js加密(四)landChina
1. url:https://www.landchina.com/default.aspx?tabid=226
2. target:
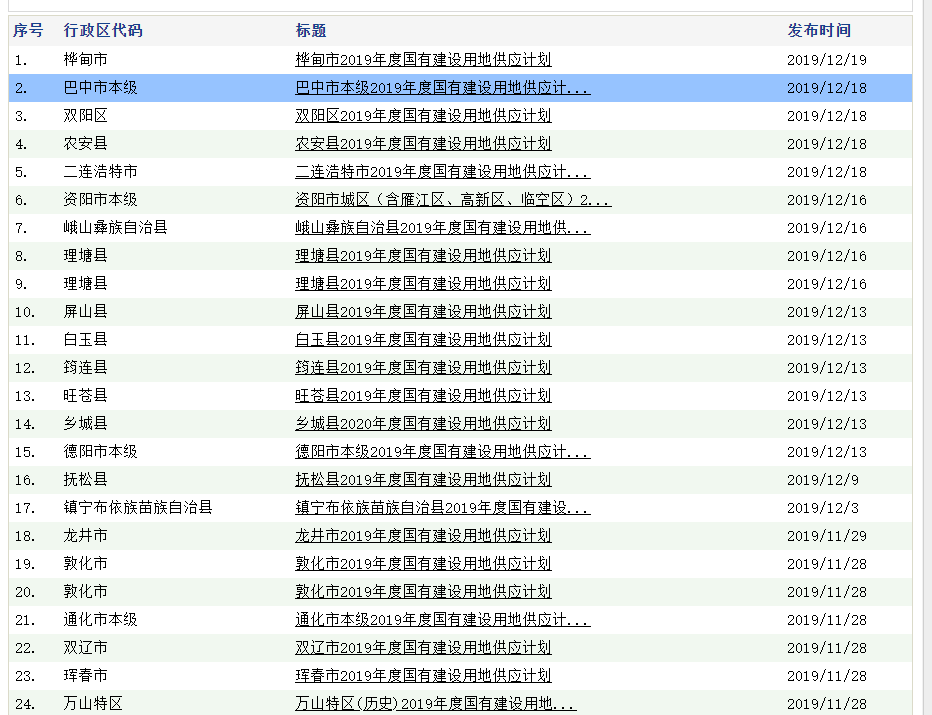
3. 简单分析
3.1 打开fiddler和chorme无痕浏览器,访问目标网站,看看都加载了哪些请求。
可以看到,一共请求了3次,才获得最终我们想要的数据。
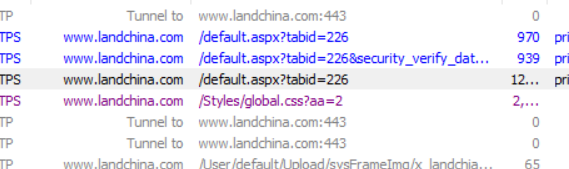
3.2 请求1:
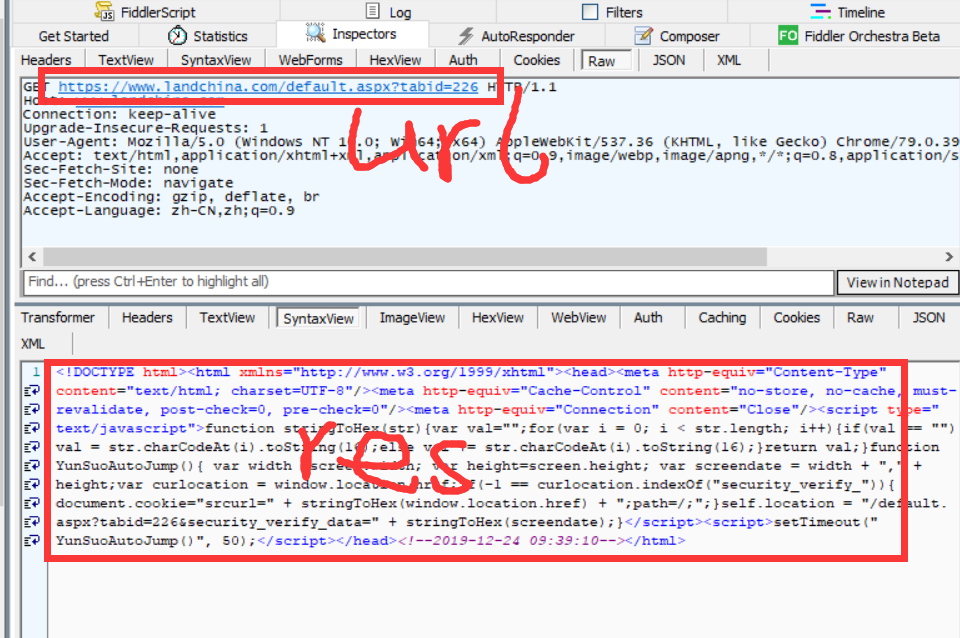
url就是网站url,响应是一堆js。将js扣出来执行一下,发现是这么一个东西:

我们再看看第二个请求的url:

这不就是第二个请求的url嘛。
3.2 请求2,请求3的cookie是一样的。所以我们用requests库中的session来访问第一步生成的url和目标url。完整代码如下:
python:
import requests from afterWork.config import proxies, userAgent import execjs import re targetUrl = 'http://www.landchina.com/default.aspx?tabid=226' sess = requests.session() res = sess.get(targetUrl) with open('jsCode.js', 'r') as f: jsCode = f.read() ctx = execjs.compile(jsCode) location = ctx.call('YunSuoAutoJump') # print(location) second_url = "http://www.landchina.com" + location _ = sess.get(second_url) res = sess.get(targetUrl) # print(res.text) regForInfo = r'<td class="gridTdNumber">(.*?)<td class="gridTdNumber">' infoList = re.findall(regForInfo, res.text) # print(infoList) for info in infoList: print(info)
初步提取结果:

只有单序号没有双序号,下了一跳,还以为反爬这么严,单双号分开反爬。看了眼网页源码才知道没问题。匹配下就出来了。
学习研究,勿作他用。js代码很简单,没有拿过来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号