
一步一步微调小模型
本文记录一下,使用自顶向下的编程法一步步编写微调小语言模型的代码。这里小模型指的是可以在本地电脑运行的预训练语言模型(1B左右),相对而言的是需要在大集群运行的模型。
微调一个语言模型,本质上是把一个已经预训练过的语言模型在一个新的数据集上继续训练。那么一次微调模型的任务,可以分为下面三个大个步骤(不包含evaluation):
- 加载已经预训练好的模型和新的数据集
- 预处理模型和数据集
- 开始循环训练
# ======== imports ========
import torch
# ======== config =========
num_epochs = ...
# ========= Load model, tokenizer, dataset =========
model = ...
tokenizer = ...
dataset = ...
# ========= Preprocessing =========
train_dataloader = ...
# ========= Finetuning/Training =========
def compute_loss(X, y): ...
optimizer = ...
scheduler = ...
for epoch in range(num_epochs):
for batch in train_dataloader:
# Training code here
out = model(batch['X'])
loss = compute_loss(out, batch['y'])
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler.step()
torch.save(model.state_dict(), save_path)
本文的目标是微调一个小规模的千问模型Qwen-0.5B,使之具有更强的数学思考能力,使用微软的数据集microsoft/orca-math-word-problems-200k。因此,准备步骤就是导入相应的模块,加载相应的模型和数据集:
# ======== imports ========
import torch
from torch.utils.data import DataLoader
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset, Dataset
# ======== config =========
model_path = 'Qwen/Qwen2-0.5B'
data_path = 'microsoft/orca-math-word-problems-200k'
save_path = './Qwen2-0.5B-math-1'
# ========= Load model, tokenizer, dataset =========
model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
dataset = load_dataset(data_path)
# ========= Preprocessing =========
train_dataloader = ...
# ========= Finetuning =========
def compute_loss(X, y): ...
optimizer = ...
scheduler = ...
for epoch in range(num_epochs):
for batch in train_dataloader:
# Training code here
out = model(batch['X'])
loss = compute_loss(out, batch['y'])
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler.step()
torch.save(model.state_dict(), save_path)
优化器和调度器也按照惯例,使用Adam(或者SGD)和Cosine
# ========= Finetuning =========
from transformers import get_cosine_schedule_with_warmup
def compute_loss(X, y): ...
optimizer = torch.optim.Adam(model.parameters(), lr=2e-4, betas=(0.9,0.99), eps=1e-5)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_training_steps=100, num_warmup_steps=10)
for epoch in range(num_epochs):
for batch in train_dataloader:
# Training code here
out = model(batch['X'])
loss = compute_loss(out, batch['y'])
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler.step()
torch.save(model.state_dict(), save_path)
现在我们聚焦于怎么预处理数据,也就是获得train_dataloader
# ======== config =========
num_epochs = 5 # 量力而行
batch_size = 8 # 量力而行
# ========= Preprocessing =========
train_dataloader = DataLoader(dataset, batch_size=batch_size)
Qwen模型和GPT类似,都是根据一串token输入,预测下一个token。所以在训练中的X就应该是一串token,y则是一个token。但实际上,Qwen以及Huggingface的其他AutoModelForCausalLM的输出不止是一个token,而是一串token。准确来说AutoModelForCausalLM输出的logits是一个的型为(batch_size, sequence_length, config.vocab_size)三维张量。因为模型会把输入x中的每一个x[0:i]子串都当作输入来预测一下,所以相应的y也应当调整为每一个x[0:i]子串的后一个token
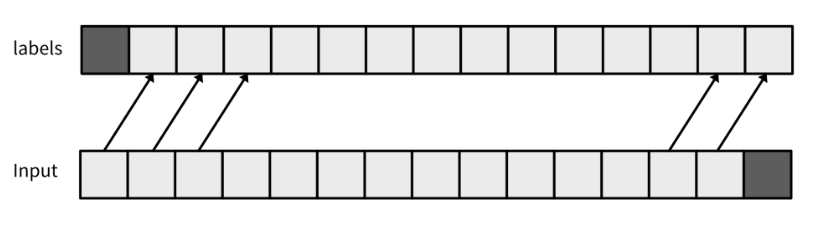
那么,train_dataloader里面的每个batch的X和y都是token,且基本上y可以看作x左移了一位,而y[-1]则是x这个输入序列的真实预测值
x, y = x[0:-1], x[1:len(x)]
