hashMap的底层数据结构
本节用于记录Java HashMap底层数据结构、方法实现原理等,基于JDK 1.8。
# 底层数据结构
Java hashMap 是采用哈希表结构的(数组+链表 /jdk8后加入红黑树)实现,结合了数组和链表的优点,
1,数组优点:可以快速通过数组下标对数组元素操作,效率极高
2,链表优点:插入或删除元素不需要移动元素,只需要修改链表的引用,效率极高
hashMap图示如下:
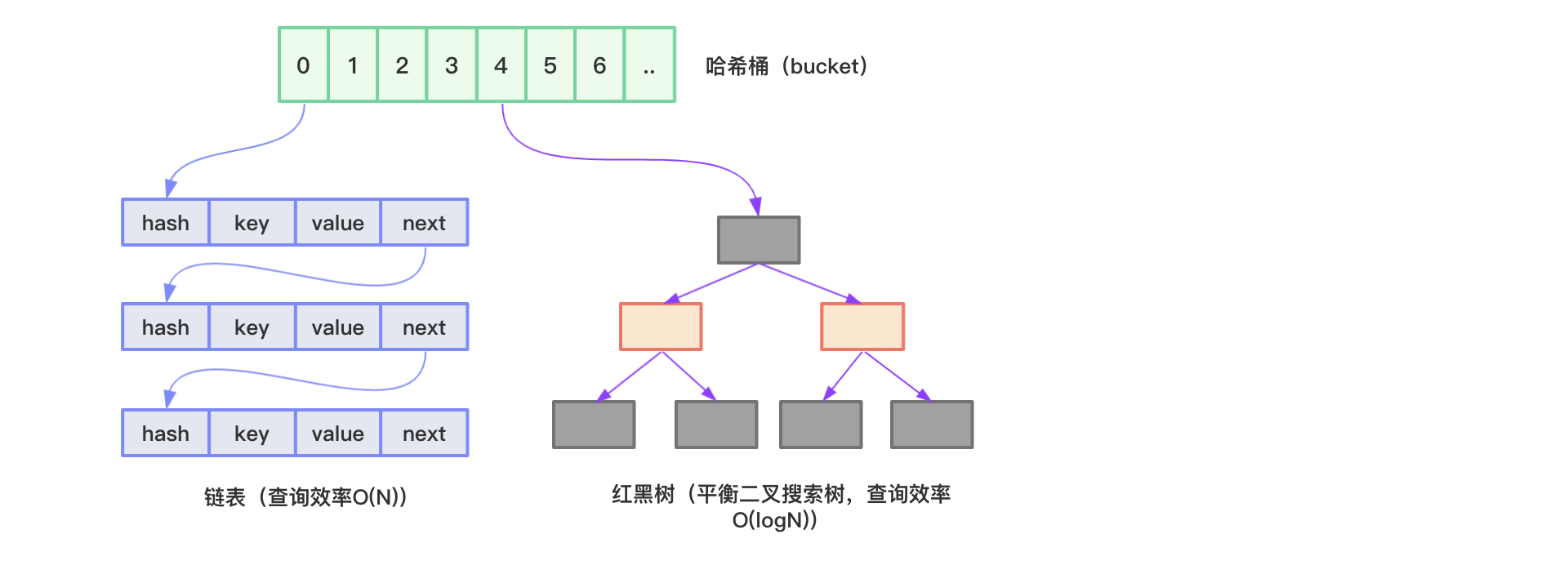
hashMap内部使用数组储存数据,每个元素都是一个Node<k,v>
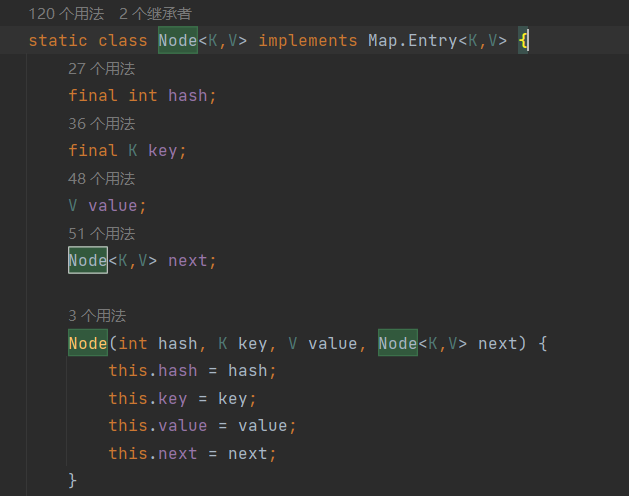
每个node 包含了hash,key,value,next 其中next表示下一个节点。
hashMap通过hash方法计算key的哈希码,然后通过公式计算key的下标。当数组中的下标存放一致时,数据将以链表的方式储存(hash冲突,hash碰撞)
我们知道,在链表中查找数据必须从第一个元素开始一层一层往下找,直到找到为止,时间复杂度为O(N),所以当链表长度越来越长时,HashMap的效率越来越低。
为了解决这个问题,JDK1.8开始采用数组+链表+红黑树的结构来实现HashMap。当链表中的元素超过8个(TREEIFY_THRESHOLD)并且数组长度大于64(MIN_TREEIFY_CAPACITY)时,会将链表转换为红黑树
HashMap包含几个重要的变量:
// 数组默认的初始化长度16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 数组最大容量,2的30次幂,即1073741824 static final int MAXIMUM_CAPACITY = 1 << 30; // 默认加载因子值 static final float DEFAULT_LOAD_FACTOR = 0.75f; // 链表转换为红黑树的长度阈值 static final int TREEIFY_THRESHOLD = 8; // 红黑树转换为链表的长度阈值 static final int UNTREEIFY_THRESHOLD = 6; // 链表转换为红黑树时,数组容量必须大于等于64 static final int MIN_TREEIFY_CAPACITY = 64; // HashMap里键值对个数 transient int size; // 扩容阈值,计算方法为 数组容量*加载因子 int threshold; // HashMap使用数组存放数据,数组元素类型为Node<K,V> transient Node<K,V>[] table; // 加载因子 final float loadFactor; // 用于快速失败,由于HashMap非线程安全,在对HashMap进行迭代时,如果期间其他线程的参与导致HashMap的结构发生变化了(比如put,remove等操作),直接抛出ConcurrentModificationException异常 transient int modCount;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号