

Python-Matplotlib、Seaborn、Plotly
Catalog:Click to jump to the corresponding position
=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=
plt.plot(x,y,ls=,lw=,c=,marker=,markersize=,markeredgecolor=,markerfacecolor, label=)
x:x轴上的数值
y: y轴上的数值
ls:折线的风格
lw:线条宽度
c:颜色
marker:线条上点的形状
markersize:线条上点的形状的大小
markeredgecolor:点的边框色
markerfacecolor:点的填充色
label:图例的标签
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.linspace(0,20,10)
y = np.sin(x)
plt.plot(x,y,c='red',lw=3,ls='--',marker='o',markersize=10,markeredgecolor='blue',markerfacecolor='black',label='Y=Sin(X)')
plt.show()
绘图的其他参数:
设置画布的代码参数 plt.figure(figsize=,dpi=,facecolor=) figsize表示画布的长宽,dpi表示分辨率,facecolor表示画布边框的颜色,画布的设置一定要在画图之前
图片的标题 plt.title(string,color=,size=,loc=)
X轴的标签 plt.xlabel()
Y轴的标签 plt.ylabel()
确定X轴范围 plt.xlim()
确定Y轴范围 plt.ylim()
确定X轴的标签刻度 plt.xticks()
确定Y轴的标签刻度 plt.yticks()
plt.plot(x,y,c='red',lw=3,ls='--',marker='o',markersize=10,markeredgecolor='blue',markerfacecolor='black',label='Y=Sin(X)')
展示图例:loc参数表示图例的位置(upper、lower、left、right、center),fontsize表示字体大小,frameon表示是否有边框
plt.legend(loc='best',fontsize=10,frameon=True) #图例就是plt.plot代码里label定义的内容
保存图片 plt.savefig(r'F:\data\case_picture.png') #一定要在show代码前
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决图例显示乱码问题
plt.rcParams['axes.unicode_minus']=False #解决某些标点符号显示问题
x = np.linspace(0,20,10)
y = np.sin(x)
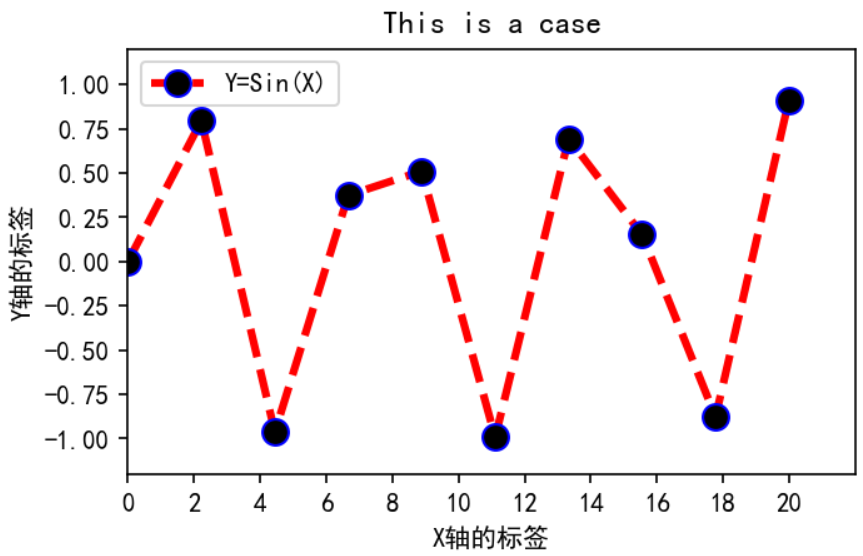
plt.figure(figsize=(5,3),dpi=150,facecolor='white')
plt.title('This is a case')
plt.xlabel('X轴的标签')
plt.ylabel('Y轴的标签')
plt.xlim([0,22])#确定X轴范围
plt.ylim([-1.2,1.2])#确定Y轴范围
plt.xticks([i*2 for i in range(0,11)])#确定X轴的标签刻度
plt.yticks([-1,-0.75,-0.5,-0.25,-0.00,0.25,0.5,0.75,1.00]) #确定Y轴的标签刻度
plt.plot(x,y,c='red',lw=3,ls='--',marker='o',markersize=10,markeredgecolor='blue',markerfacecolor='black',label='Y=Sin(X)')
plt.legend(loc='best') #展示图例,loc参数表示图例的位置
plt.savefig(r'F:\data\case_picture.png')
plt.show()
线条风格:"-"、"--"、"-."、":"
填充形状:"."、","、"o"、"v"、"^"、"<"、">"、"1"、"2"、"3"、"4"、"s"、"p"、"*"、"h"、"H"、"+"、"x"、"D"、"d"、"|"、"_"
折线图是将数据点按照顺序连接起来的图形,可以认为主要作用是查看y随着x改变的趋势,非常适合时间序列分析
import pandas as pd
import matplotlib.pyplot as plt
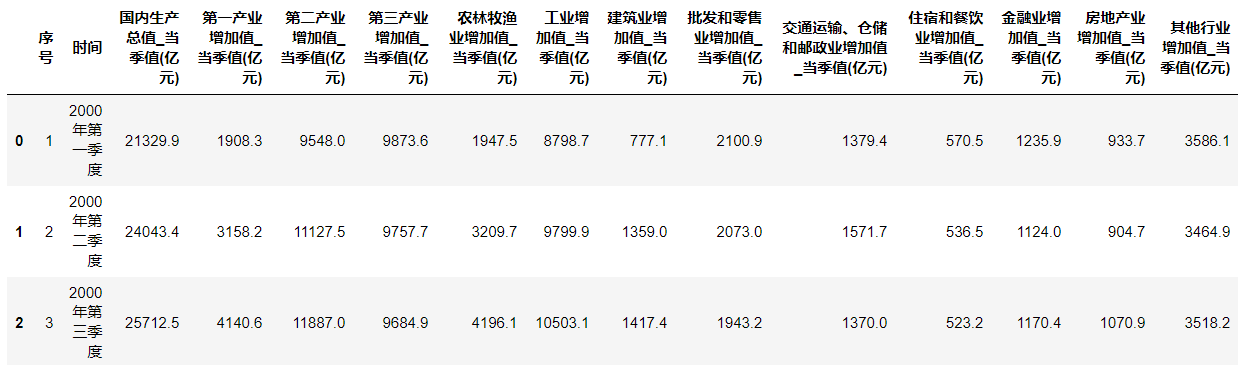
data = pd.read_excel(r'F:\data\国民经济核算季度数据.xlsx')
data.head(3)
输出结果:
plt.rcParams['font.sans-serif']=['SimHei']
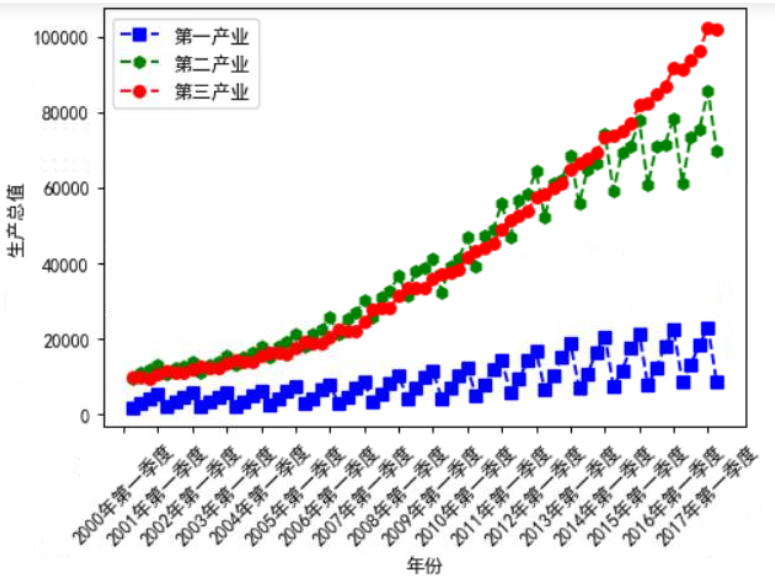
plt.figure(dpi=90)
plt.plot(data.iloc[:,0], data.iloc[:,3],'bs--',
data.iloc[:,0],data.iloc[:,4],'gh--',
data.iloc[:,0],data.iloc[:,5],'ro--')
plt.xlabel('年份',fontsize=10)
plt.ylabel('生产总值',fontsize=10)
plt.xticks(range(0,70,4), data.iloc[range(0,70,4),1], rotation=45,fontsize=10)
plt.legend(['第一产业’,’第二产业','第三产业'])
plt.show()
输出结果:
饼图用于实现可视化离散型变量的分布的一种图形
plt.pie(x,explode,labels,colors,autopct=,pctdistance,shadow,startangle,radius,wedgeprops,textprops,center)
--explode:突出显示
--labels:标签
--colors:颜色
--autopct:百分比
--pctdistance:百分比标签与圆心距离
--shadow:是否添加饼图阴影效果
--labeldistance:设置各扇形标签与圆心距离
--startangle:设置饼图的初始摆放角度
--radius:设置饼图半径大小
--wedgeprops:设置饼图内外边界的属性
--textprops:设置饼图中文本属性
--center:设置中心位置
--counterclock:是否逆时针呈现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决图例显示乱码问题
plt.rcParams['axes.unicode_minus']=False #解决某些标点符号显示问题
data = [10,20,40,15,35]
area_name = ['橘子','苹果','香蕉','猕猴桃','雪梨']
plt.figure(dpi=90)
plt.pie(x=data,explode=[0,0.1,0,0,0.1],labels=area_name,colors=['red','green','blue','yellow','purple'],autopct='%.1f%%',\
pctdistance=0.6,labeldistance=1.1,radius=1.5,counterclock=False,\
wedgeprops={'linewidth':1.5,'edgecolor':'black'},\
textprops={'fontsize':15,'color':'black'},startangle=90)
plt.title('水果销量占比图',pad=30,size=20)
plt.axis('equal')
plt.show()
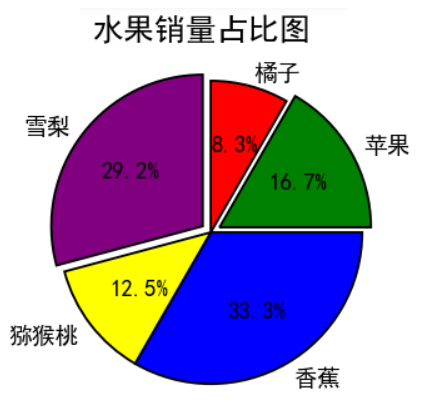
注意:plt.axis('equal') 用于将饼图显示为正圆
plt.bar(x, height,width,bottom,color,linewidth,tick_label,align)
x:指定x轴上数值
height:指定y轴上数值
width:指定条形图宽度
color:条形图的填充色
edgecolor:条形图的边框色
linewidth:条形图边框宽度
tick_label:条形图的刻度标签
align:指定x轴上对齐方式
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决图例显示乱码问题
plt.rcParams['axes.unicode_minus']=False #解决某些标点符号显示问题
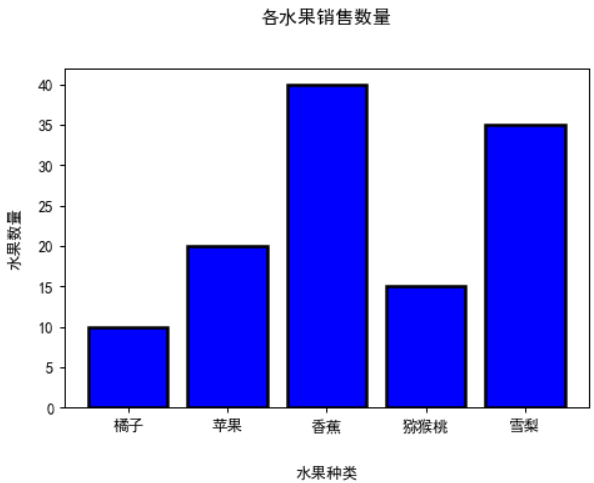
data = [10,20,40,15,35]
area_name = ['橘子','苹果','香蕉','猕猴桃','雪梨']
plt.figure(dpi=90)
plt.bar(x=area_name,height=data,color='blue',edgecolor='black',linewidth=2,align='center')
plt.xlabel('水果种类',labelpad=20)
plt.ylabel('水果数量',labelpad=10)
plt.title('各水果销售数量',pad=30)
plt.show()
对于连续型变量,往往需要查看其分布图,直方图就是用来观察数据的分布形态
直方图,一般用来观察数据的分布形态,横坐标代表数值的分段,纵坐标代表了观测数量和频数,
直方图有时候会和核密度图搭配使用,主要是为了更加详细的展示数据的分布特征
plt.hist(x,bins,range,normed,cumulative,bottom,align,rwidth,color,edgecolor,label)
x:数据
bin:条形个数
range:上下界
normed:是否将频数转换成频率
cumulative:是否计算累计频率
bottom:为直方图的每个条形添加基准线,默认为0
align:对齐方式
rwidth:条形的宽度
color:填充色
edgecolor:设置直方图边框色
label:设置直方图标签
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
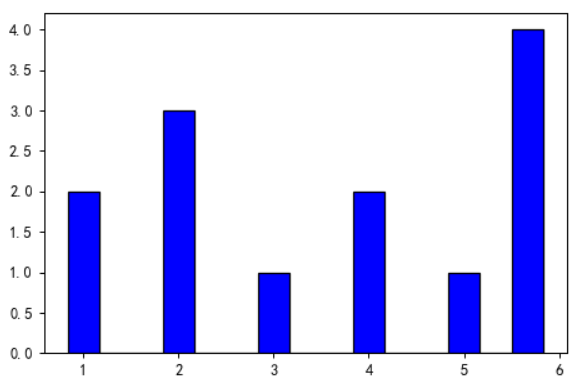
data = [1,1,2,2,2,3,4,4,5,6,6,6,6]
plt.rcParams['font.sans-serif']=['SimHei'] #解决图例显示乱码问题
plt.rcParams['axes.unicode_minus']=False #解决某些标点符号显示问题
plt.figure(dpi=90)
plt.hist(x=data,bins=15,align='left',color='blue',edgecolor='black')
plt.show()
直方图与核密度图、正态分布曲线的搭配使用:
import numpy as np
import pandas as pd
import matplotlib. pyplot as plt
data=pd.read_csv(r'F:\data\titanic_train.csv',sep=',')
data.dropna(subset=['Age'],inplace=True)
data.head ()
输出结果:

