
CentOs7下Apache Griffin0.5.0的安装部署
一、Apache Griffin介绍
大数据模块是大数据平台中数据方案的一个功能组件,Griffin(以下简称Griffin)是一个开源的大数据数据解决质量模式,它支持批数据和流数据方式检测质量模式,可以从不同维度(不同标准执行完毕后检查源端和目标端的数据数量是否一致、源表的数据空值数量等)收集数据资产,从而提高数据的准确度、可信度。
在格里芬的架构中,主要分为定义、测量和分析三个部分,如下图所示:
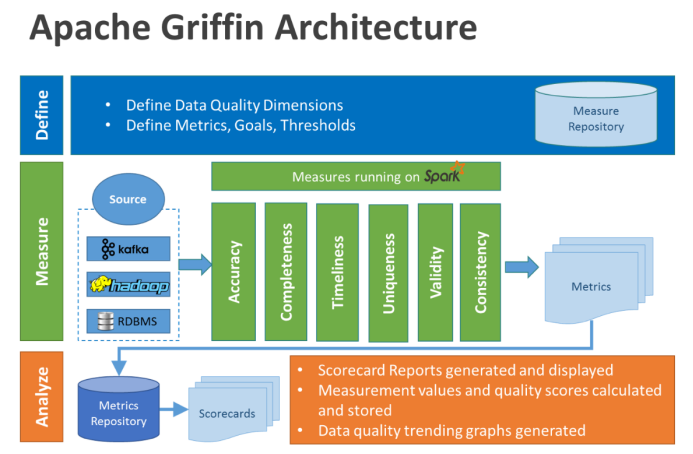
二、Apache Griffin的安装依赖
本文所使用到的Griffin的安装依赖以及版本如下所示:
·Centos7
·JDK-1.8.0
·Mysql-5.7.31
·Hadoop-2.6.5
·Spark-2.3.3
·Scala-2.11.8
·Node-v12.21.0
·Npm-6.14.11
·Apache Hive-2.3.8
·Apache Livy-0.5.0
·Elasticsearch-7.7.1
·Apache Zookeeper-3.5.5
·Apache Kafka-0.8.2
·Apache Maven-3.6.1
·Apache Griffin-0.5.0
其中Apache Zookeeper和Apache Kafka是流模式下才需要安装的。
三、VMware中三台虚拟机的配置信息
|
主机名 |
IP地址 |
内存 |
硬盘 |
CPU |
|
Master |
192.168.152.131 |
2G |
80G |
4 |
|
Slave1 |
192.168.152.132 |
2G |
80G |
4 |
|
Slave2 |
192.168.152.133 |
2G |
80G |
4 |
可以先创建好一台虚拟机,安装好JDK之后再克隆出其它两台。
具体的克隆过程可以参考本人的另一篇博客:https://www.cnblogs.com/zrs123/p/14980840.html
三台虚拟机创建好之后,要进行以下的操作:
- 关闭SELINUX以及防火墙;
- 开启SSH服务;
- 三台虚拟机可以互相ping通,并能ping通外网(例如下面)。
ping -c3 Slave1 ping -c3 www.baidu.com
完成之后基本的实验平台就搭建完毕。
四、其它组件的安装
4.1MySQL数据库的安装
MySQL只需要在Master主机上安装,安装过程详见:https://www.cnblogs.com/zrs123/p/14326737.html
建议离线安装,或者在安装的时候选择自己想要的版本。
4.2Hadoop集群的搭建
参考本人的另一篇博客:https://www.cnblogs.com/zrs123/p/14335162.html
4.3Spark集群的搭建
安装spark之前需要安装好JDK和Scala。
参考本人的另一篇博客:https://www.cnblogs.com/zrs123/p/14366759.html
4.4NodeJS安装
打开官网 https://nodejs.org/en/download/
复制拿到链接,下载nodejs
wget https://nodejs.org/dist/v10.15.3/node-v10.15.3-linux-x64.tar.xz
解压
tar -xvf node-v10.15.3-linux-x64.tar.xz
删除压缩包
rm node-v10.15.3-linux-x64.tar.xz
配置环境变量
编辑
vim /etc/profile
# 新增环境变量
export NODE_HOME=/node-v10.15.3-linux-x64 export PATH=$PATH:$NODE_HOME/bin export NODE_PATH=$NODE_HOME/lib/node_modules
保存
:wq
生效环境变量
source /etc/profile
检查是否安装成功
node -v npm -v
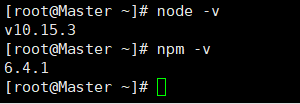
有版本号出现则表示成功
4.5Hive的安装
1、压缩包下载:http://www.apache.org/dyn/closer.cgi/hive/
2、上传压缩包到Master主机的相应目录下,并解压;
3、配置环境变量
export HIVE_HOME=/opt/hive/apache-hive-2.3.8-bin export PATH=$HIVE_HOME/bin:$PATH
生效环境变量
source /etc/profile
4、配置hive元数据库
配置hive元数据库要求用户电脑能够使用mysql。
1)在mysql中创建hive用户,并给予hive用户权限。
create user 'hive' identified by '12345'; grant all privileges on *.* to 'hive'@'%' with grant option; grant all privileges on *.* to hive@Master identified by '12345'; flush privileges;
2)建立hive专用的元数据库
create database hive;
5、修改hive中的配置文件
5.1修改hive-site.xml文件
将hive-default.xml.template文件复制一份并改名为hive-site.xml

