

Hive—分区表
一、什么是分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
二、分区表的操作
2.1 分区表基本操作
1.引入分区表(需要根据日期对日志进行管理)
/user/hive/warehouse/log_partition/20170702/20170702.log
/user/hive/warehouse/log_partition/20170703/20170703.log
/user/hive/warehouse/log_partition/20170704/20170704.log
2.创建分区表语法
hive (default)> create table dept_partition( deptno int, dname string, loc string ) partitioned by (month string) row format delimited fields terminated by '\t';
3.加载数据到分区表中
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='202009'); hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='202010'); hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='202011');
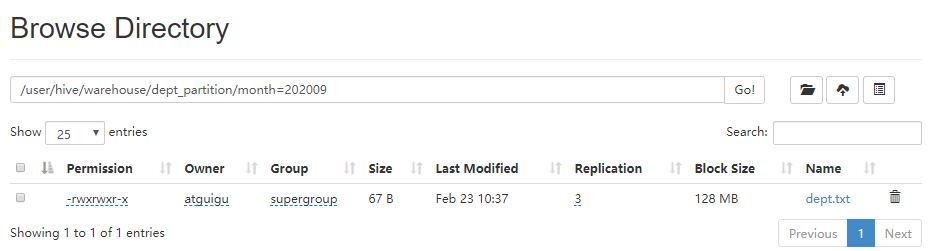
加载数据到分区表
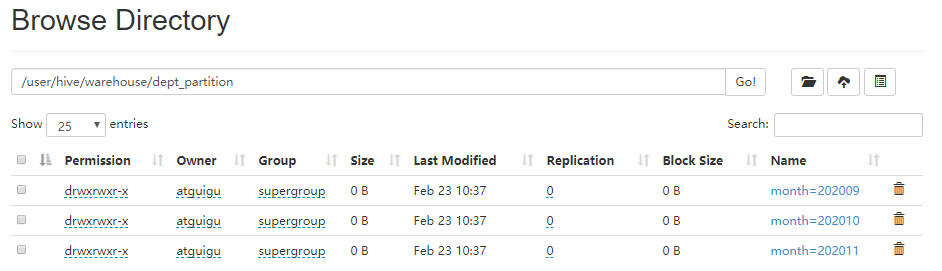
图6-6 分区表
4.查询分区表中数据
单分区查询
hive (default)> select * from dept_partition where month='202009'; OK dept_partition.deptno dept_partition.dname dept_partition.loc dept_partition.month 10 CCOUNTING 1700 202009 20 RESEARCH 1800 202009 30 SALE 1900 202009 40 OPERATIONS 1700 202009 Time taken: 0.116 seconds, Fetched: 4 row(s)
多分区联合查询
hive (default)> select * from dept_partition where month='202009' union select * from dept_partition where month='202010';
_u2.deptno _u2.dname _u2.loc _u2.month
10 CCOUNTING 1700 202009
10 CCOUNTING 1700 202010
20 RESEARCH 1800 202009
20 RESEARCH 1800 202010
30 SALE 1900 202009
30 SALE 1900 202010
40 OPERATIONS 1700 202009
40 OPERATIONS 1700 202010
Time taken: 769.082 seconds, Fetched: 8 row(s)
5.增加分区
创建单个分区
hive (default)> alter table dept_partition add partition(month='202112');
同时创建多个分区
hive (default)> alter table dept_partition add partition(month='202112') partition(month='202101');
如果分区已经存在报错。


