目标检测复习之YOLO系列
目标检测之YOLO系列
YOLOV1:#
- blogs1: YOLOv1算法理解
- blogs2: <机器爱学习>YOLO v1深入理解
- 网络结构
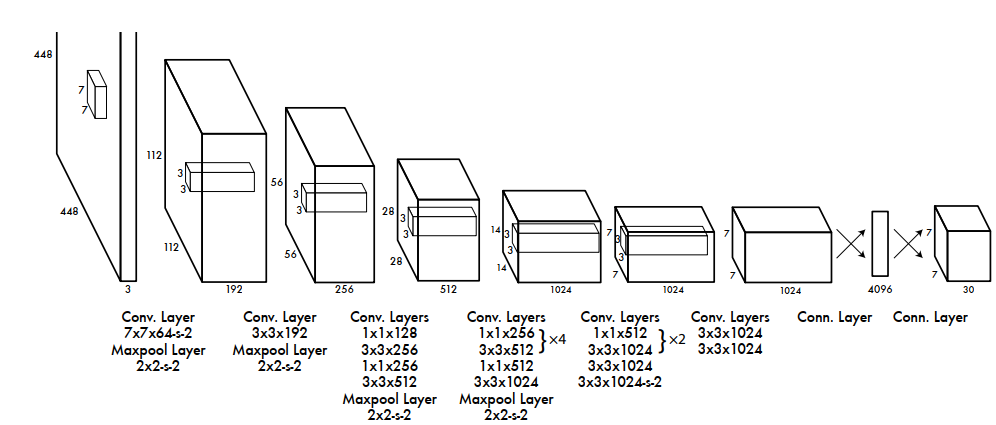
- 激活函数(leaky rectified linear activation)
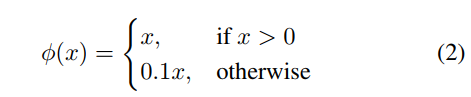
- 损失函数

YOLOV2:#
- paper: YOLO9000: Better, Faster, Stronger
- blogs1: 目标检测|YOLOv2原理与实现
YOLOV2总结:#
- Better
- Batch Normalization
BN可以提升模型收敛速度,而且可以起到一定正则化效果,降低模型的过拟合
YOLOv2使用BN,不使用dropout
- High Resolution Classifier
将分辨率由224*224(ImageNet分类尺寸)增加至448*448
- Convolutional With Anchor Boxes
使用先验框提高召回率
- Dimension Clusters
使用聚类算法生成先验框
- Faster
- 使用Darknet-19主干网络
YOLOV3:#
- paper: YOLOv3: An Incremental Improvement
- code1: [U版yolov3
- code2: mmdetection实现的代码
- blogs1: YOLO v3网络结构分析
- blogs2: 睿智的目标检测26——Pytorch搭建yolo3目标检测平台
YOLOV3总结:#
- 数据处理部分
- Backbones部分
DarkNet53, 网络结构如下:

- Neck部分
FPN
- Head部分
见网络结构图
- 激活函数
LeakyReLU
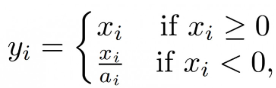
- 损失函数
目标类别损失/目标置信度损失 --> 二值交叉熵损失(Binary Cross Entyopy)
目标定位损失 --> Sum of Squared Error Loss(只有正样本才有目标定位损失)