在hive-site.xml文件中有如下配置
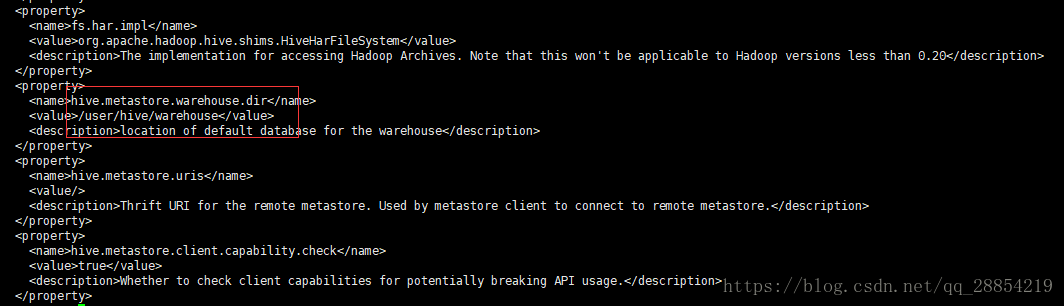
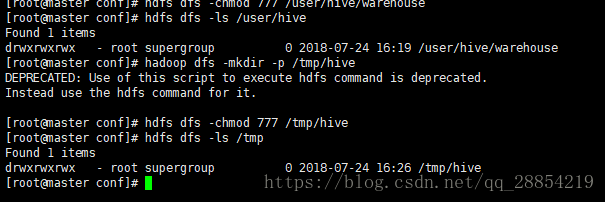
执行hadoop命令"hadoop dfs -mkdir -p /user/hive/warehouse"新建/user/hive/warehouse目录
并给新建的/user/hive/warehouse目录赋予读写权限"hdfs dfs -chmod 777 /user/hive/warehouse"

查看修改后的权限"hdfs dfs -ls /user/hive"