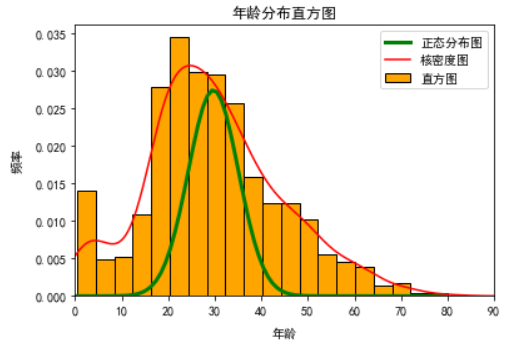
import numpy as np import pandas as pd import matplotlib. pyplot as plt data=pd.read_csv(r'F:\data\titanic_train.csv',sep=',') data.dropna(subset=['Age'],inplace=True) def normfun(x, mu,sigma): #正态分布函数 pdf=np.exp(-((x-mu)**2)/(2*sigma*2))/(sigma*np.sqrt(2*np.pi)) return pdf mean_x = data.Age.mean() std_x = data.Age.std() x = np.arange(data.Age.min(),data.Age.max(),1) y=normfun(x,mean_x,std_x) plt.rcParams['font.sans-serif']=['SimHei'] plt.hist(x=data.Age,bins=20,color='orange',edgecolor='black', density=True,label='直方图') plt.plot(x,y,color='green',linewidth=3,label='正态分布图') data.Age.plot(kind='kde',color='red',xlim=[0,90],label='核密度图') plt.xlabel('年龄',fontsize=10,labelpad=10) plt.ylabel('频率',fontsize=10,labelpad=10) plt.title('年龄分布直方图') plt.legend(loc='best') plt.show()
输出结果:
散点图一般用来展示2个连续型变量的关系,可以通过散点图来判断两个变量之间是否存在某种关系,
例如线性还是非线性关系
plt.scatter(x,y,s,c,marker,cmap,norm,alpha,linewidths,edgecolor)
x:x数据
y:y轴数据
s:散点大小
c:散点颜色
marker:散点图形状
cmap:指定某个colormap值,该参数一般不用,用默认值
alpha:散点的透明度
linewidths:散点边界线的宽度
edgecolor:设置散点边界线的颜色
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_excel(r'F:\data\散点图.xlsx')
x_data=data['电话次数']
y_data=data['销售额']
plt.rcParams['font.sans-serif']=['SimHei'] #解决图例显示乱码问题
plt.rcParams['axes.unicode_minus']=False #解决某些标点符号显示问题
plt.figure(dpi=90)
plt.scatter(x=x_data,y=y_data,s=80,c='blue',marker='o',linewidths=1,edgecolor='black')
plt.xlabel('电话次数',labelpad=10,size=10)
plt.ylabel('销售额',labelpad=10,size=10)
plt.title('电话次数与销售额关系',pad=20,size=20)
plt.show()
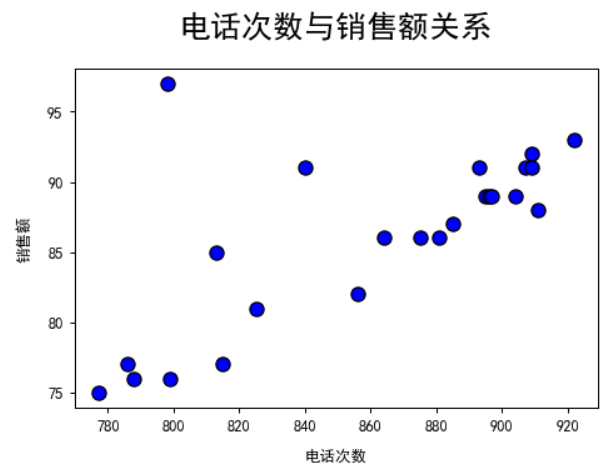
不同种类下的散点图:
import pandas as pd
import matplotlib.pyplot as plt
import os
os.chdir('C: \datal第四章')
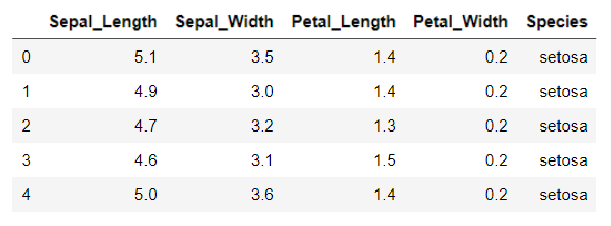
data = pd.read_csv('iris.csv')
data.head()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
os.chdir('C: \datal第四章')
data = pd.read_csv('iris.csv')
data.head()
plt.rcParams['font.sans-serif']=['SimHei']
kind=['setosa','versicolor','virginica']
color_kind=['red','blue','green']
marker_kind=['o','x','v']
plt.figure(dpi=100)
for i in range(0, 3):
plt.scatter(x=data['Petal_Width'][data['Species']==kind[i]],\
y=data['Petal_Length'][data['Species']==kind[i]],\
color=color_kind[i],marker=marker_kind[i],\
label=kind[i])
plt.legend(loc='best')
plt.xlabel('花瓣长度',fontsize=10)
plt.ylabel('花瓣宽度',fontsize=10)
plt.show ()

