

Python网络爬虫——当当网
一.选题背景:
为什么选此题:如今,现代人买书大多都会选择线上购买,然而比较出名的购书网站当当网,在你要搜索想购买的书时,根据输入关键字搜索出来的书本种类繁多,眼花缭乱,对于有些原则困难症的人来说就很难受,不知如何让下手。
预期目标:希望通过我设计的爬取当当网的爬虫代码,捕获出来的书名,价格,出版社等信息,根据信息做可视化分析,作图,给用户提供参考。
二.主题式网络爬虫的设计方案
1.主题式网络爬虫名称
基于网络爬虫爬取当当网
2.主题式网络爬虫爬取的内容与数据特征分析
爬取当当网界面信息,根据关键字搜索想要查找的书名,分析价格,作者出版社,简介等内容。
3.主题式网络爬虫设计方案概述
本爬虫主要从一下几个方面进行设计:导入需要用到的库,创建表格,获取界面,分析需要搜索的书籍的名称title、作者author、价格price、出版社publisher、简介detail等信息
将数据保存至book.csv文件里,然后根据爬取到的数据做可视化分析
三、主题页面的结构特征分析
1.主题页面的结构与特征分析:
首页和他的布局结构

分析当当网的页面分析可以实现交互功能,如用户注册、信息发布、产品展示、订单管理等可以看出这是一个动态网站。
2.Htmls 页面解析:


爬取的页面

3.节点(标签)查找方法与遍历方法
四、网络爬虫程序设计
1.数据爬取和采集:
import urllib.request
import requests
from bs4 import BeautifulSoup
import time
import random
# 随机头
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
]
headers = {
'User-Agent':random.choice(USER_AGENTS),
'Connection':'keep-alive',
'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2'
}
# 创建book.csv
f = open("book.csv", "a")
f.write("书籍" + "," + "价格" + "," + "作者" + "," + "出版社" + '\n')
f = f.close()
def spider(keyword,page):
for i in range(0,page):
count = 0
page = 1
# 获取界面
url = 'http://search.dangdang.com/?key='+str(keyword)+'&page_index='+str(page)
res = requests.get(url, headers=headers)
res.encoding = 'gbk'
soup = BeautifulSoup(res.text,'html.parser')
# print(soup)
div = soup.find("div", attrs={"class": "con shoplist"})
ul = div.find("ul", attrs={"class": "bigimg"})
lis = ul.find_all("li")
print('正在爬取第{}页'.format(page))
for li in lis:
count += 1
# 分析每个<li>中书籍信息:名称title、作者author、价格price、出版社publisher、简介detail、图像image
p = li.find("p", attrs={"class": "name"})
title = p.find("a").text
price = li.find("span", attrs={"class": "search_now_price"}).text
author = li.find("p", attrs={"class": "search_book_author"}).find("span").text
pub = li.find("p", attrs={"class": "search_book_author"}).find_all("span")
#publishers = pub[2].find("a").text
publisher=pub[2].text
detail = li.find("p", attrs={"class": "detail"}).text
# 将数据保存至book.csv文件
with open("book.csv","a",encoding='utf-8') as f2:
f2.writelines(title + "," + price + "," + author + "," + publisher + '\n')
print('\n书籍:',title,'\n价格:',price,'\n作者:',author,'\n出版社:',publisher,'\n简介:',detail)
page += 1
if __name__ == '__main__':
keyword = input('关键字:')
page = int(input('爬取页数:'))
#keyword = 'python'
#page = 1
spider(keyword,page)
运行后的结果:



导入库,和刚刚爬取的数据后保存的文件
import pandas as pd
import numpy as mp
import sklearn
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_excel('book.xlsx',sheet_name='Sheet1')
df
对数据进行清理:
# 清洗重复书名
book = df.drop_duplicates('title')
book

