
MySQL 索引
mysql的索引是通过B+tree的方式的。B+tree是平衡二叉树的变种,所以查询的速度是非常快的。(B+tree :https://zh.wikipedia.org/zh-hans/B%2B%E6%A0%91)
索引主要分为聚集索引和辅助索引:
聚集索引:mysql中的数据是通过主键的聚集索引储存的,叶子节点中存放的就是每一行的数据,所以我们通过主键进行查询速度
如初快的原因就是主键是聚集索引,而实际使用中只会构建一颗这样的B+tree,所以这就可以解释为什么主键唯一了。
引用网上的图:
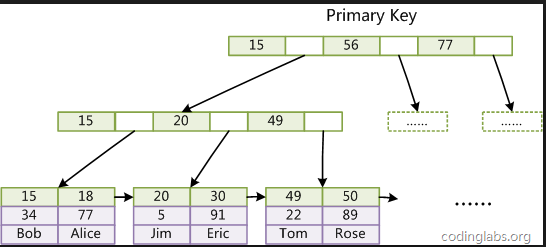
每一层的查找就是一次的IO操作,而一般B+tree层数都在2-4层 所以相当于最差的情况下,只需要做4次的IO操作。
辅助索引:辅助索引和聚集索引不同的地方在于叶子节点中储存的不是全部的数据,储存的是数据所在的位置。相当于我们使用了
辅助索引查找到数据之后,还需要在通过聚集索引的树查找详细的信息。
引用网上的图:
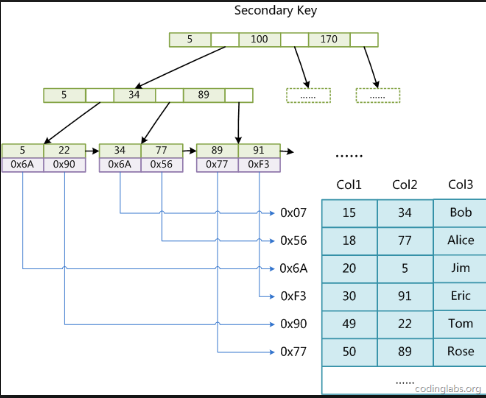
这个图是一个逻辑上的图,但是底层是通过叶子节点指向了所在的聚集索引,也就是说,接下面还需要在走一遍第一种图的
逻辑。
所以最终的是多个辅助索引树指向一个聚集索引树
(画的真tm丑)
关于什么时候应该创索引
因为这是一棵树,通过二分查找的方式来进行检索,所以适用在作为where后面的条件时,并且这个值是很大范围内的,适合创建索引。对于那些范围很小的的(is_delete,sex等等枚举)是不适合的。
对于具体的情况,我们可以通过show index来进行分析:
show index from company_related_person
结果:

然后通过cardinality计算
select 105/(select count(*) from company_related_person) from DUAL
这里得到的结果是0.913(这个数值和储存量有关,最好有一定的数据量) 这个数值越接近1 索引的效率就越高,如果求出的值非常小,建议不要创建索引
我们可以同时可以通过explain查看索引的使用情况
EXPLAIN select * from company_related_person where company_id='2'
输出

key表示的就是当前使用的索引列。最后的extra表示的就是使用何种方式,这里是 Using index 表示的就是使用了索引,如果Using filesort 表示的就是直接读磁盘了
对于那些查询慢的sql复杂语句,可以通过这种方式进行分析。
SQL性能优化的目标:至少要达到 range 级别,要求是ref级别,如果可以是consts最好。
1)consts 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
2)ref 指的是使用普通的索引(normal index)。
3)range 对索引进行范围检索
4) index 表示的是直接去磁盘中读取
从上面的那种图也可以看到我们使用的是ref
关于index和key的区别:
在我们创建索引的时候,经常会有这个疑问,index和key有什么区别?。Key即键值,是关系模型理论中的一部份,比如有主键(Primary Key),外键(Foreign Key)等,用于数据完整性检否与唯一性约束等。而Index则处于实现层面,比如可以对表个的任意列建立索引,那么当建立索引的列处于SQL语句中的Where条件中时,就可以得到快速的数据定位,从而快速检索。至于Unique Index,则只是属于Index中的一种而已,建立了Unique Index表示此列数据不可重复
复合索引
如果你问很多老员工,复合索引中的单列索引是不是每个列都可以作为单独的索引.那么大部分都会回答是。
例如: 一个复合索引: idx_a_b_c (a,b,c)那么请问 单独使用a,b,c的时候是否能够使用索引(where a=?,where b=?,where c=?三种情况),我之前看的书是告诉我只有a能够作为单独索引,但是在工作中很多人告诉我b,c也能单独使用,包括DBA. 所以我建立了一个表,经过测试,只有a能够单独使用索引,b,c是不能使用索引的!!!
下面实例:
复合索引

下面执行语句:
EXPLAIN select * from t_base_account where name ='hotusm'
输出:

可以看到并没有使用索引.
再执行:
EXPLAIN select * from t_base_account where phone ='hotusm'
输出:

也没用使用索引
最后执行最前面的列:
EXPLAIN select * from t_base_account where identity_id ='1'
输出:

可以看到使用了索引。所以最后得出结论,复合索引只有第一个才能作为单独索引。
上面是在InnoDB上面的执行结果.如果我的理解有错,希望有人指出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号