数据源:
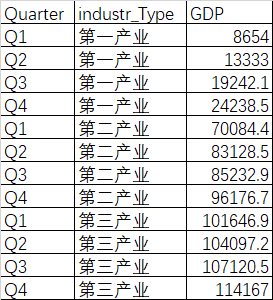
将数据源使用透视图进行数据整理:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_excel(r'F:\data\各产业季度产值.xlsx')
data=pd.pivot_table(data=data,index='Quarter',values='GDP',columns='industr_Type',aggfunc=np.sum)
data
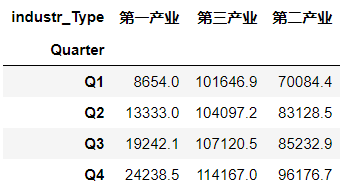
创建各产业对应的四季度条形图:
#需要画出三张图,第一产业四季度的条形图、第二产业四季度的条形图、第三产业四季度的条形图,然后将三张图堆叠起来
plt.bar(x=data.index.values,height=data['第一产业'],color='red',label='第一产业',tick_label=['第一季度','第二季度','第三季度','第四季度'])
plt.bar(x=data.index.values,height=data['第二产业'],color='blue',label='第二产业',tick_label=['第一季度','第二季度','第三季度','第四季度'])
plt.bar(x=data.index.values,height=data['第三产业'],color='green',label='第三产业',tick_label=['第一季度','第二季度','第三季度','第四季度'])
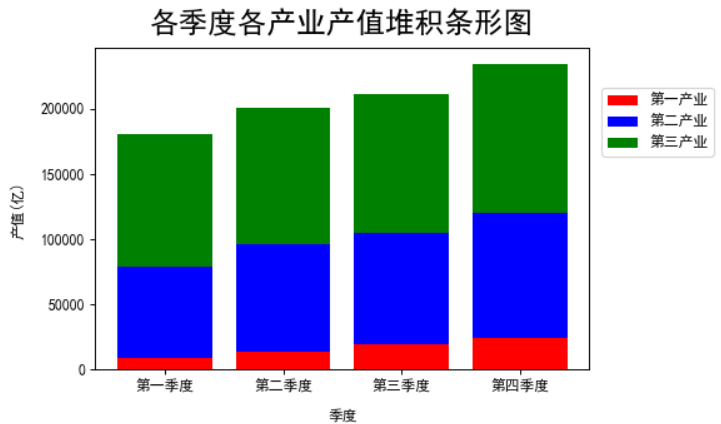
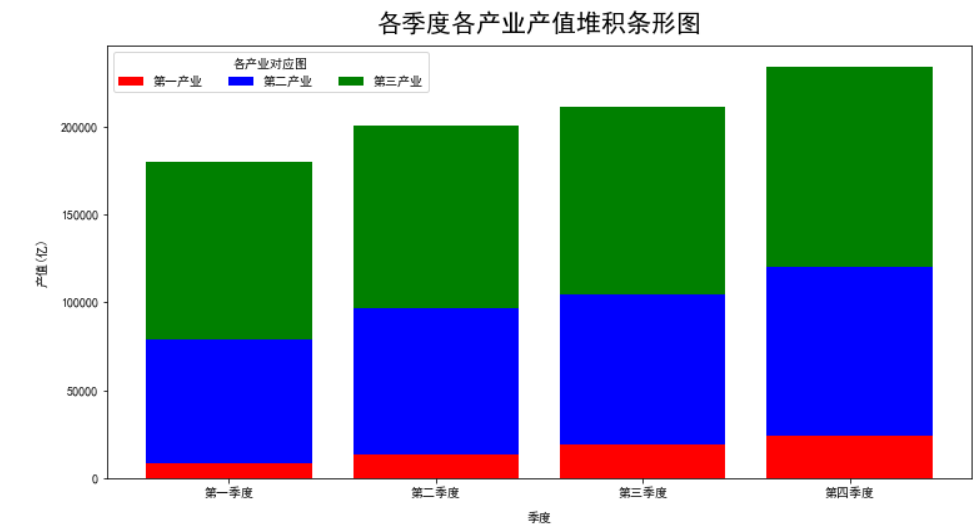
使用bottom参数进行三张图的堆叠(使用bottom参数):
plt.figure(dpi=85)
plt.bar(x=data.index.values,height=data['第一产业'],color='red',label='第一产业',tick_label=['第一季度','第二季度','第三季度','第四季度'])
plt.bar(x=data.index.values,height=data['第二产业'],color='blue',label='第二产业',tick_label=['第一季度','第二季度','第三季度','第四季度'],\
bottom=data['第一产业']) #这里的bottom可以表示第二幅图是画在第一幅图上面的,即把第一幅图用于画图的数据踩下去
plt.bar(x=data.index.values,height=data['第三产业'],color='green',label='第三产业',tick_label=['第一季度','第二季度','第三季度','第四季度'],\
bottom=data['第一产业']+data['第二产业'])#这里的bottom可以表示第三幅图是画在第一幅图和第二幅图上面的,即把第一幅图用于画图的数据和第二幅图用于画图的数据踩下去
plt.legend(bbox_to_anchor=(1.01,0.90),fontsize=10,frameon=True)
plt.xlabel('季度',size=10,labelpad=10)
plt.ylabel('产值(亿)',size=10,labelpad=10)
plt.title('各季度各产业产值堆积条形图',size=20,pad=10)
plt.show()
箱线图是由一个箱体和一对箱须组成的统计图形。箱体是由第一四分位数,中位数和第三四分位数所组成的。
在箱须的末端之外的数值可以理解成离群值,箱线图可以对一组数据范围大致进行直观的描述
plt.boxplot(x,notch,sym,vert,whis,positions,widths,patch_artist,meanline,showmeans,boxprops,labels,flierprops)
x:数据
width:宽度
patch_artist:是否填充箱体颜色
meanline:是否显示均值
showmeans:是否显示均值
showfliers:是否表示有异常值
Meanprops:设置均值属性,如点的大小,颜色等
medianprops:设置中位数的属性,如线的类型,大小等
boxprops:设置箱体的属性,边框色和填充色
flierprops:设置异常值的属性
cappops:设置箱线顶端和末端线条的属性,如颜色,粗细等
import numpy as np
import pandas as pd
import matplotlib. pyplot as plt
data = pd.read_excel(r'F:\data\sec_buildings.xlsx')
plt.figure(figsize=(7,4),dpi=90)
plt.boxplot(x=data['price_unit'],patch_artist=True,showmeans=True,showfliers=True,\
boxprops={'color':'black','facecolor':'steelblue'},\
flierprops={'markerfacecolor':'red','markersize':10},\
meanprops={'marker':'D','markerfacecolor':'indianred','markersize':10},\
medianprops={'linestyle':'--','color':'red'})
plt.title('二手房价格箱线图')
plt.show()
输出结果:

图例参数:
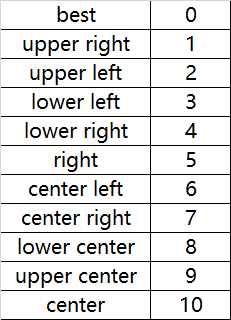
loc参数表示图例的位置(upper、lower、left、right、center),
fontsize表示字体大小
frameon表示是否有边框、
ncol表示图例的排列列数
title表示标题
shadow:shadow线框是否添加阴影
fancybox:线框的圆角还是直角
#图例就是画图代码里label定义的内容
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_excel(r'F:\data\各产业季度产值.xlsx')
plt.rcParams['font.sans-serif']=['SimHei']
data=pd.pivot_table(data=data,index='Quarter',values='GDP',columns='industr_Type',aggfunc=np.sum)
plt.figure(dpi=90)
plt.bar(x=data.index.values,height=data['第一产业'],color='red',label='第一产业',tick_label=['第一季度','第二季度','第三季度','第四季度'])
plt.bar(x=data.index.values,height=data['第二产业'],color='blue',label='第二产业',tick_label=['第一季度','第二季度','第三季度','第四季度'],\
bottom=data['第一产业'])
plt.bar(x=data.index.values,height=data['第三产业'],color='green',label='第三产业',tick_label=['第一季度','第二季度','第三季度','第四季度'],\
bottom=data['第一产业']+data['第二产业'])
plt.legend(title='各产业对应图',ncol=3,loc=2,fancybox=True,fontsize=10,frameon=True)
plt.xlabel('季度',size=10,labelpad=10)
plt.ylabel('产值(亿)',size=10,labelpad=10)
plt.title('各季度各产业产值堆积条形图',size=20,pad=10)
plt.show()

loc对应数字的含义:
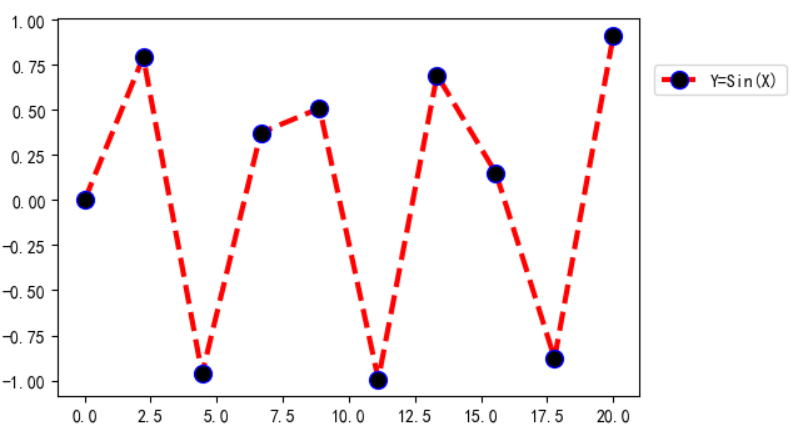
图例在图片外显示:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.linspace(0,20,10)
y = np.sin(x)
plt.plot(x,y,c='red',lw=3,ls='--',marker='o',markersize=10,markeredgecolor='blue',markerfacecolor='black',label='Y=Sin(X)')
plt.legend(bbox_to_anchor=(1.01,0.90),fontsize=10,frameon=True)
plt.show()
bbox_to_anchor=(1.01,0.90)所表示的含义为先将图片大小的长宽都看为1,然后将图例放在长为1.01,高为0.9的位置,因为1.01超过了1.0,所以图例显示在了外面
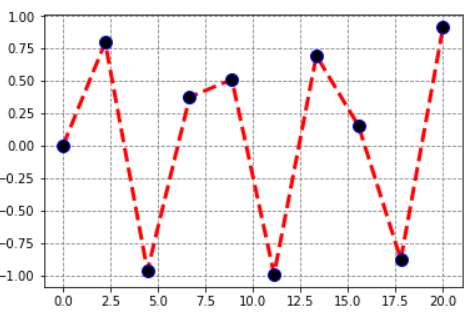
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.linspace(0,20,10)
y = np.sin(x)
fig = plt.gcf()
fig.set_size_inches(8,4)
plt.plot(x,y,c='red',lw=3,ls='--',marker='o',markersize=10,markeredgecolor='blue',markerfacecolor='black')
plt.show()