执行hadoop命令"hadoop dfs -mkdir -p /tmp/hive"新建/tmp/hive目录
给/tmp/hive目录赋予读写权限"hdfs dfs -chmod 777 /tmp/hive"
查看创建并授权的目录"hdfs dfs -ls /tmp"
5.2修改hive-site.xml中的临时目录
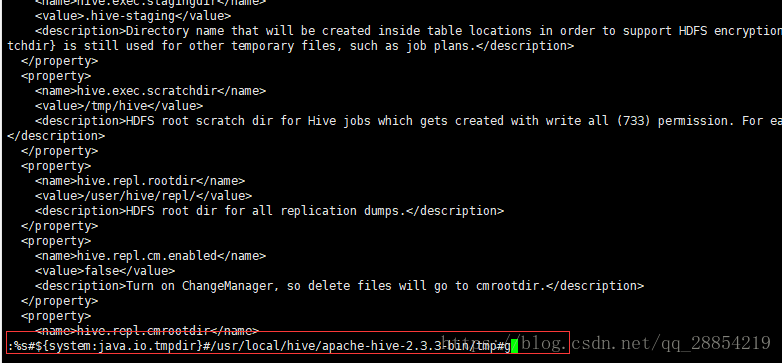
将文件中的所有${system:java.io.tmpdir}替换成/usr/local/hive/tmp
首先在命令行中输入"vi hive-site.xml",然后在命令行中输入”:%s#${system:java.io.tmpdir}#/usr/local/hive/apache-hive-2.3.3-bin/tmp#g“替换所有的临时目录
若没有临时目录,需要先创建,并赋予其读写权限
将文件中所有的${system:user.name}替换成root
6、把mysql的驱动包上传至hive的lib目录下
7、修改hive-site.xml数据库相关配置
修改javax.jdo.option.connectionURL,将name对应的value修改为mysql的地址

修改javax.jdo.option.ConnectionDriverName,将name对应的value修改为mysql驱动类路径

修改javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名

修改javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码
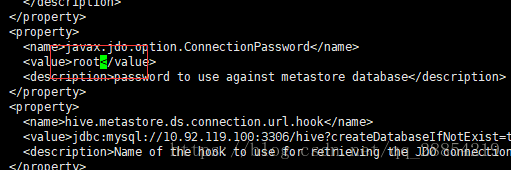
修改hive.metastore.schema.verification,将对应的value修改为false

8、在conf目录下,拷贝hive-env.sh.template存为hive-env.sh

修改hive-env.sh文件
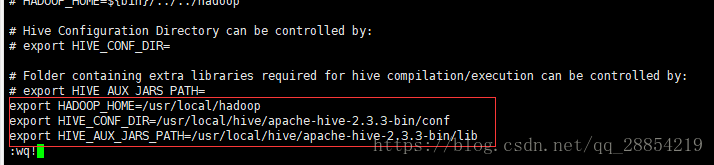
9、启动和测试
1)hive元数据库初始化
schematool -dbType mysql –initSchema
2)出现下图所示情况表明hive安装成功:

参考自博客:https://blog.csdn.net/qq_28854219/article/details/81185610
4.6Livy的安装
1、下载Livy(可以自己下载源代码进行编译)
http://livy.incubator.apache.org/download/
源代码在git 上能够找到apache 版本和cloudera 两个版本
https://github.com/cloudera/livy 有比较详细的说明文档。
2、解压下载好的压缩包到相应的目录下;
3、配置环境变量
vim /etc/profile
export LIVY_HOME=/usr/local/livy/livy-0.5.0-incubating-bin export PATH=$PATH:$LIVY_HOME/bin
执行如下命令生效环境变量
source /etc/profile
4、配置livy-env.sh
export JAVA_HOME=/usr/lib/jvm/java export HADOOP_HOME=/opt/hadoop/hadoop-2.6.5 export SPARK_HOME=/opt/spark/spark-2.3.3-bin-hadoop2.6 export SPARK_CONF_DIR=$SPARK_HOME/conf export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export LIVY_LOG_DIR=/usr/local/livy/livy-0.5.0-incubating-bin/logs export LIVY_SERVER_JAVA_OPTS="-Xmx2g"
/usr/local/livy/livy-0.5.0-incubating-bin/logs需要自己创建。
5、配置livy.conf
livy.environment = production livy.server.host = 192.168.152.131 livy.server.port = 8998 livy.spark.master = yarn livy.spark.deploy-mode = cluster livy.server.session.timeout = 3600000 livy.impersonation.enabled = true livy.server.recovery.mode = recovery livy.server.recovery.state-store = filesystem livy.server.recovery.state-store.url =/usr/local/livy/livy-0.5.0-incubating-bin/tmp livy.spark.deployMode = cluster livy.repl.enable-hive-context = true
6、启动livy
/usr/local/livy/livy-0.5.0-incubating-bin/livy-server start