L(loc) = sum(sigmod(tx-gx)**2 + sigmod(ty-gy)**2 + (tw-gw)**2 + (th-gh)**2)
- 其他
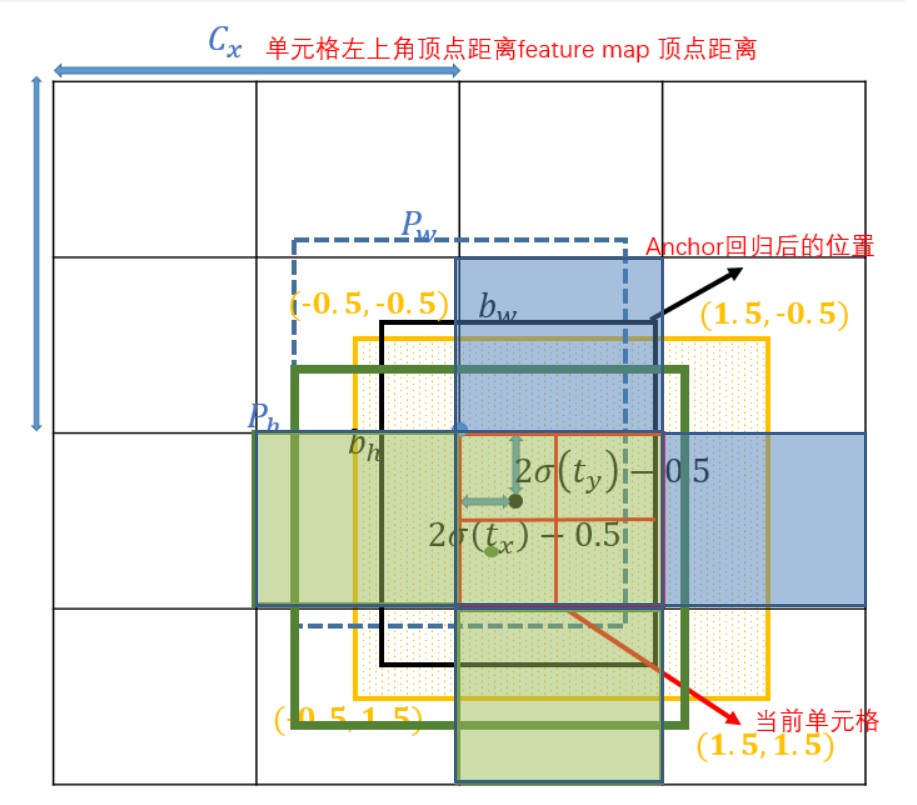
在yolov3中,关于预测的目标中心点坐标计算公式是:
见图:
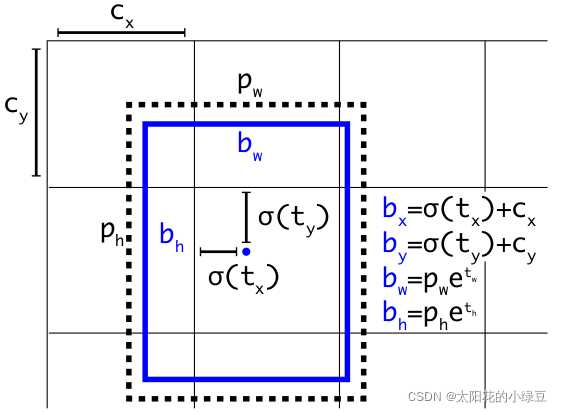
YOLOV4:#
- paper: YOLOv4: Optimal Speed and Accuracy of Object Detection
- code1: WongKinYiu/PyTorch_YOLOv4 与u版yolov3/5格式相同
- code2: bubbliiiing/yolov4-pytorch 代码比较好理解
- blogs1: b站up主霹雳吧啦Wz yolov4讲解博客
- blogs2: Bubbliiiing的博客
- video1: b站up主霹雳吧啦Wz yolov4讲解视频
YOLOV4总结:#
- 数据处理部分
1. Mosaic data augmentation
2. CutMix data augmentation
- Backbones部分
CSPDarknet53
- Neck部分
SPP
PAN
- Head部分
和YOLOv3的head部分一样
- 正负样本分配部分
1. 在yolov3中一个GT都只分配一个Anchor, 在ylov4中(以及u版的yolov3-spp)中一个gt可以同时分配给多个anchor
2. 在Bubbliiiing版本的代码中可以描述如下:(3个head分别对应anchor为[0,1, 2, 3, 4, 5, 6, 7, 8])
a: anchor有9个,gt有10个 每个anchor和gt进行左上角对齐并且计算iou从大到小排序(shape:[10,9])
b: 例如第一个gt算出来的最大iou的anchor的index=4,但是该层的anchor索引是6,7,8,所以该gt不属于该head
c: 如果计算出该gt与anchor对应的index=6: 将该gt缩放到该head的大小,该gt的中心点落在网格中的点. 该网格中的
点包含的信息有(x,y,w,h,conf,cls). 然后和预测出来的进行对比和计算(在该版本中计算方式同yolov3)
