Job作业运行流程
job五大阶段
InputFormat
1.InputFormat --> FileInputFormat --> TextInputFormat
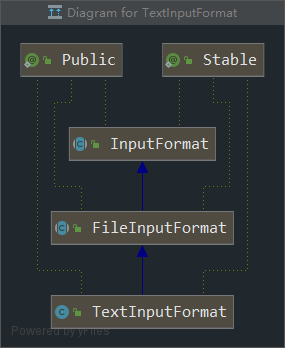
重点:DBInputFormat、KeyValueInputFormat、TextInputFormat
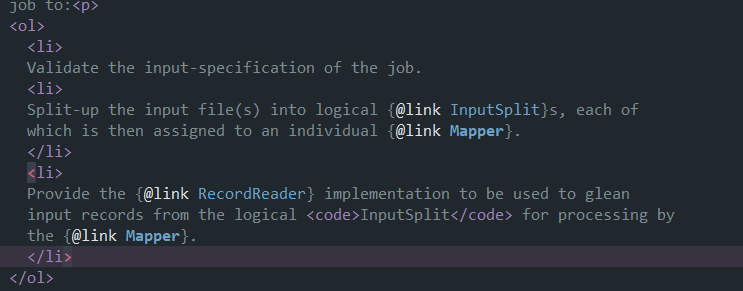
- 为每个job作业验证hdfs上数据(数据是否存在,数据相关格式)
- 根据数据块(block)划分成一个逻辑上的split(切片)一个切片对应一个map block-->split-->map
- 切片的具体实现。如果文件小于128m,一个切片;如果(文件大小/128)<1.1,单独切一片。

- 读取切片
Mapper
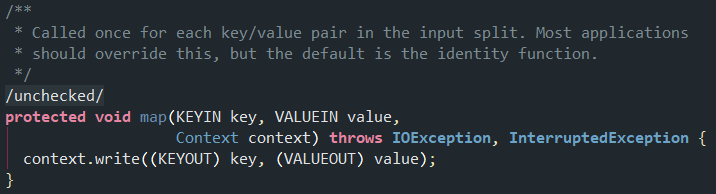
1.核心方法
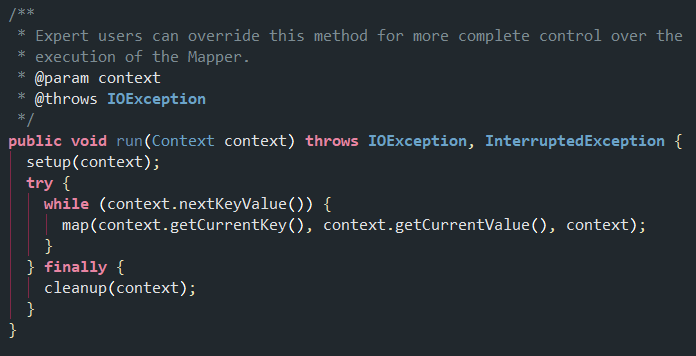
2.自定义mapper一般都是覆盖map函数
Shuffle
Shuffle = Map Shuffle + Reduce Shuffle
1.Map端的shuffle

2.Reduce端的shuffle

整体来说shuffle横跨了map和reduce两个阶段。从2-7,map task和reduce task之间的数据流称为shuffle(混洗),其中过程5最能体现。

