js反爬学习(一)谷歌镜像
1. url:https://ac.scmor.com/
2. target:如下链接
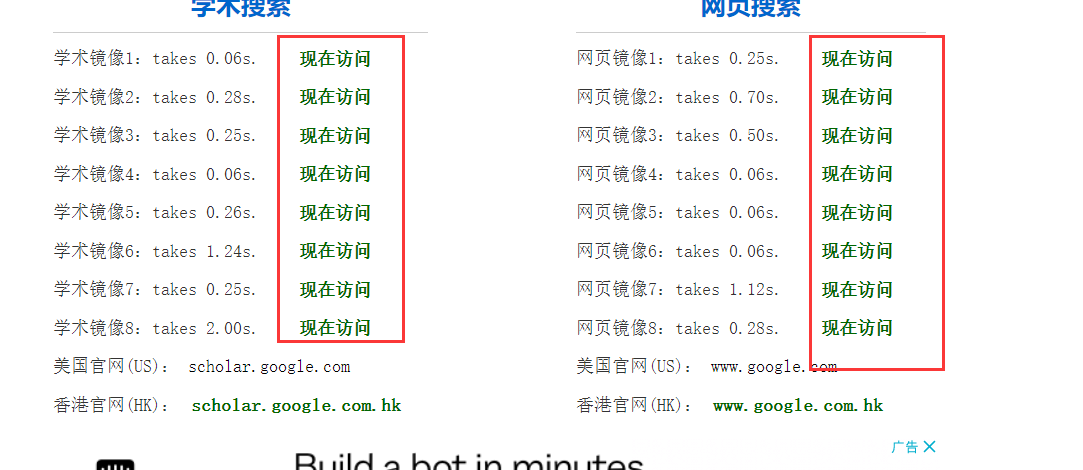
3. 过程分析:
3.1 打开chrome调试,进行元素分析。随便定位一个“现在访问”

3.2 链接不是直接挂在源码里,而是调用一个名为“visit”的js函数。下一步去找这个函数。
3.3 对资源全局搜索,找到visit函数:
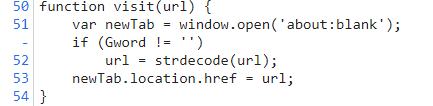
3.4 看到它还调用了一个strdecode函数,再去找:

3.5 看到它还调用了一个base64decode函数,接着找:
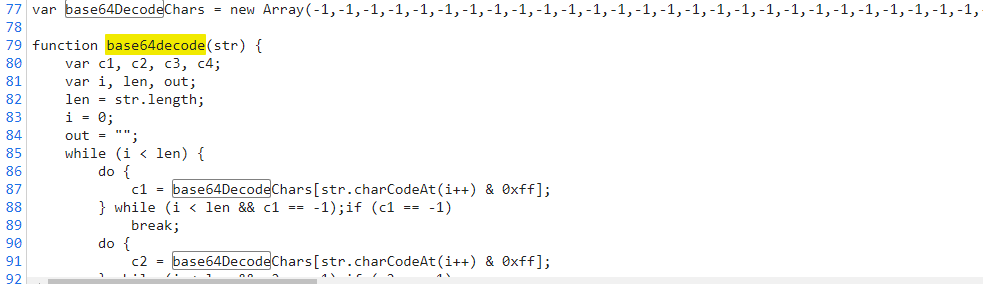
上面的变量也是需要的。
3.6 接下来,把所有用到的js代码放到一个js文件中去,稍微重构一下js代码。
js代码如下:
//var url = strdecode(url); var Gword = "author: link@scmor.com."; var hn = 'ac.scmor.com' function strdecode(string) { string = base64decode(string); key = Gword + hn; len = key.length; code = ''; for (i = 0; i < string.length; i++) { var k = i % len; code += String.fromCharCode(string.charCodeAt(i) ^ key.charCodeAt(k)); } return base64decode(code); } function base64decode(str) { var c1, c2, c3, c4; var i, len, out; len = str.length; i = 0; out = ""; while (i < len) { do { c1 = base64DecodeChars[str.charCodeAt(i++) & 0xff]; } while (i < len && c1 == -1);if (c1 == -1) break; do { c2 = base64DecodeChars[str.charCodeAt(i++) & 0xff]; } while (i < len && c2 == -1);if (c2 == -1) break; out += String.fromCharCode((c1 << 2) | ((c2 & 0x30) >> 4)); do { c3 = str.charCodeAt(i++) & 0xff; if (c3 == 61) return out; c3 = base64DecodeChars[c3]; } while (i < len && c3 == -1);if (c3 == -1) break; out += String.fromCharCode(((c2 & 0XF) << 4) | ((c3 & 0x3C) >> 2)); do { c4 = str.charCodeAt(i++) & 0xff; if (c4 == 61) return out; c4 = base64DecodeChars[c4]; } while (i < len && c4 == -1);if (c4 == -1) break; out += String.fromCharCode(((c3 & 0x03) << 6) | c4); } return out; } var base64DecodeChars = new Array(-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,62,-1,-1,-1,63,52,53,54,55,56,57,58,59,60,61,-1,-1,-1,-1,-1,-1,-1,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,-1,-1,-1,-1,-1,-1,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,-1,-1,-1,-1,-1);
其中有两个变量需要在网页源码中去寻找,Gword和hn,找到之后在js代码中定义变量即可,如上。
3.7 下面用execjs执行js,通过js获取“现在访问”的链接。完整代码如下:
import execjs def getJs(): jsStr = '' with open('jsCode.js', 'r') as f: s = f.readline() while s: jsStr += s s = f.readline() # print(jsStr) return jsStr if __name__ == '__main__': jsStr = getJs() ctx = execjs.compile(jsStr) visitParam = 'AD0mWAw6dxYgEFdYJEAAGCA2bFcLOngbAmYmFjRdS1ovGFBc' url = ctx.call('strdecode', visitParam) print(url)
作为一个爬虫工作者,我的js真的是弱爆了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号