d: 使用sigmod激活函数的取值范围是[0, 1],要想取值0,1那么预测值需要取得无穷(在后续的yolov5中有改进)
- 损失函数部分
分类损失:
定位损失: CIOU,ciou的计算方式如下:

- 激活函数
Mish激活函数
- 其他
Class label smoothing(标签平滑策略)
学习率余弦退火衰减
YOLOV5:#
- paper: 无
- code: U版yolov5
- blog1: b站up主霹雳吧啦Wz yolov5讲解博客比较详细
- video1: b站up主霹雳吧啦Wz yolov5讲解视频
YOLOv5总结:#
- 数据处理部分
yolov5提供的数据增强技术有:
1. Mosaic
2. Copy paste (需要segments数据)
3. Random affine 仿射变换 作者只使用了Scale和Translation(缩放和平移)
4. MixUp
- Backbones部分
Backbone: new CSP-Darknet53(使用了FCOS模块后面使用6*6大小的卷积替换)
- Neck部分
spp, pan
- head:
yolov3 head
- 损失函数
Classes loss,分类损失,采用的是BCE loss,注意只计算正样本的分类损失
Objectness loss,obj损失,采用的依然是BCE loss
Location loss,定位损失,采用的是CIoU loss
- 其他
消除网格在断点等取不到值的情况
bx = (2*sigmod(tx) - 0.5) + cx
by = (2*sigmod(ty) - 0.5) + cy
那么就将原来的取值范围有[0, 1]变化到[-0.5, 1.5],也为后面使用相邻的网格预测点作为正样本奠定基础
同时:
bw = pw * (28sigmod(tw))**2
bh = ph * (28sigmod(th))**2
防止梯度爆炸,将范围调整到(0,4)也为后面的正负样本分配奠定基础
-
匹配正样本
-
-----------------------2022-9-12补充-------------------------
YOLOV5#
网络结构图#
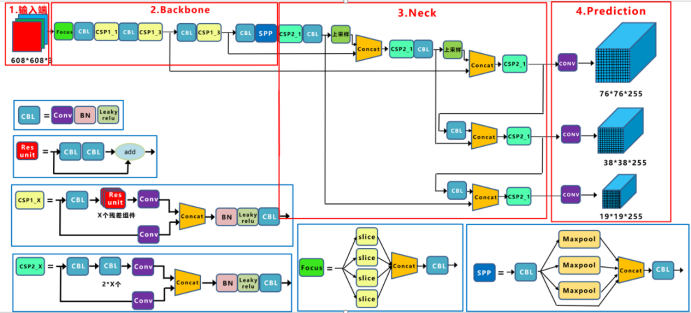
正负样本匹配#