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.linspace(0,20,10)
y = np.sin(x)
plt.grid(ls='--',c='grey') #绘制网格线,线形为--,颜色为灰色
plt.plot(x,y,c='red',lw=3,ls='--',marker='o',markersize=10,markeredgecolor='blue',markerfacecolor='black')
plt.show()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.linspace(0,20,10)
y = np.sin(x)
plt.plot(x,y,c='black',lw=3,ls='--')
plt.axhline(y=0.25,c='red',ls='--',lw=1) #绘制平行于X轴的参考线
plt.axvline(x=10,c='red',ls='--',lw=1) #绘制平行于Y轴的参考线
#如果x轴为某个列表里汉字的话,则使用索引进行定位
plt.show()

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.linspace(0,20,10)
y = np.sin(x)
plt.plot(x,y,c='black',lw=3,ls='--')
plt.axvspan(xmin=10,xmax=15,facecolor='red',alpha=0.3) #绘制平行于Y轴的参考区域,从10开始,到15结束,颜色为红色,透明度为0.3
plt.axhspan(ymin=0,ymax=0.5,facecolor='blue',alpha=0.3) #绘制平行于X轴的参考区域,从0开始,到0.5结束,颜色为蓝色,透明度为0.3
plt.show()

fig=plt.figure()#创建画布
ax =fig.add_axes([a,b,c,d])
该参数是一个4元素列表,第一个元素代表距离最左边的距离,第二个元素代表距离最下面的距离,可以理解为画布左下角的起点坐标,第三个元素和第四个代表画布的长度和和宽度
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_excel(r'F:\data\各产业季度产值.xlsx')
plt.rcParams['font.sans-serif']=['SimHei']
data=pd.pivot_table(data=data,index='Quarter',values='GDP',columns='industr_Type',aggfunc=np.sum)
fig=plt.figure()#创建画布
ax =fig.add_axes([0.2,0.15,1.6,1.2])
plt.bar(x=data.index.values,height=data['第一产业'],color='red',label='第一产业',tick_label=['第一季度','第二季度','第三季度','第四季度'])
plt.bar(x=data.index.values,height=data['第二产业'],color='blue',label='第二产业',tick_label=['第一季度','第二季度','第三季度','第四季度'],\
bottom=data['第一产业'])
plt.bar(x=data.index.values,height=data['第三产业'],color='green',label='第三产业',tick_label=['第一季度','第二季度','第三季度','第四季度'],\
bottom=data['第一产业']+data['第二产业'])
plt.legend(title='各产业对应图',ncol=3,loc=2,fancybox=True,fontsize=10,frameon=True)
plt.xlabel('季度',size=10,labelpad=10)
plt.ylabel('产值(亿)',size=10,labelpad=10)
plt.title('各季度各产业产值堆积条形图',size=20,pad=10)
plt.show()
暂无,看书补充,云开见明讲了个锤子
一个是添加图形内容细节的指向型注释文本,另外一个是添加图形细节的无指向型注释文本
无指向型注释文本:
plt.text(x,y,string,weight,color,fontsize)
x,y表示添加文本内容的坐标,string表示添加文本的内容,weight表示字体粗细风格,color表示颜色,fontsize表示字体大小
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.linspace(0,20,10)
y = np.sin(x)
fig = plt.gcf()
fig.set_size_inches(8,4) #调整图像的大小
plt.plot(x,y,c='red',lw=3,ls='--',marker='o',markersize=10,markeredgecolor='blue',markerfacecolor='black')
plt.text(6.5,0.75,'这是添加的文本内容',fontsize=15,color='blue',weight='bold')
plt.show()

指向型注释文本:
plt.annotate(string,xy=(),xytext=(),weight=,color=,arrowprops=dict(arrowstyle= '->’,connection=‘acr3’,color=))
string:图形内容的注释文本
xy:被注释图形内容的位置坐标
xytext:注释文本的位置坐标
weight:注释文本的字体粗细风格
arrowprop:指示被注释内容的箭头的属性字典,arrowstyle=表示箭头的形状,使用此参数时只修改color、arrowstyle参数即可,其他参数使用默认就ok
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.linspace(0,20,10)
y = np.sin(x)
fig = plt.gcf()
fig.set_size_inches(8,4) #调整图像的大小
plt.rcParams['font.sans-serif']=['SimHei']
plt.plot(x,y,c='red',lw=3,ls='--',marker='o',markersize=10,markeredgecolor='blue',markerfacecolor='black')
plt.annotate('最大值点',xy=(19.5,0.90),xytext=(2.9,0.5),color='blue',fontsize=15,arrowprops=dict(arrowstyle='<->',color='blue',))
plt.show()
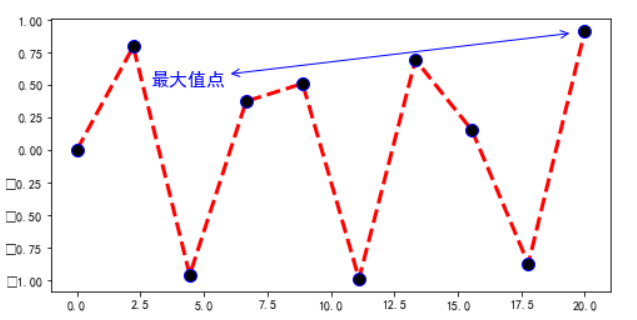
可以使用 plt.annotate? 查看参数的可选范围等信息
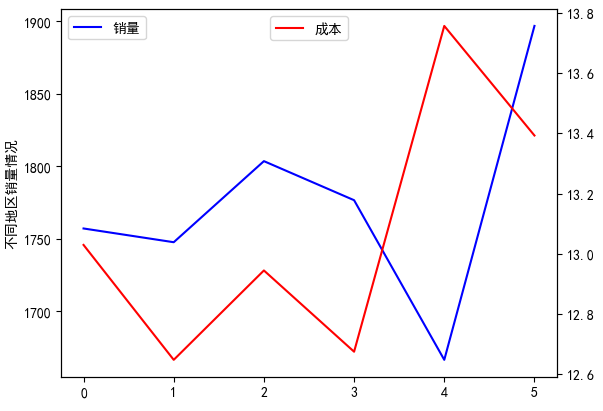
在数据分析中,很多时候,由于变量之间量纲级不一样,如果绘制在同一个坐标轴上,量纲级较小的变量就很难看出变化趋势,所以需要绘制双坐标轴,来显示两个变量的趋势
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_excel('F:\data\Region.xlsx')
plt.rcParams['font.sans-serif']=['SimHei']
fig = plt.figure()
axis_1 = fig.add_subplot(111)
axis_1.plot(data.index,data.Sales,label='销量',color='blue')
axis_1.set_ylabel('不同地区销量情况')
plt.legend(loc='upper left')
axis_2 = axis_1.twinx()
axis_2.plot(data.index,data.Trans_Cost,color='red',label='成本')
plt.legend(loc='upper center')
plt.show()
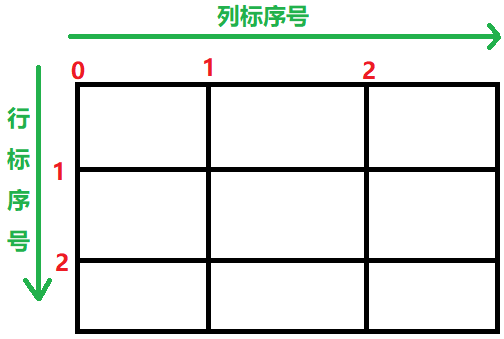
subplot2grid函数可以让子区跨越固定的网格布局的多个行和列,实现不同的子区布局
plt.subplot2grid(shape,loc,colspan,rowspan)
参数:
shape:网格布局(几行几列的布局)
loc:表示图形的位置起点(从0开始)
colspan:跨越的列数
rowspan:跨越的行数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.figure(figsize=(16,9))
#画第一幅图,从(0,0)开始,占一行两列
plt.subplot2grid((2,3),(0,0),colspan=2,rowspan=1)
x = np.linspace(0,40,10)
y = np.sin(x)
plt.plot(x,y,c='black',lw=3,ls='--')
plt.axvspan(xmin=10,xmax=15,facecolor='red',alpha=0.3)
plt.axhspan(ymin=0,ymax=0.5,facecolor='blue',alpha=0.3)
#画第二幅图,从(0,2)开始,占两行一列
plt.subplot2grid((2,3),(0,2),colspan=1,rowspan=2)
x = np.linspace(0,20,10)
y = np.sin(x)
plt.plot(x,y,c='black',lw=3,ls='--')
plt.axvspan(xmin=10,xmax=15,facecolor='red',alpha=0.3)
plt.axhspan(ymin=0,ymax=0.5,facecolor='blue',alpha=0.3)
#画第三幅图,从(1,0)开始,占一行两列
plt.subplot2grid((2,3),(1,0),colspan=2,rowspan=1)
x = np.linspace(0,20,10)
y = np.sin(x)
plt.grid(ls='--',c='grey')
plt.plot(x,y,c='red',lw=3,ls='--',marker='o',markersize=10,markeredgecolor='blue',markerfacecolor='black')
plt.show()