4.7Elasticsearch集群搭建
1、压缩包下载地址:https://elasticsearch.cn/download/
2、创建普通用户es,因为root用户不能启动elasticsearch集群,并修改权限;
3、将压缩包上传至Master主机相应目录下,并解压;
4、配置环境变量
vim /etc/profile
export ES_HOME=/usr/local/elasticsearch/elasticsearch-7.7.1 export PATH=$PATH:$ES_HOME/bin
执行如下命令生效环境变量
source /etc/profile
5、配置elasticsearch.yml
默认位置位于$ES_HOME/config/elasticsearch.yml
cluster.name: my-application node.name: node-1 path.data: /usr/local/elasticsearch/elasticsearch-7.7.1/data #需要自己创建 path.logs: /usr/local/elasticsearch/elasticsearch-7.7.1/logs #需要自己创建 network.host: 192.168.152.131 http.port: 9200 discovery.seed_hosts:["192.168.152.131", "192.168.152.132","192.168.152.133"] cluster.initial_master_nodes: ["node-1"] http.cors.enabled: true http.cors.allow-origin: "*"
6、/etc/security/limits.conf文件配置
添加如下内容: * soft nofile 65536 * hard nofile 65536
7、sysctl.conf文件配置
在命令行中执行如下命令:
echo “vm.max_map_count=262144” >> /etc/sysctl.conf
8、将安装目录以及环境变量的配置同步至Slave1和Slave2
scp -r ./elasticsearch/ root@Slave1:$PWD scp -r ./elasticsearch/ root@Slave2:$PWD
同步完成后,分别更改Slave1和Slave2的elasticsearch.yml文件,将node.name和network.host修改成本节点的。
9、启动集群
切换至es用户,分别在三台机器的elasticsearch安装目录的bin目录下执行如下命令
bin/elasticsearch -d
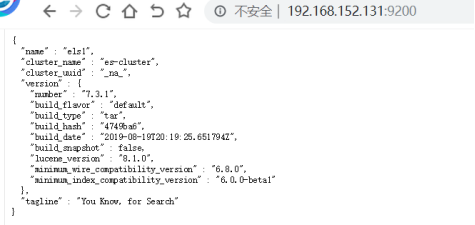