现在的任务就是把数据集变换成我们想要的模样。考察数据集,发现每个样本有两个序列
>>> print(dataset)
DatasetDict({
train: Dataset({
features: ['question', 'answer'],
num_rows: 200035
})
})
我们使用Qwen的tokenizer提供的方法,把这两个序列合并成一个x:
from transformers import default_data_collator
def ds_generator():
for item in ds['train']:
messages = [
{"role": "user", "content": item['question']},
{"role": "system", "content": item['answer']}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt", padding='max_length', truncation=True)
yield {
'x': model_inputs['input_ids'][0][:-1],
'y': model_inputs['input_ids'][0][1:]
}
dataset = Dataset.map(ds_generator)
train_dataloader = DataLoader(new_ds, batch_size=batch_size, collate_fn=default_data_collator)
我们这里只考虑语言模型,所以模型常规的输出应该是logits,则compute_loss则是计算模型输出与真实label之间的交叉熵。
def compute_loss(X, y):
'''
X: (batch_size, seq_len, vocab_size)
y: (batch_size, seq_len)
'''
return torch.nn.functional.cross_entropy(X.view(-1, X.shape[-1]), y.view(-1))
(其实Qwen模型如果在喂输入x时同时把y喂进去,那么返回值就包含了loss:loss = model(x, y).loss)
完整的微调代码如下
'''
A step-by-step guide to fine-tune an LM.
Environment:
# Name Version Build Channel
python 3.12.4 h5148396_1
pytorch 2.4.0 py3.12_cuda12.4_cudnn9.1.0_0 pytorch
cuda-runtime 12.4.0 0 nvidia
transformers 4.43.3 pypi_0 pypi
'''
from types import SimpleNamespace
import torch
from torch.utils.data import DataLoader
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import default_data_collator, get_cosine_schedule_with_warmup
from datasets import load_dataset, Dataset
model_path = 'Qwen/Qwen2-0.5B'
data_path = 'microsoft/orca-math-word-problems-200k'
save_path = './Qwen2-0.5B-math-1'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
config = SimpleNamespace(
batch_size=8,
epochs=5,
eps=1e-5,
lr=2e-4,
model_max_length=2048
)
model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, padding_side="right", model_max_length=config.model_max_length)
dataset = load_dataset(data_path)
def ds_generator():
for item in ds['train']:
messages = [
{"role": "user", "content": item['question']},
{"role": "system", "content": item['answer']}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt", padding='max_length', truncation=True)
yield {
'x': model_inputs['input_ids'][0][:-1],
'y': model_inputs['input_ids'][0][1:]
}
dataset = Dataset.map(ds_generator)
train_dataloader = DataLoader(dataset, batch_size=config.batch_size, collate_fn=default_data_collator)
def compute_loss(y_pred, y_true):
'''
y_pred: (batch_size, seq_len, vocab_size)
y_true: (batch_size, seq_len)
'''
return torch.nn.functional.cross_entropy(y_pred.view(-1, X.shape[-1]), y_true.view(-1))
optimizer = torch.optim.Adam(model.parameters(), lr=config.lr, betas=(0.9,0.99), eps=config.eps)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_training_steps=100, num_warmup_steps=10)
for epoch in range(num_epochs):
for batch in train_dataloader:
# Training code here
out = model(batch['x'])
loss = compute_loss(out.logits, batch['y'])
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler.step()
torch.save(model.state_dict(), save_path)
