @num int,@i int,@orderby varchar(200) 8 set @i=0 9 set @num=len(@keyword) 10 set @sql='select id,'+@cellname+' from ( select id, '+@cellname+',' 11 set @orderby='' 12 while @i<@num --循环获取关键词。此处是从最长的关键词进行循环的,有利于排序的处理。 13 begin 14 set @sql+=' case when PATINDEX(''%'+substring(@keyword,1,@num)+'%'','+@cellname+')>0 then 1 else 0 end as t'+convert(varchar,@num)+',' 15 set @orderby+='t'+convert(varchar,@num)+' desc,' 16 set @num-=1 17 18 end 19 --拼接sql语句 20 set @sql=left(@sql,len(@sql)-1)+' from '+@tablename+') as TT where t1>0 order by '+left(@orderby,len(@orderby)-1) 21 --执行拼接好的sql语句。 22 EXEC sp_executesql @sql 23 24 end
测试用数据如下图:
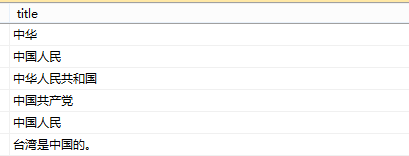
搜索关键词“中国人”,返回值如下:

大概思路就是这样的,貌似有点bug,各位看官有好的意见或建议,还请不吝赐教。 谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号