yolov5基于anchor based,在开始训练前,会基于训练集中gt(ground truth 框),通过k-means聚类算法,先验获得9个从小到大排列的anchor框。先将每个gt与9个anchor匹配(以前是IOU匹配,yolov5中变成shape匹配,计算gt与9个anchor的长宽比,如果长宽比小于设定阈值,说明该gt和对应的anchor匹配),
如上图为yolov5的网络架构,yolov5有三层网络,9个anchor, 从小到大,每3个anchor对应一层prediction网络,gt与之对应anchor所在的层,用于对该gt做训练预测,一个gt可能与几个anchor均能匹配上。所以一个gt可能在不同的网络层上做预测训练,大大增加了正样本的数量,当然也会出现gt与所有anchor都匹配不上的情况,这样gt就会被当成背景,不参与训练,说明anchor框尺寸设计的不好。
在训练过程中怎么定义正负样本呢,因为yolov5中负样本不参与训练,所以要增加正样本的数量。gt框与anchor框匹配后,得到anchor框对应的网络层的grid,看gt中心点落在哪个grid上,不仅取该grid中和gt匹配的anchor作为正样本,还取相邻的的两个grid中的anchor为正样本。
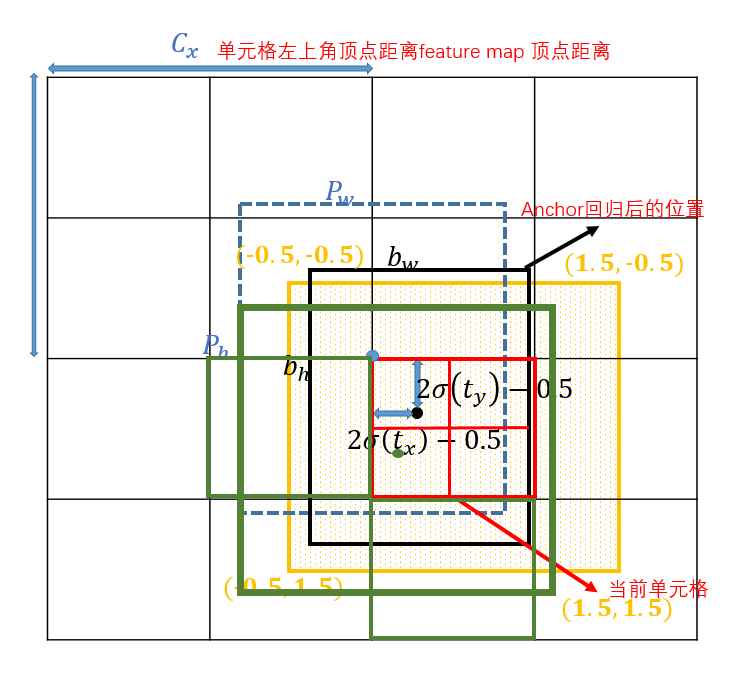
如上图所示,绿色的gt框中心点落在红色grid的第三象限里,那不仅取该grid,还要取左边的grid和下面的grid,这样基于三个grid和匹配的anchor就有三个中心点位于三个grid中心点,长宽为anchor长宽的正样本,同时gt不仅与一个anchor框匹配,如果跟几个anchor框都匹配上,所以可能有3-27个正样本,增大正样本数量。
YOLOV6#
- blog1: https://mp.weixin.qq.com/s/DFSROue8InARk-96I_Kptg
- blog2: https://mp.weixin.qq.com/s/RrQCP4pTSwpTmSgvly9evg(美团官方解读)
- blog3: https://zhuanlan.zhihu.com/p/353697121 (Repvgg解读)
- code: https://github.com/meituan/YOLOv6
模型的整体框架#
