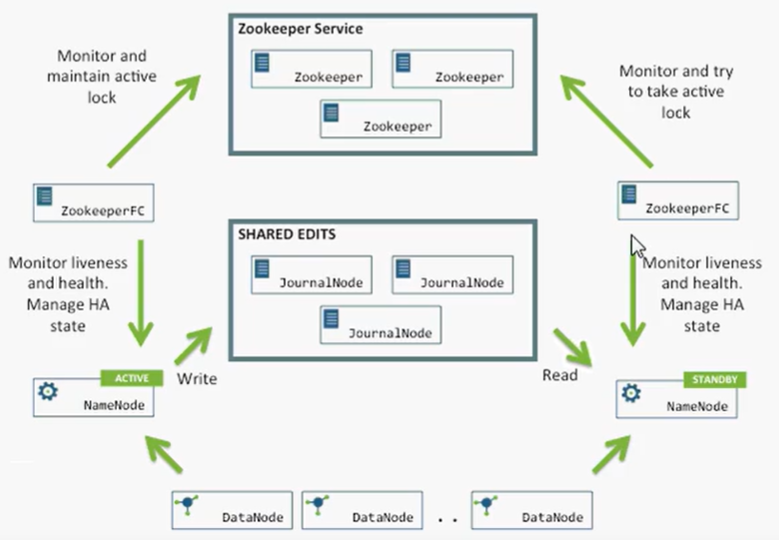
ZooKeeper实现HA HDFS
单节点NameNode存在问题:
- NameNode宕机,metadata数据消失;
- 单节点出现故障,如何进行故障转移?
- 如果增加一个NameNode节点,会出现脑裂问题(一个集群有多个管理者),如何解决?
ZK搭建高可用(HA High Aliavble)HDFS集群
- QJM(Quorum Jouranl Manager)是Hadoop转为为NameNode共享存储开发的组件。其集群运行一组Journal Node,每个Journal节点暴露一个简单的RPC接口,允许NameNode读取和写入数据,数据存放在Journal节点的本地磁盘。
- 故障转移问题上,引入了监控NameNode状态的ZookeeperFailController(ZKFC)。ZKFC一般运行在NameNode宿主机器上,与Zookkeeper集群写作完成故障的自动转移。
Journal Node两大作用
- 同步NameNode们的editlog
- 当出现脑裂情况时,触发隔离机制,将其中一个NameNode节点kill掉(例如,NameNode1出现网络延迟,ZooKeeper认为它宕机了,ZKFC将NameNode2由standby转为active状态,此时,就有两个NameNode处于active状态,出现脑裂情况,Journal Node就会触发隔离机制,将剩余NameNode1的写入操作执行完毕之后,会通过SSH登录NameNode1节点将其进程关闭)
ZK集群
通常需要开辟三个独立端口
- 1:处理client请求
- 2:集群内部原子广播
- 3:集群内部选举投票

ZK集群创建
1.安装zookeeper
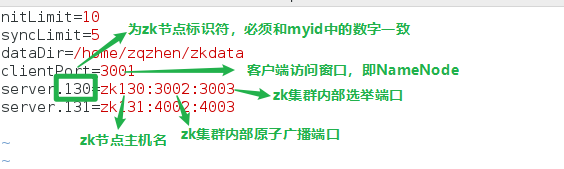
2.在每个zk节点创建数据目录,每个数据目录中必须有myid文件,用来唯一标识zk节点
3.数据目录中创建zoo.cfg的配置文件
启动zk服务
1 ./zkServer.sh start /root/zkdata/zoo.cfg
查看集群状态
1 ./zkServer.sh status /root/zkdata/zoo.cfg
HA HDFS集群启动前提
在hdfs集群各个节点中的core-site.xml配置namenode,因为已经不是单namenode节点,所以要将hdfs入口稍作修改。以及添加zk监控hadoop的配置。


1 <property> 2 <name>fs.defaultFS</name> 3 <value>hdfs://ns</value> 4 </property> 5 <property> 6 <name>hadoop.tmp.dir</name> 7 <value>/home/zqzhen/hadoop-2.9.2/data</value> 8 </property> 9 <property> 10 <name>ha.zookeeper.quorum</name> 11 <value>zk1:3001,zk2:3001</name> 12 </property>
在hdfs-site.xml中修改相应的namenode别名,启动journal,以及启动隔离机制等等配置。
1 <property> 2 <name>dfs.nameservices</name> 3 <value>ns</value> 4 </property> 5 <property> 6 <name>dfs.ha.namenodes.ns</name> 7 <value>nn1,nn2</value> 8 </property> 9 <property> 10 <name>dfs.namenode.rpc-address.ns.nn1</name> 11 <value>hadoop120:9000</value> 12 </property> 13 <property> 14 <name>dfs.namenode.http-address.ns.nn1</name> 15 <value>hadoop120:50070</value> 16 </property> 17 <property> 18 <name>dfs.namenode.rpc-address.ns.nn2</name> 19 <value>hadoop121:9000</value> 20 </property> 21 <property> 22 <name>dfs.namenode.http-address.ns.nn2</name> 23 <value>hadoop121:50070</value> 24 </property> 25 <property> 26 <name>dfs.namenode.shared.edits.dir</name> 27 <value>qjournal://hadoop120:8485;hadoop121:8485;hadoop122:8485/ns</value> 28 </property> 29 <property> 30 <name>dfs.journalnode.edits.dir</name> 31 <value>/home/zqzhen/journal</value> 32 </property> 33 <property> 34 <name>dfs.ha.automatic-failover.enabled</name> 35 <value>true</value> 36 </property> 37 <property> 38 <name>dfs.client.failover.proxy.provider.ns</name> 39 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 40 </property> 41 <property> 42 <name>dfs.ha.fencing.methods</name> 43 <value>sshfence</value> 44 </property> 45 <property> 46 <name>dfs.ha.fencing.ssh.private-key-files</name> 47 <value>/root/.ssh/id_rsa</value> 48 </property>
启动集群步骤
首先要在namenode的任意节点启动zk集群
hdfs zkfc -formatZK
其次启动journalnode节点,必须要比namenode先启动,这样才能保证同步namenode的写入与读取操作
hadoop-daemon.sh start journalnode
接着在namenode active节点执行namenode的格式化,其中xx为之前在core-site.xml中为namenode们起的别名
hdfs namenode -format xx
然后启动hdfs集群
start-dfs。sh
在namenode standby节点执行预备格式化操作,否则该机器启动不了namenode
hdfs namenode -bootstrapStandby
在namenodestandby机器上启动namenode
hadoop-daemon.sh start namenode