- 分区是在Map输出到缓冲区时(2)执行的
- 环形缓冲区默认100M,当数据超过80%时,就溢写到本地磁盘。注意,在缓冲区中程序会对数据进行分区,默认为哈希分区和key快排。此时(3)发生合并
- 当磁盘破碎文件达到一定阈值或者map端停止向缓冲区写入的时候,会将磁盘上的文件再进行一次合并(4)
- 通过http协议将map端的执行结果传输到reduce(5)
- 在reduce端执行一次合并汇总再次排序(6)
Reduce
三个阶段
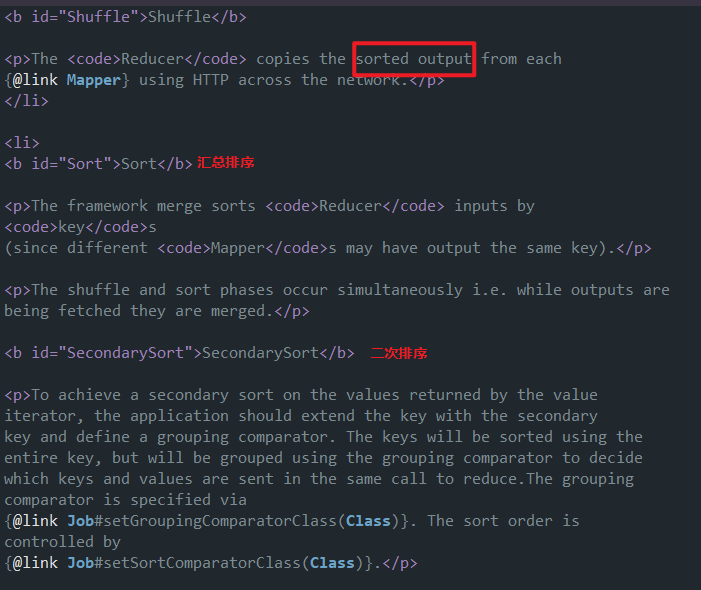
1.shuffle阶段
通过http协议将多个map执行的排序结果传输汇总在一起
2.sort阶段
将多个map执行文件再一次合并排序
3.SecondarySort阶段
当启用Combiner时,map阶段也会有reduce,此时在map阶段会有一次排序,汇总到Reducer阶段时,将结果再次排序。
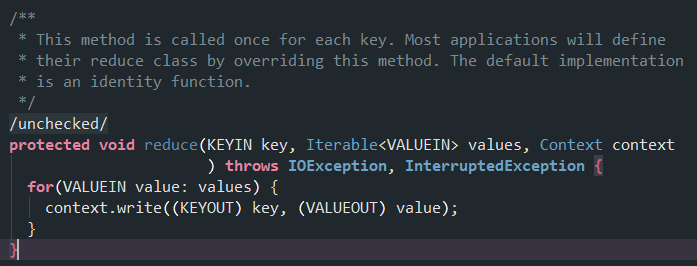
核心方法

自定义reducer时一般会重写reduce函数
OutputFormat
在TextOutputFormat中,默认的分隔符是“\t”,将结果以 key + "\t" +value写入文本文件

job作业提交过程
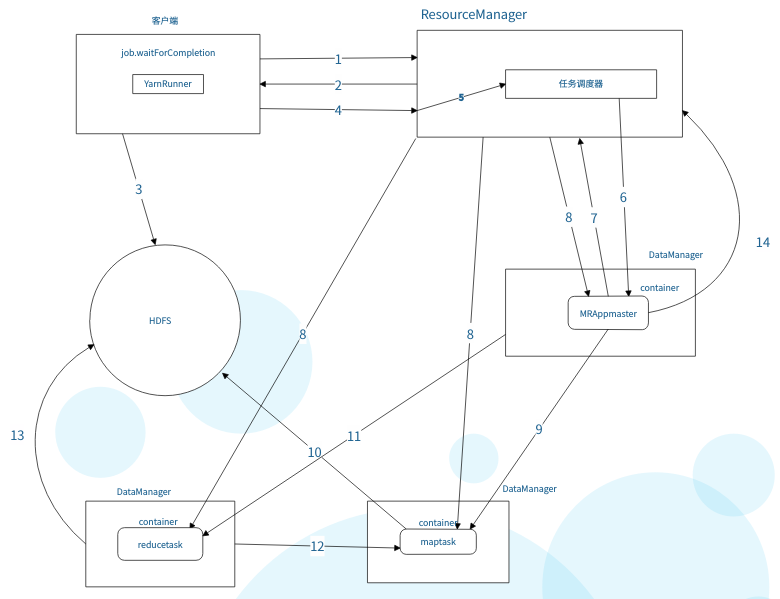
客户端的配置信息mapreduce.framework.name为yarn时,客户端会启动YarnRunner(yarn的客户端程序),并将mapreduce作业提交给yarn平台处理。
1.向ResourceManager请求运行一个mapreduce程序。
2.ResourceManager返回hdfs地址,告诉客户端将作业运行相关的资源文件上传到hdfs。
3.客户端提交mr程序运行所需的文件(包括作业的jar包,作业的配置文件,分片信息等)到hdfs上。
4.作业相关信息提交完成后,客户端用过调用ResourcrManager的submitApplication()方法提交作业。
5.ResourceManager将作业传递给调度器,调度器的默认调度策略是先进先出。
6.调度器寻找一台空闲的节点,并在该节点隔离出一个容器(container),容器中分配了cpu,内存等资源,并启动MRAppmaster进程。
7.MRAppmaster根据需要运行多少个map任务,多少个reduce任务向ResourceManager请求资源。
8.ResourceManager分配相应数量的容器,并告知MRAppmaster容器在哪。
9.MRAppmaster启动maptask。
10.maptask从HDFS获取分片数据执行map逻辑。
11.map逻辑执行结束后,MRAppmaster启动reducetask。
12.reducetask从maptask获取属于自己的分区数据执行reduce逻辑。
13.reduce逻辑结束后将结果数据保存到HDFS上。
14.mapreduce作业结束后,MRAppmaster通知ResourceManager结束自己,让ResourceManager回收所有资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号