启动成功后,可在浏览器上输入相应的IP和端口号得到上图结果。
4.8Griffin的配置部署
1、Apache Griffin下载地址:https://griffin.apache.org/
上传压缩包到Master主机的相应目录下,并配置环境变量
vim /etc/profile
export GRIFFIN_HOME=/opt/griffin/griffin-0.5.0 export PATH=$PATH:$GRIFFIN_HOME/bin
执行如下命令生效环境变量
source /etc/profile
2、在mysql中创建griffin用户,更改相应的用户名和密码;
如下的命令适用于MySQL5.7,如果安装的是最新的MySQL8.0,则不适用。
create user 'griffin' identified by '12345'; grant all privileges on *.* to 'griffin'@'%' with grant option; grant all privileges on *.* to griffin@Master identified by '12345'; flush privileges;
3、在mysql中创建名为quartz的数据库。由于Griffin 使用了 Quartz 调度器调度任务,需要在mysql中创建 quartz数据库。创建结束后,需要执行指令:mysql -u griffin -p <password> quartz < Init_quartz_mysql_innodb.sql来初始化信息;
4、在Hadoop服务器上创建/home/spark_conf目录,并将Hive的配置文件hive-site.xml上传到该目录下:
hadoop fs -mkdir /home/spark_conf hadoop fs -put $HIVE_HOME/conf/hive-site.xml /home/spark_conf
5、更新livy/conf中的livy.conf文件,在livy.conf文件的末尾追加下列内容,随后启动livy:
livy.spark.deployMode = cluster livy.repl.enable-hive-context = true
6、创建ES索引
curl -k -H "Content-Type: application/json" -X PUT http://cdh2:9200/griffin?include_type_name=true \
-d '{
"aliases": {},
"mappings": {
"accuracy": {
"properties": {
"name": {
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
},
"type": "text"
},
"tmst": {
"type": "date"
}
}
}
},
"settings": {
"index": {
"number_of_replicas": "2",
"number_of_shards": "5"
}
}
}'
7、到/opt/griffin/griffin-0.5.0/service/src/main/resources/目录下修改配置文件
1)application.properties
只展示需要修改的内容:
spring.datasource.url=jdbc:mysql://Master:3306/quartz?autoReconnect=true&useSSL=false spring.datasource.username=griffin spring.datasource.password=12345 spring.datasource.driver-class-name=com.mysql.jdbc.Driver # Hive metastore hive.metastore.uris=thrift://Master:9083 hive.metastore.dbname=hive # Kafka schema registry kafka.schema.registry.url=http://Master:8081 # hdfs default name fs.defaultFS=hdfs://Master:9000 # elasticsearch elasticsearch.host=Master elasticsearch.port=9200 elasticsearch.scheme=http # elasticsearch.user = user # elasticsearch.password = password # livy livy.uri=http://Master:8998/batches livy.need.queue=false livy.task.max.concurrent.count=20 livy.task.submit.interval.second=3 livy.task.appId.retry.count=3 # yarn url yarn.uri=http://Master:8088
2)quartz.properties
需要修改一些内容:
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
3)env_batch.json
“api”: “http://Master:9200/griffin/accuracy”
8、然后进入到/griffin-0.5.0/service/目录,对pom.xml文件进行修改。编辑 service/pom.xml 文件第113行,移除 MySQL JDBC 依赖注释。否则编译griffin时会报错;
9、修改./service/pom.xml和./ui/pom.xml文件中相关组件的版本;
10、启动hive源数据服务。进入到hive的bin目录,执行hive --service metastore &,以启动hive源数据服务;
11、进入到griffin-0.5.0目录中,使用mvn -Dmaven.test.skip=true clean install指令对griffin进行编译打包;
12、编译打包结束后,能在griffin目录下的service和measure目录中出现target目录,在target目录里分别看到service-0.5.0.jar和measure-0.5.0.jar两个包。然后需要将measure-0.5.0.jar这个包改名为griffin-measure.jar(必须更改),然后使用指令: hadoop fs -put griffin-measure.jar /griffin/将griffin-measure.jar上传到hadoop的griffin目录中;
# 重命名measure、service,重命名的jar要和上面的配置文件application.properties 里的name一致 mv measure/target/measure-0.5.0.jar $GRIFFIN_HOME/griffin-measure.jar mv service/target/service-0.5.0.jar $GRIFFIN_HOME/griffin-service.jar # 将measure上传到HDFS hadoop fs -put $GRIFFIN_HOME/griffin-measure.jar /griffin/ #griffin-service.jar 放入Griffin_home
13、启动Griffin后台管理:
#启动Griffin后台管理
nohup java -jar $GRIFFIN_HOME/griffin-service.jar>$GRIFFIN_HOME/service.out 2>&1 &
#启动之后我们可以查看启动日志,如果日志中没有错误,则启动成功
tail -f $GRIFFIN_HOME/service.out
访问192.168.152.131:8082(自己配置的端口)验证是否配置成功。
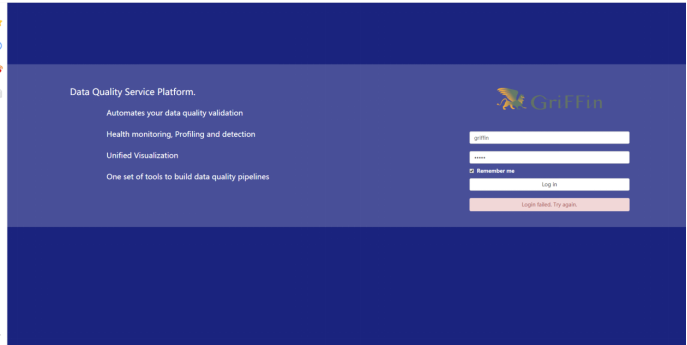
图中的用户名和密码属于上文中在mysql中创建的griffin用户的用户名和密码;
或者账号/密码使用test/test登录。
2021-07-29 12:48:10