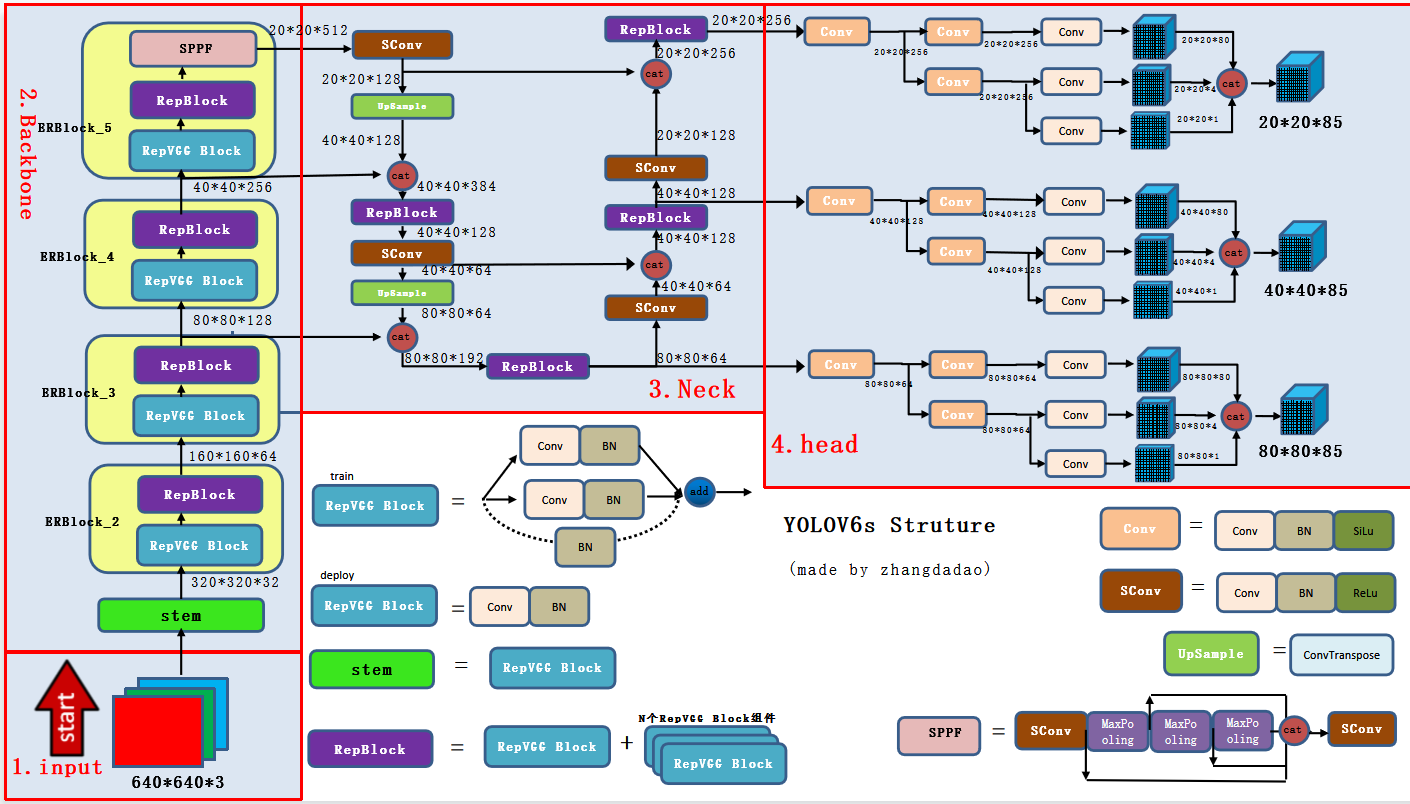
yolov6的正负样本匹配#
- 参考: https://mp.weixin.qq.com/s/nhZ3Q1NHm3op8abdVIGmLA
- yolov6的正负样本匹配策略同yolox,yolovx因为是anchor free,anchor free因为缺少先验框这个先验知识,理论上应该是对场景的泛化性更好,同时参见旷视的官方解读:Anchor 增加了检测头的复杂度以及生成结果的数量,将大量检测结果从NPU搬运到CPU上对于某些边缘设备是无法容忍的。
- yolov6中的正样本筛选,主要分成以下几个部分:
- 基于两个维度来粗略筛选;
- 基于simOTA进一步筛选。
- 具体步骤如下

tie标签的gt如图所示,找到gt的中心点(Cx,Cy),计算中心点到左上角的距离(l_l,l_t),右下角坐标(l_r,l_b),然后从两步筛选正样本:
- 第一步粗略筛选第一个维度是如果grid的中心点落在gt中,则认为该grid所预测的框为正样本,如图所示的红色和橙色部分,第二个维度是以gt的中心点所在grid的中心点为中心点,上下左右扩充2.5个grid步长范围内的grid,则默认该grid所预测的框为正样本,如图紫色和橙色部分。这样第一步筛选出31个正样本(注:这里单独一层的正样本,yolov6有三个网络层,分别计算出各层的正样本,并叠加)。

- 通过SimOTA进一步筛选:SimOTA是基于OTA的一种优化,OTA是一种动态匹配算法,具体参见旷视官方解读SimOTA
SimOTA流程如下:- 计算初筛正样本与gt的IOU,并对IOU从大到小排序,取前十之和并取整,记为b(用来决定改gt分配多少个正样本)。
- 计算初筛正样本的cos代价函数,将cos代价函数从小到大排列,取cos前b的样本为正样本。同时考虑同一个grid预测框被两个gt关联的情况,取cos较小的值,该预测框为对应的gt的正样本。
YOLOV7#
- blog1: https://mp.weixin.qq.com/s/VEcUIaDrhc1ETIPr39l4rg
- paper: https://arxiv.org/pdf/2207.02696.pdf
- 知乎: https://www.zhihu.com/question/541985721
