
随机森林
0. 前言
sklearn提供了sklearn.ensemble库,其中包括随机森林模型(分类)。但之前使用这个模型的时候,要么使用默认参数,要么将调参的工作丢给调参算法(grid search等)。今天想来深究一下到底是如何选择参数,如何进行调参。
学会调参是进行集成学习工作的前提。参数可分为两种,一种是影响模型在训练集上的准确度或影响防止过拟合能力的参数;另一种不影响这两者的其他参数。模型的准确度由其在训练集上的准确度及其防止过拟合的能力所共同决定,所以在调参时,我们主要对第一种参数进行调整,最终达到的效果是:模型在训练集上的准确度和防止过拟合能力的平衡。
1. 集成学习是什么
集成学习通过构建并结合多个学习器来完成学习任务。 集成学习的一般结构:先产生一组“个体学习器”(individual learner),然后再用某种策略将它们结合起来。个体学习器通常有一个现有的学习算法从训练数据产生,此时集成中只包含同种类型的个体学习器,比如“决策树集成”,此时的集合里全部都是决策树。同质集成中的个体学习器称为“基学习器”(base learner),相应的学习算法成为“基学习算法”(base learning algorithm)。
因为集成学习通过对多个“弱学习器”进行结合,可以获得比单一学习器更加显著的泛化性能,所以集成学习的很多理论研究是针对弱学习器的。因此“基学习器”有时会被直接称之为弱学习器或者弱模型,通常来说弱模型是偏差高(在训练集上准确度低)方差小(防止过拟合能力强)的模型。
在验证集成学习可以获得更好的泛化性能过程中有一个重要的前提假设就是:基学习器的误差相互独立。而在现实任务中,基学习器不可能相互独立。所以其准确性和多样性本身就存在冲突,比如准确性很高就容易产生过拟合现象。所以如何产生“好而不同”的个体学习器,是集成学习研究的核心。
根据个体学习器的生成方式,目前的集成学习方法大致分为两类:
a:个体学习器之间存在强依赖关系、必须串行生成的序列化方法:代表为boosting
b:个体学习器之间不存在强依赖关系、可以同时生成的并行化方法:代表为bagging和随机森林
本文主要关注第二类。
注意,并不是所有集成学习框架中的基模型都是弱模型。bagging中的基模型为强模型(偏差低方差高),boosting中的基模型为弱模型。
2. 偏差与方差
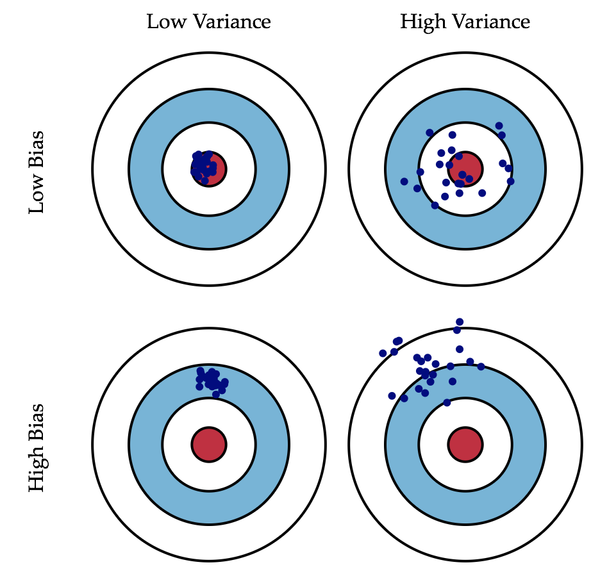
广义的偏差(bias)描述的是预测值和真实值之间的差异,方差(variance)描述距的是预测值作为随机变量的离散程度。《Understanding the Bias-Variance Tradeoff》当中有一副图形象地向我们展示了偏差和方差的关系:
|
2.1 偏差 模型的偏差是一个相对来说简单的概念:训练出来的模型在训练集上的准确度。偏差度量了学习算法的期望预测与真实结果的偏离程度,刻画了学习算法的本身你和能力。 2.2 方差 我们认为方差越大的模型越容易过拟合:假设有两个训练集A和B,经过A训练的模型Fa与经过B训练的模型Fb差异很大,这意味着Fa在类A的样本集合上有更好的性能,而Fb反之,这便是我们所说的过拟合现象。方差度量了同样大小的训练集的变动导致的学习性能的变化,即刻画了数据扰动所造成的影响。 2.3 泛化性能 根据偏差-方差分解说明(《机器学习(周志华)第44页),泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度共同决定的。给定的学习任务,为了取得良好的性能,需要使偏差较小(充分拟合数据),方差较小(数据扰动产生影响小)。 我认为书中第46页一段话能解释什么样的参数是我们所需要能得到最优泛化性能的,摘录如下“一般来讲,偏差与方差是有冲突的,称为偏差-方差窘境(bias-varince dilemma)。 给定学习任务,假定我们能控制学习算法的训练程度,则在训练不足时,学习器的拟合能力不够强, 训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的特性被学习器学习到了,则将发生过拟合。” 对于bagging来说,,整体模型的期望近似于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。同时,整体模型的方差小于等于基模型的方差(当相关性为1时取等号),随着基模型数(m)的增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于1吗?并不一定,当基模型数增加到一定程度时,方差公式第二项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。另外,在此我们还知道了为什么bagging中的基模型一定要为强模型,否则就会导致整体模型的偏差度低,即准确度低。 3. Random Forest Random Forest是Bagging的一个扩展变体。RF在以决策树为基学习器构建Bagging的基础上,进一步在决策树的训练过程中引入了随机属性选择。即在树的内部节点分裂过程中,不再是将所有特征,而是随机抽样一部分特征纳入分裂的候选项。这样一来,基模型之间的相关性降低,从而在方差公式中,继续导致整体方差仍是减少。 在sklearn.ensemble库中,我们可以找到Random Forest分类和回归的实现:RandomForestClassifier和RandomForestRegression。本文主要关注分类。 回顾上文,参数可分为两种,一种是影响模型在训练集上的准确度或影响防止过拟合能力的参数;另一种不影响这两者的其他参数。所以调参的步骤如下: a:我们的目标是找到第一种参数,确定对目标是正影响还是负影响和影响的大小 b:通过某些策略提高训练效率 c:训练过程的检测 对于a,我们可以把模型的参数分为4类:目标类、性能类、效率类和附加类。下表详细地展示了RF中这4个模型参数的意义: 注:下表是直接从http://www.cnblogs.com/jasonfreak/p/5657196.html 中copy过来的,所以包含其他三种模型,不过真的好赞~~~
上述第一种影响准确度的参数又可分为两类:过程影响类及子模型影响类。在子模型不变的前提下,某些参数可以通过改变训练的过程,从而影响模型的性能,诸如:“子模型数”(n_estimators)、“学习率”(learning_rate)等。还可以通过改变子模型性能来影响整体模型的性能,诸如:“最大树深度”(max_depth)、“分裂条件”(criterion)等。现在可以进一步明确目标了,RF基学习器都拥有较低的偏差,整体模型的训练过程旨在降低方差,故其需要较少的子模型(n_estimators默认值为10)且子模型不为弱模型(max_depth的默认值为None),同时,降低子模型间的相关度可以起到减少整体模型的方差的效果(max_features的默认值为auto)。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号