Seaborn是在matplotlib发展的,使得作图更加容易,也容易绘制更加精致的图形,并且兼容pandas和numpy等数据结构
import seaborn as sns #导入seaborn库
使用seaborn绘制图形,有三种方式,分别如下:
--plt.style.use( ‘seaborn’)
--sns.set()
--调用seaborn函数
但对于简单的制图,使用前两种都可以,但对于复杂图形,可能会使用第三种方式
plt.style.use( ‘seaborn’):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')
plt.rcParams['font.sans-serif']=['SimHei'] #需要加在plt.style.use('seaborn')之后
plt.rcParams['axes.unicode_minus']=False
data = pd.read_excel(r'F:\data\GDP.xlsx')
plt.figure(figsize=(4,3),dpi=100)
plt.bar(x=data.city.index.values,height=data.gdp,color='blue',tick_label=data.city)
plt.ylabel('GDP万亿')
plt.show()
sns.set():
style:为绘图风格,一共五种风格
context:控制绘图元素的规模
Palette:调色板
Font:这个参数—般不管,不用调整
font_scale:字体大小
color_codes:—般用默认值
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='darkgrid',context='notebook',font_scale=1.2)
data = pd.read_excel(r'F:\data\GDP.xlsx')
plt.figure(figsize=(4,3),dpi=100)
plt.bar(x=data.city.index.values,height=data.gdp,color='blue',tick_label=data.city)
plt.ylabel('GDP万亿')
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.show()
调用seaborn函数:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_excel(r'F:\data\GDP.xlsx')
plt.figure(figsize=(4,3),dpi=100)
sns.barplot(x='city',y='gdp',data=data,color='red',orient='v')#orient='h'表示横向条形图,只不过x和y的数据要调换下顺序
plt.show()

给柱状图上加上数据值标签:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_excel(r'F:\data\GDP.xlsx')
plt.figure(figsize=(4,3),dpi=100)
sns.barplot(x='city',y='gdp',data=data,color='red',orient='v')
for x,y in enumerate(data.gdp):
plt.text(x,y+0.1,"%s万亿"%round(y,1),ha='center',fontsize=10)
plt.show()
sns.barplot(x='Quarter',y='GDP',hue='industr_Type',data=data,color='blue',palette='husl',orient='v')
x,y:不同坐标上的值
hue:分类变量
data:数据
color:颜色
palette:调色板
orient:方向(vertical:垂直,horizontal:水平〕
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_excel(r'F:\data\各产业季度产值.xlsx')
plt.figure(figsize=(8,5),dpi=100)
sns.barplot(x='Quarter',y='GDP',hue='industr_Type',data=data,color='blue',palette='husl',orient='v')
plt.ylabel('GDP')
plt.legend(bbox_to_anchor=(1.01,0.85),frameon=True)
plt.rcParams['font.sans-serif']=['SimHei']
plt.show()
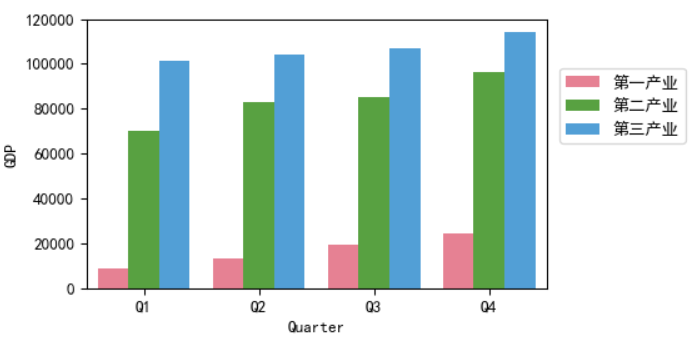
绘制柱状图语法如下:
sns.scatterplot(x,y,hue,data,color,palette,style,s,markers
x,y:不同坐标上的值
hue:分类变量
data:数据
color:颜色
palette:调色板
style:以分类变量作图时产生不同的形状
s:形状人小
markers:形状
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(7,5),dpi=120)
iris = pd.read_csv(r'F:\data\iris.csv')
sns.scatterplot(x='Petal_Width',y='Petal_Length',data=iris,hue='Species',color='red',s=20,style='Species')
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
plt.rcParams['font.sans-serif']=['SimHei']
plt.show()
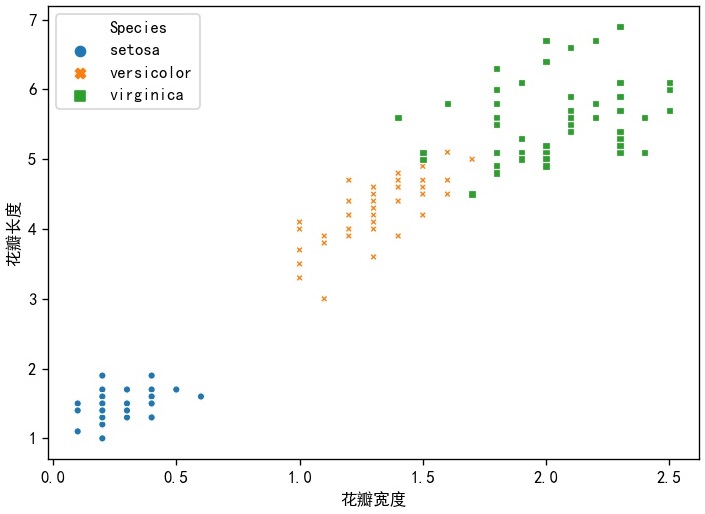
对比plt模块下的分类散点图代码,相比之下简单许多
plt模块下的分类散点图代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv(r'F:\data\iris.csv')
plt.figure(figsize=(7,5),dpi=120)
plt.rcParams['font.sans-serif']=['SimHei']
kind=['setosa','versicolor','virginica']
color_kind=['red','blue','green']
marker_kind=['o','x','v']
plt.figure(dpi=100)
for i in range(0, 3):
plt.scatter(x=data['Petal_Width'][data['Species']==kind[i]],\
y=data['Petal_Length'][data['Species']==kind[i]],\
color=color_kind[i],marker=marker_kind[i],\
label=kind[i])
plt.legend(loc='best')
plt.xlabel('花瓣长度',fontsize=10)
plt.ylabel('花瓣宽度',fontsize=10)
plt.show ()
sns.boxplot(x,y,hue,data,order,width,fliersize,linewidth,color,palette)
x,y不同坐标上的值
hue:分类变量
data:数据
width:箱线宽度
fliersize:异常值点的人小
color:颜色
palette:调色板
linewidth:指定箱体边框的宽度
(这里的参数和plt模块下的参数一模一样,只不过调用函数名不同而已,详情请点击这里)
创建分类的箱线图时,需要加上order=datd.index代码语句
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
plt.figure(figsize=(7,5),dpi=120)
Titanic = pd.read_csv(r'F:\data\titanic_train.csv')
Titanic.dropna(subset=['Age'],inplace =True)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
Age_Male = Titanic[Titanic.Sex =='male']['Age']
Age_Female = Titanic[Titanic.Sex =='female']['Age']
sns.distplot(Age_Male,bins=30,kde=False,hist_kws={'color':'steelblue'},norm_hist=True,label='男性')
sns.distplot(Age_Male,hist=False,kde=False,fit=norm,fit_kws={'color':'yellow'},norm_hist=True,label='男性正态分布图')
sns.distplot(Age_Female,bins=30,kde=False,hist_kws={'color':'steelblue'},norm_hist=True,label='女性')
sns.distplot(Age_Female,hist=False,kde=False,fit=norm,fit_kws={'color':'blue'},norm_hist=True,label='女性正态分布图')
plt.legend(loc='best')
plt.show()
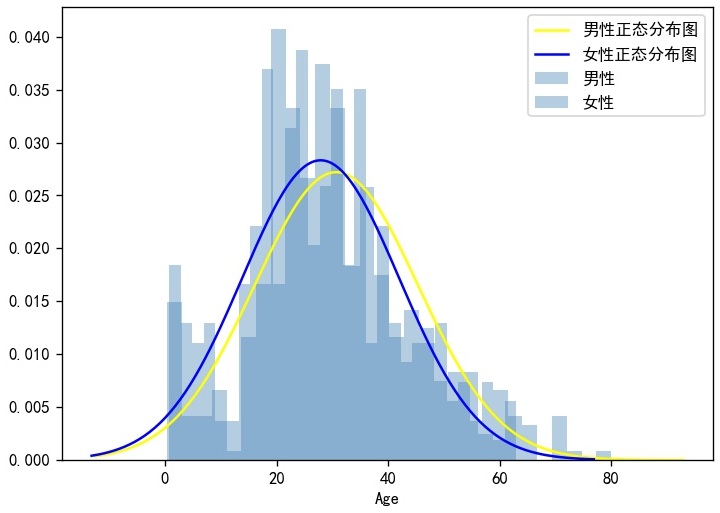
bins=30表示绘制30个柱状格
kde=Fasle表示不绘制核密度图
hist_kws=表示控制直方属性的参数
norm_hist=True表示以频率形式展示
hist=False表示不绘制直方图的柱状形态
云开见明很多都没讲,需要自己查书来了解各个参数的含义
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
os.chdir('C:\data\第四章')
data = pd.read_csv('财政收入data.csv')
data['year']=range(1994,2014,1)
sns.set(style='ticks') #设置风格为tickes
plt.rcParams['font.sans-serif']=['SimHei']
sns.lineplot(x='year',y='y',data=data,lw=2,color='blue') #绘制折线图
plt.xticks(range(1994,2014,1),range(1994,2014,1),rotation=45) #rotation表示旋转角度
plt.show()
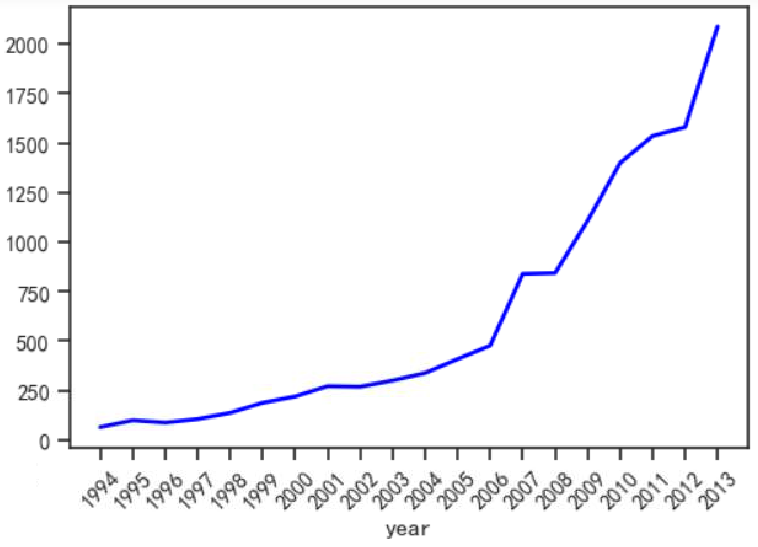
回归图本质就是将两个变量之间的线性关系展示出来
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data=pd.read_excel('F:\data\散点图.xlsx')
plt.figure(dpi=100)
sns.lmplot(x='电话次数',y='销售额',data=data,legend_out=False,markers='o',fit_reg=True,\
aspect=2,height=5,scatter_kws={'s':20,'facecolor':'red'})
plt.savefig('F:\data\散点图.png')
plt.show()
fit_reg=True表示是否将数据进行拟合
aspect=2表示长度为2
height=5表示高度为5
scatter_kws=表示散点图的属性设置
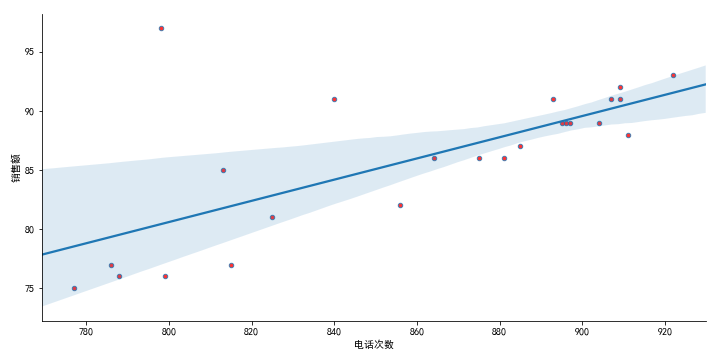
主要用于绘制数据中,每个类别出现的数量,只能计数
源数据截图如下:

比如想绘制不同的Region下的订单量的柱状图:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(dpi=100)
data=pd.read_excel('C: \datal第四章\Prod_Trade.xlsx')
sns.countplot(x='Region',data=data)
plt.rcParams['font.sans-serif']=['SimHei']
plt.show()
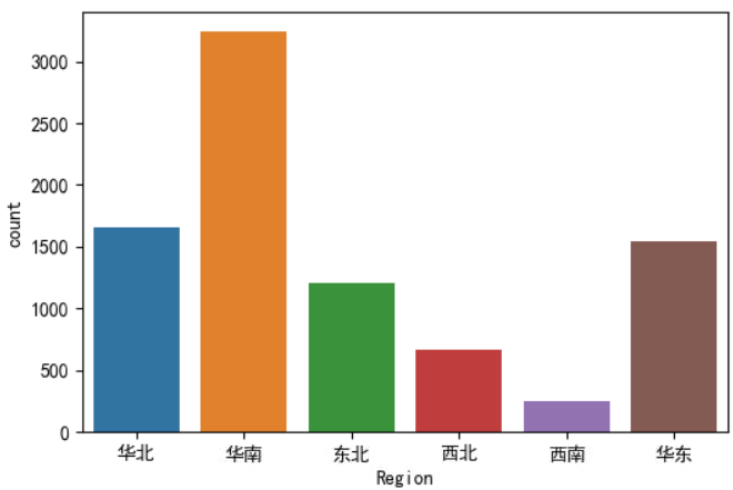
例如绘制各个Region下每种出行方式订单量的柱状图:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(dpi=100)
data=pd.read_excel('C: \datal第四章\Prod_Trade.xlsx')
sns.countplot(x='Region',data=data,hue='Transport')
plt.rcParams['font.sans-serif']=['SimHei']
plt.show()
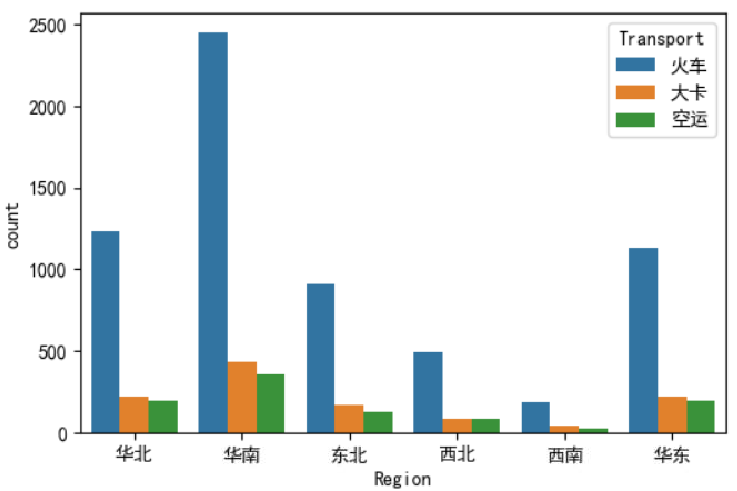
sns.set(style,context,palette)
style:主题样式:darkgrid(灰白背景+网格)、 whitegrid(白白背景+灰网格)、 dark 、white、 ticks(带坐标轴刻度)
context:可以理解为设置输出图片元素的大小尺寸paper、notebook, talk、and poster (元素缩放)
palette:调色板deep、muted、pastel、bright、dark、colorblind,palette一般可以用默认值
font_scale:表示坐标轴的缩放(一般1.2左右)
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(dpi=100)
sns.set(style='darkgrid',context='notebook',font_scale=1.2,palette='bright')
data=pd.read_excel('C:\datal第四章\Prod_Trade.xlsx')
sns.countplot(x='Region',data=data,hue='Transport')
plt.rcParams['font.sans-serif']=['SimHei']
plt.show()
plotly是一个基于JavaScript的绘图库,plotly绘图种类丰富,效果美观,易于保存与分享plotly的绘图结果可以与Web无缝集成
plotly默认的绘图结果是一个HTML网页文件,通过浏览器可以查看
在真实项目中,使用plotly绘图模块进行绘图的完整流程包括:
1.添加图轨数据,例如使用Scatter函数
2.设置画图布局,使用layout命令
3.集成图形、布局数据
4.绘制图形的输出命令是offline.plot
关于图形输出命令:
使用plotly.offline.plot和Plotly.offline.iplot()
使用plotly.offline.plot方法会在本地新建一个HTML文件,并可以选择是否在浏览器中打开这个文件
使用会在plotly.offline.iplot()方法会在Jupyter Notebook中直接绘图
import plotly as py
import plotly.graph_objs as go #graph_objs是plotly库下一个用于绘制图形对象的模块
from plotly.graph_objs import Scatter #从graph_objs模块中导入Scatter函数
py.offline.init_notebook_mode() #使图形可以顺利显示在jupyter notebook中
示例:
import plotly as py
import plotly.graph_objs as go
from plotly.graph_objs import Scatter
py.offline.init_notebook_mode()
try_1=Scatter(x=[1,2,3,4,5],y=[15,19,17,18,13])
data=[try_1]
py.offline.iplot(data)

plotly绘制散点图、折线图都是使用Scatter函数
import plotly as py
import plotly.graph_objs as go
go.Scatter()
语法格式:
Scatter(x,y,mode,name,marker,line)
x----数据
y----数据
mode ----线条类型(markers表示散点图、lines表示折线图、markers+lines表示线上有散点的组合图)
name ----图例名称
marker ------控制点的相关参数
line -----控制线条颜色
布局控制语法格式:
go.Layout(title,xaxis, yaxis)
title ----标题
xaxis ----控制x轴参数
yaxis-----控制y轴参数
数据处理完成、布局控制处理完成后,需要使用go.Figure()将两者集合起来,go.Figure()中的data必须是列表形式
源数据展示:

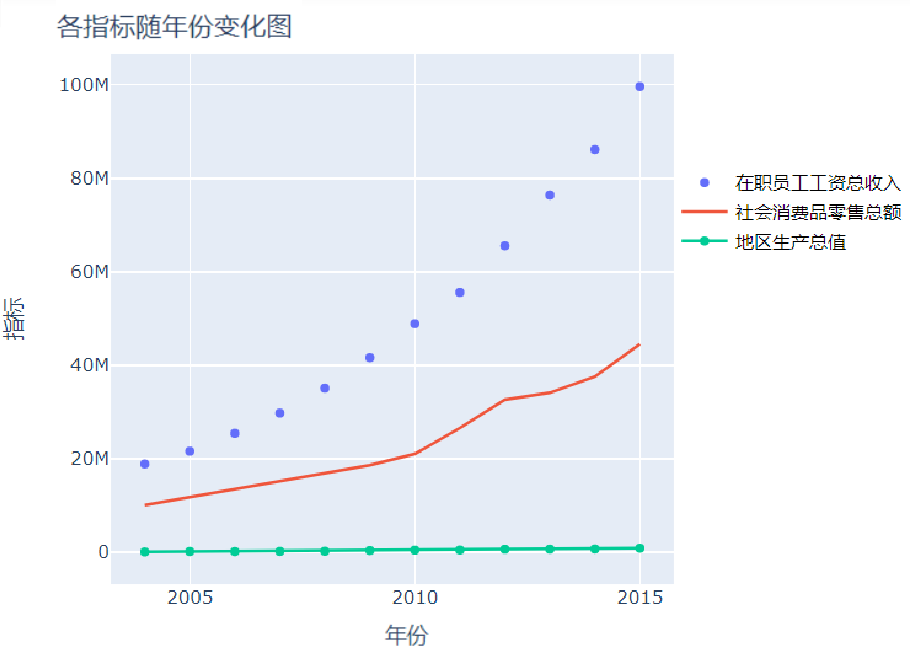
import pandas as pd
import numpy as np
import plotly as py
import plotly.graph_objs as go
from plotly.graph_objs import Scatter
py.offline.init_notebook_mode()
data = pd.read_csv('C:\datal第四章\income_tax.csv')
try_1 = Scatter(x=data['year'],y=data['x2'],mode='markers',name='在职员工工资总收入')
try_2 = Scatter(x=data['year'],y=data['x3'],mode='lines',name='社会消费品零售总额')
try_3 = Scatter(x=data['year'],y=data['x8'],mode='markers+1ines',name='地区生产总值')
layout = go.Layout(title='各指标随年份变化图',xaxis=dict(title='年份'),yaxis=dict(title='指标'),\
legend=dict(x=1,y=0.8,font=dict(size=12,color='black')))
data_list = [try_1,try_2,try_3]
fig = go.Figure(data=data_list,layout=layout)
py.offline.iplot(fig)
import plotly as py
import plotly.graph_objs as go
go.Bar()
plotly绘制柱状图使用Bar函数
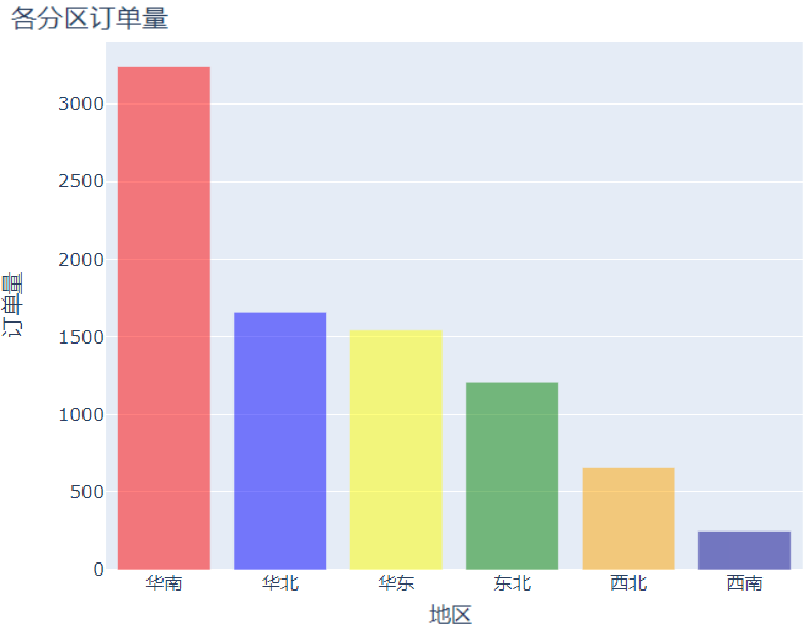
例如想绘制不同地区的订单量柱状图,因为plotly中没有seaborn的countplot方法,所以稍微麻烦
源数据展示:
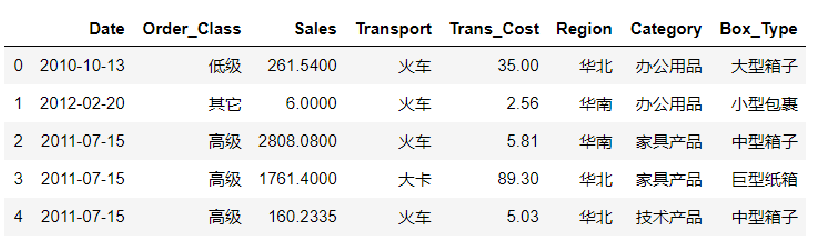
import pandas as pd
import plotly as py
import plotly.graph_objs as go
py.offline.init_notebook_mode()
data = pd.read_excel('C:\data\第四章\Prod_Trade.xlsx')
data_region=data['Region'].value_counts()
try_1=[go.Bar(x=data_region.index.tolist(),y=data_region.values.tolist(),\
marker=dict(color=['red','blue','yellow','green','orange','darkblue']),\
opacity=0.50)]
layout=go.Layout(title='各分区订单量',xaxis=dict(title='地区'),yaxis=dict(title='订单量'))
fig=go.Figure(data=try_1,layout=layout)
py.offline.iplot(fig)
使用plotly绘制分类柱状图
分类柱状图的原理就是在plotly中画n个柱状图,然后plotly会自动调整为分类的柱状图,但是一般不建议使用plotly绘制,可以使用seabron的countplot方法,点击跳转
源数据展示:
import pandas as pd
import plotly as py
import plotly.graph_objs as go
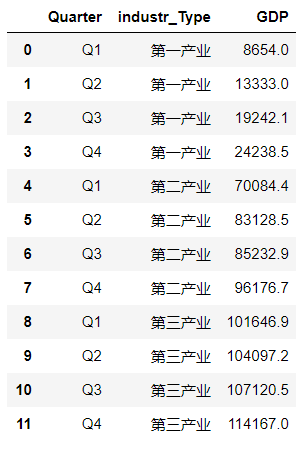
data=pd.read_excel('F:\data\各产业季度产值.xlsx')
data_1=data[data['industr_Type']=='第一产业']
data_2=data[data['industr_Type']=='第二产业']
data_3=data[data['industr_Type']=='第三产业']
try_1=go.Bar(x=data_1.Quarter,y=data_1['GDP'],name='第一产业')
try_2=go.Bar(x=data_2.Quarter,y=data_2['GDP'],name='第二产业')
try_3=go.Bar(x=data_3.Quarter,y=data_3['GDP'],name='第三产业')
data=[try_1,try_2,try_3]
layout=go.Layout(title='各产业季度产值',xaxis=dict(title='季度'))
fig=go.Figure(data=data,layout=layout)
py.offline.iplot(fig)
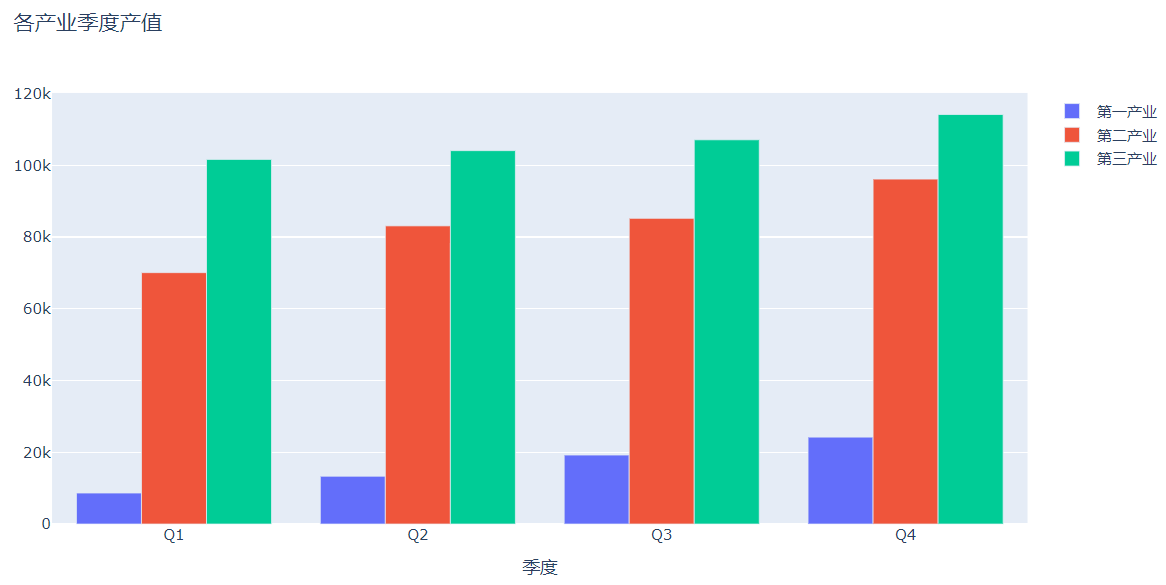
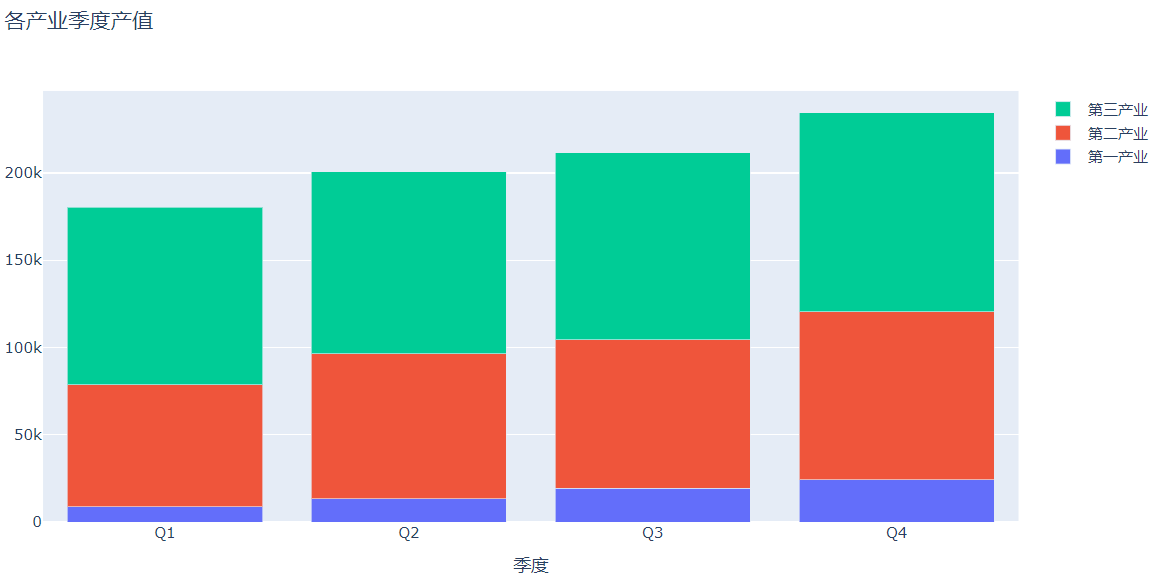
使用plotly绘制堆积柱状图
在plotly中绘制堆积柱状图只需要在分类柱状图的基础上给go.Layout语句加一个参数即可
barmode='stack'
import pandas as pd
import plotly as py
import plotly.graph_objs as go
data=pd.read_excel('F:\data\各产业季度产值.xlsx')
data_1=data[data['industr_Type']=='第一产业']
data_2=data[data['industr_Type']=='第二产业']
data_3=data[data['industr_Type']=='第三产业']
try_1=go.Bar(x=data_1.Quarter,y=data_1['GDP'],name='第一产业')
try_2=go.Bar(x=data_2.Quarter,y=data_2['GDP'],name='第二产业')
try_3=go.Bar(x=data_3.Quarter,y=data_3['GDP'],name='第三产业')
data=[try_1,try_2,try_3]
layout=go.Layout(title='各产业季度产值',xaxis=dict(title='季度'),barmode='stack')
fig=go.Figure(data=data,layout=layout)
py.offline.iplot(fig)
import plotly as py
import plotly.graph_objs as go
go.Histogram()
源数据展示:
import pandas as pd
import plotly as py
import plotly.graph_objs as go
data=pd.read_csv(r'C: \datal第四章1titanic_train.csv')
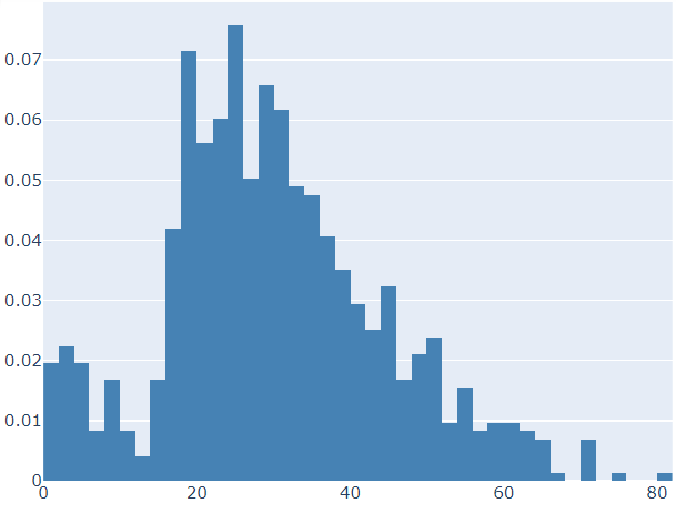
try_1=[go.Histogram(x=data['Age'],histnorm='probability',marker=dict(color='blue'))]
py.offline.iplot(try_1)
histnorm='probability'表示绘制成频率的形式,而不是频数的形式
import plotly as py
import plotly.graph_objs as go
go.Pie()
源数据展示:
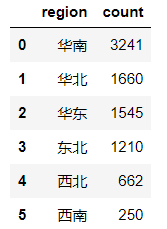
import pandas as pd
import plotly as py
import plotly.graph_objs as go
data=pd.read_excel(r'F:\data\region_count.xlsx')
try_1=[go.Pie(labels=data['region'].tolist(),values=data['count'].tolist(),\
hole=0.4,textfont=dict(size=12,color='white'))]
layout=go.Layout(title='不同地区订单量')
fig=go.Figure(data=try_1,layout=layout)
py.offline.iplot(fig)
hole=0.4表示饼图中间空心圆的半径大小
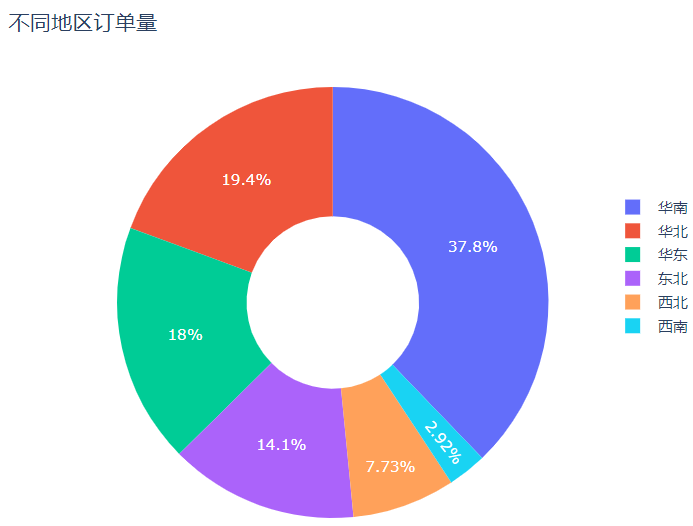
plotly下的图形设置主要分为以下三个部分:
多图表、双坐标轴、多子图
需求:将每个地区的订单量绘制成柱状图,再将所有地区订单量的平均值绘制出来,观察每个地区的订单量和平均值的差异
源数据展示:
import numpy as np
import pandas as pd
import plotly as py
import plotly.graph_objs as go
data=pd.read_excel(r'F:\data\region_count.xlsx')
data_y=np.tile(np.mean(data['count']),6) #将count的平均值复制6次
try_1=go.Bar(x=data['region'].tolist(),y=data['count'].tolist(),\
marker=dict(color=['red','blue','yellow','green','orange','darkblue']),\
opacity=0.4)
try_2=go.Scatter(x=data.region.tolist(),y=data_y,mode='lines',name='平均值')
num=[try_1,try_2]
layout=go.Layout(title='不同地区订单量',xaxis=dict(title='地区'))
fig=go.Figure(data=num,layout=layout)
py.offline.iplot(fig)