然后发现清理后发现价格栏有Nan值,再进行一次对Nan进行清理
# 对Nan进行清理 book = book.dropna(axis=0) book
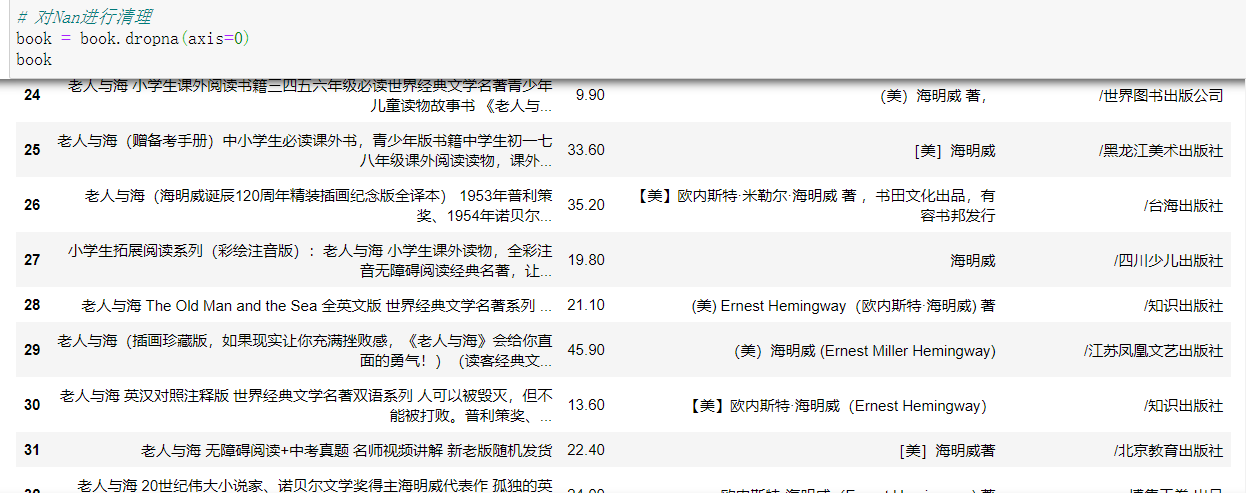
保存清理后的数据然后打开新的数据:
book.to_csv('books.csv',encoding='gb18030') #保存数据清洗后的文件
book = pd.read_csv('books.csv',encoding='gb18030')
book

对爬取到的各出版设占比做饼状图图
# 饼状图
label_list = x
explode = (0,0,0,0.1,0,0)
plt.rcParams['font.sans-serif']=['SimHei']
plt.xticks(rotation=0)
plt.pie(y,labels=label_list,labeldistance=1.1, autopct="%1.1f%%", shadow=False, startangle=90, pctdistance=0.6)
plt.title("出版社饼状图")
plt.axis("equal")
plt.show()

各出版社对书本定价的分布所做的散点图:
# 散点图
plt.scatter(x,y,color='b',marker='o',s=40,edgecolor='black',alpha=0.5)
plt.xticks(rotation=90)
plt.title("出版社散点图")
plt.xlabel("出版社",)#横坐标名字
plt.ylabel("价格")#纵坐标名字
plt.show()

柱状图:
plt.bar(x,y,alpha=0.2, width=0.4, color='green', edgecolor='red', lw=3)
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.title("出版社柱状图")
plt.xticks(rotation=90)
plt.xlabel("出版社",)#横坐标名字
plt.ylabel("价格")#纵坐标名字
plt.show()

import matplotlib.pyplot as plt
# sf数据可视化分析
x = book['publisher']
y = book['price']
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False
plt.plot(x,y,'-',color = 'c',label="单位/元")
plt.xticks(rotation=90)
plt.legend(loc = "best")#图例
plt.title("价格")
plt.xlabel("价格",)#横坐标名字
plt.ylabel("出版社")#纵坐标名字
plt.show()

水平图:
# 水平图
plt.barh(x,y, alpha=0.2, height=0.4, color='r', edgecolor='gray',label='单位/亿', lw=3)
plt.title("价格趋势图")
plt.legend(loc = "best")#图例
plt.xlabel("价格",)#横坐标名字
plt.ylabel("出版社")#纵坐标名字
plt.show()

五.总结
通过以上可视化分析看一大致了解了这本书在不同出版社里,定价的不同。通过饼图可以看出人民文学出版社,商务印书馆,译林出版社,知识出版社等在当当网上占比较多,可以考虑购买这几个出版社所出版的图书。通过散点图和统计图看出这本书的价格在20元左右。这些数据大致可以帮用户分析得到一些数据,可以提供一些数据供用户参考,大致上给到了用户一点建议,与预期的目标还是差了些。
通过这次的课程设计实验,我学习到了要想爬取网站上的信息,必须有一个好的工具。通过本学期的Python课程的学习,使我又进一步了解了Python,Python是一种计算机程序设计语言(解释型语言),具有代码少、简单、运行速度慢的特点。本次课程设计中我也发现了自己的在对Python的运用的很多不足,在课程设计的过程中,我遇到了很多问题,比如很多英文看不懂,我的英文水平还是太差了,今后还要努力学习英语,运行代码是也是经常犯一些很基础的错误,这让我意识到我的基础还不够好,遇到问题首先在网上获取信息,在通过上网查找信息学习过程学习到了将爬取的信息存储到本地,在爬取网站时遇到了被网站的反爬虫程序拦截,通过学习学会了模拟浏览器爬取信息 。在今后,我会在空余的时间里安排时间学习Python。