- GiantPandaCV: https://mp.weixin.qq.com/s/yISNTj_--UIG5Fwcbcl-8g
模型的整体框架#
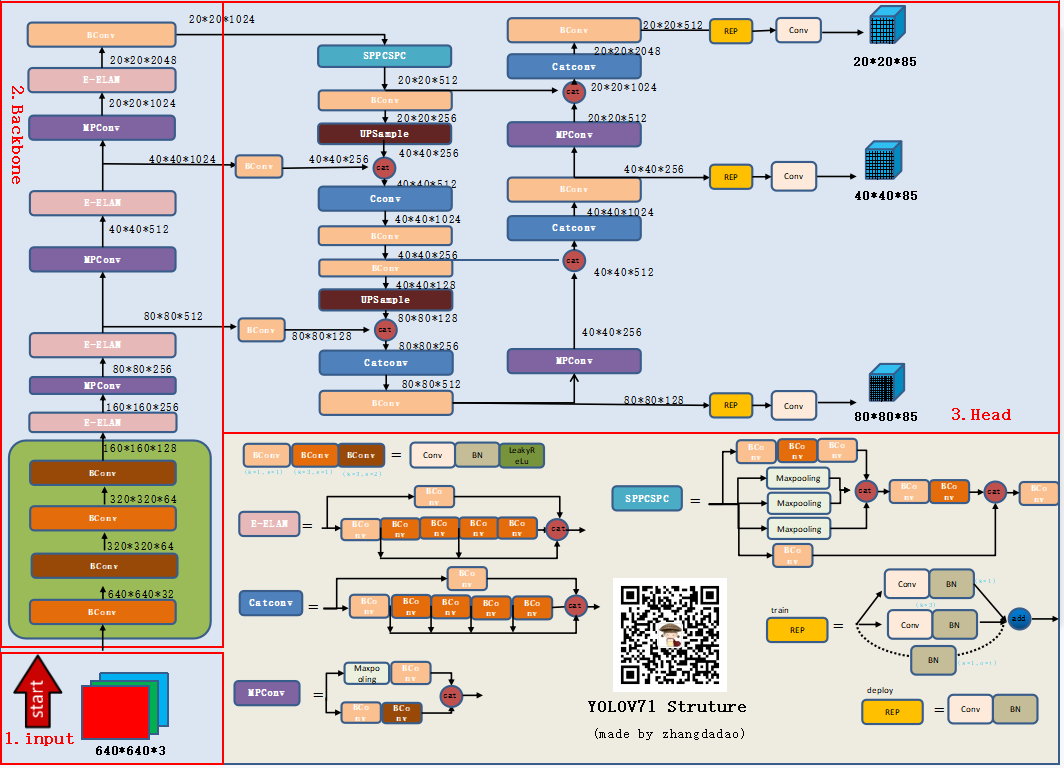
yolov7正负样本匹配#
yolov7因为基于anchor based , 集成v5和v6两者的精华,即yolov6中的第一步的初筛换成了yolov5中的筛选正样本的策略,保留第二步的simOTA进一步筛选策略。
同时yolov7中有aux_head 和lead_head 两个head ,aux_head做为辅助,其筛选正样本的策略和lead_head相同,但更宽松。如在第一步筛选时,lead_head 取中心点所在grid和与之接近的两个grid对应的预测框做为正样本,如图绿色的grid, aux_head则取中心点以及周围的4个预测框为正样本。如下图绿色+蓝色区域的grid.
同时在第二步simOTA部分,lead_head 是计算初筛正样本与gt的IOU,并对IOU从大到小排序,取前十之和并取整,记为b。aux_head 则取前二十之和并取整。其他步骤相同,aux_head主要是为了增加召回率,防止漏检,lead_head再基于aux_head 做进一步筛选。
- -----------------------2022-9-12补充-------------------------
YOLOX:#
除了YOLOX,yolov1属于anchor-free目标检测方法外,其他的yolo系列都属于anchor-base方法
- paper: yolox的arxiv-paper
- code1: yolox的官方代码
- code2: mmdetection实现的代码
- blog1: 深入浅出Yolo系列之Yolox核心基础完整讲解
YOLOX总结#
- 数据增强部分
Mosaic
Mixup
- Backbone
CSPDarknet53
- Neck部分
spp + pan
- Head部分
使用decoupled head(将分类头和回归头分开)
- 正样本标签分配 - simota
- 目标检测中的正样本分配




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?