源数据展示:
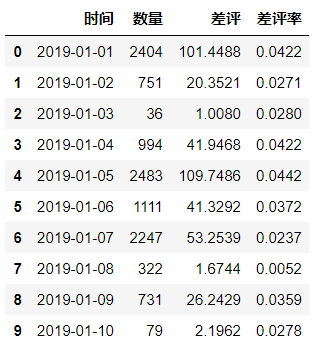
import numpy as np
import pandas as pd
import plotly as py
import plotly.graph_objs as go
data=pd.read_excel(r'F:\data\双轴图.xlsx')
data['时间']=pd.to_datetime(data['时间'])
try_1=go.Bar(x=data['时间'].tolist(),y=data['数量'].tolist(),marker=dict(color='steelblue'),opacity=0.6,name='评价数量')
try_2=go.Scatter(x=data['时间'].tolist(),y=data['差评率'].tolist(),mode='lines',name='差评率折线图',yaxis='y2')
case=[try_1,try_2]
layout=go.Layout(title='客户评价图',xaxis=dict(title='时间'),yaxis=dict(title='评价数量'),\
yaxis2=dict(title='差评率',overlaying='y',side='right'),\
legend=dict(x=0.1,y=0.9),font=dict(size=12,color='black'))
fig=go.Figure(data=case,layout=layout)
py.offline.iplot(fig)
yaxis='y2' 表示第二条y轴
overlaying='y',side='right' 表示将第二条坐标轴在右边进行y轴的重叠
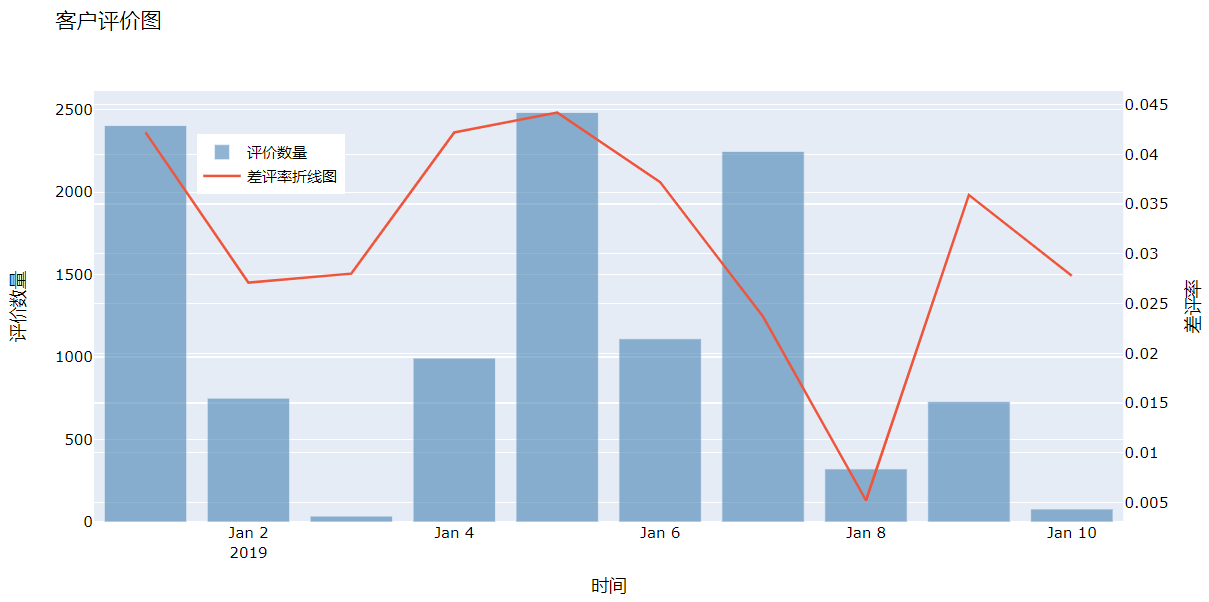
使用matplotlib中的subplot2grid函数也可以达到多子图的效果,详情请点击这里
在plotly中绘制双子图需要从plotly库中导入一个方法
import plotly.graph_objs as go
from plotly import tools
fig=tools.make_subplots(rows=2,cols=1)
源数据展示:
import numpy as np
import pandas as pd
import plotly as py
import plotly.graph_objs as go
from plotly import tools
fig=tools.make_subplots(rows=2,cols=1)
data=pd.read_excel(r'F:\data\双轴图.xlsx')
data['时间']=pd.to_datetime(data['时间'])
try_1=go.Bar(x=data['时间'].tolist(),y=data['数量'].tolist(),marker=dict(color='steelblue'),opacity=0.6,name='评价数量')
try_2=go.Scatter(x=data['时间'].tolist(),y=data['差评率'].tolist(),mode='lines',name='差评率折线图')
fig.append_trace(try_1,1,1)
fig.append_trace(try_2,2,1)
fig['layout'].update(height=600,width=800,title='客户评价情况')
py.offline.iplot(fig)
fig=tools.make_subplots(rows=2,cols=1) 表示多子图有两行一列
fig.append_trace(try_1,1,1) 表示将try_1的图行放到多子图的第一行第一列
fig.append_trace(try_2,2,1) 表示将try_1的图行放到多子图的第二行第一列
plotly中多子图示:(是从一开始的)