hive (default)> alter table dept_partition add partition(month='202112') partition(month='202101'); FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. AlreadyExistsException(message:Partition already exists: Partition(values:[202112], dbName:default, tableName:dept_partition, createTime:0, lastAccessTime:0, sd:StorageDescriptor(cols:[FieldSchema(name:deptno, type:int, comment:null), FieldSchema(name:dname, type:string, comment:null), FieldSchema(name:loc, type:string, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), parameters:null))
6.删除分区
删除单个分区
hive (default)> alter table dept_partition drop partition (month='202112');
同时删除多个分区
hive (default)> alter table dept_partition drop partition (month='202012'), partition (month='202101');
7.查看分区表有多少分区
hive (default)> show partitions dept_partition;
OK
partition
month=202009
month=202010
month=202011
month=202012
month=202101
Time taken: 0.891 seconds, Fetched: 5 row(s)
8.查看分区表结构
hive (default)> desc formatted dept_partition; OK col_name data_type comment # col_name data_type comment deptno int dname string loc string # Partition Information # col_name data_type comment month string # Detailed Table Information Database: default Owner: atguigu CreateTime: Tue Feb 23 10:36:21 CST 2021 LastAccessTime: UNKNOWN Protect Mode: None Retention: 0 Location: hdfs://hadoop102:9000/user/hive/warehouse/dept_partition Table Type: MANAGED_TABLE Table Parameters: transient_lastDdlTime 1614047781 # Storage Information SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe InputFormat: org.apache.hadoop.mapred.TextInputFormat OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat Compressed: No Num Buckets: -1 Bucket Columns: [] Sort Columns: [] Storage Desc Params: field.delim \t serialization.format \t Time taken: 0.379 seconds, Fetched: 34 row(s)
2.2 分区表注意事项
1.创建二级分区表
hive (default)> create table dept_partition2(deptno int, dname string, loc string)
partitioned by (month string, day string)
row format delimited fields terminated by '\t';
2.加载数据
(1)加载数据到二级分区表中
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition2 partition(month='202102',day='23'); Loading data to table default.dept_partition2 partition (month=202102, day=23) Partition default.dept_partition2{month=202102, day=23} stats: [numFiles=1, numRows=0, totalSize=67, rawDataSize=0] OK Time taken: 1.903 seconds
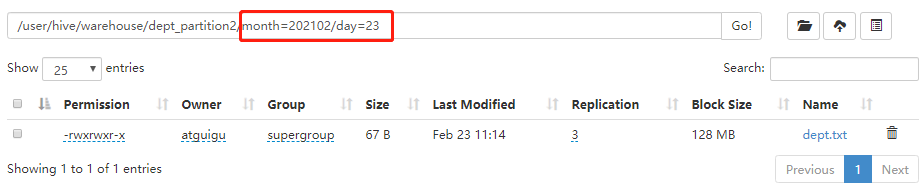
(2)查询分区数据
hive (default)> select * from dept_partition2 where month='202102' and day='23'; OK dept_partition2.deptno dept_partition2.dname dept_partition2.loc dept_partition2.month dept_partition2.day 10 CCOUNTING 1700 202102 23 20 RESEARCH 1800 202102 23 30 SALE 1900 202102 23 40 OPERATIONS 1700 202102 23 Time taken: 1.057 seconds, Fetched: 4 row(s)
3.把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
(1)方式一:上传数据后修复
上传数据
hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=202102/day=22; hive (default)> dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=202102/day=22;
查询数据(查询不到刚上传的数据)
hive (default)> select * from dept_partition2 where month='202102' and day='22'; OK dept_partition2.deptno dept_partition2.dname dept_partition2.loc dept_partition2.month dept_partition2.day Time taken: 0.259 seconds
执行修复命令
hive (default)> msck repair table dept_partition2; OK Partitions not in metastore: dept_partition2:month=202102/day=22 Repair: Added partition to metastore dept_partition2:month=202102/day=22 Time taken: 0.749 seconds, Fetched: 2 row(s)
msck repair table 修复表分区,常用于手动复制目录到hive表的location下,此时Hive元数据中没有记录到该目录是hive的分区,所以查不到该分区数据
再次查询数据
hive (default)> select * from dept_partition2 where month='202102' and day='22'; OK dept_partition2.deptno dept_partition2.dname dept_partition2.loc dept_partition2.month dept_partition2.day 10 CCOUNTING 1700 202102 22 20 RESEARCH 1800 202102 22 30 SALE 1900 202102 22 40 OPERATIONS 1700 202102 22 Time taken: 0.147 seconds, Fetched: 4 row(s)
(2)方式二:上传数据后添加分区
上传数据
hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=202102/day=24; hive (default)> dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=202102/day=24;
执行添加分区
hive (default)> alter table dept_partition2 add partition(month='202102',day='24'); OK Time taken: 0.475 seconds
查询数据
hive (default)> select * from dept_partition2 where month='202102' and day='24'; OK dept_partition2.deptno dept_partition2.dname dept_partition2.loc dept_partition2.month dept_partition2.day 10 CCOUNTING 1700 202102 24 20 RESEARCH 1800 202102 24 30 SALE 1900 202102 24 40 OPERATIONS 1700 202102 24 Time taken: 0.177 seconds, Fetched: 4 row(s)
(3)方式三:创建文件夹后load数据到分区
创建目录
hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=202102/day=19;
上传数据
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table dept_partition2 partition(month='202102',day='19'); Loading data to table default.dept_partition2 partition (month=202102, day=19) Partition default.dept_partition2{month=202102, day=19} stats: [numFiles=1, numRows=0, totalSize=67, rawDataSize=0] OK Time taken: 0.993 seconds
查询数据
hive (default)> select * from dept_partition2 where month='202102' and day='19'; OK dept_partition2.deptno dept_partition2.dname dept_partition2.loc dept_partition2.month dept_partition2.day 10 CCOUNTING 1700 202102 19 20 RESEARCH 1800 202102 19 30 SALE 1900 202102 19 40 OPERATIONS 1700 202102 19 Time taken: 0.176 seconds, Fetched: 4 row(s)
整理atguigu视频

 浙公网安备 33010602011771号
浙公网安备 33010602011771号