如何评价腾讯开源的消息中间件TubeMQ?
周五晚上无聊,粗粗撸了一遍代码+性能测试文档,随便扯扯吧。主要分为亮点、槽点、瓶颈分析三块,理解有问题的话欢迎大家指出来。
亮点
-
结构相对清晰,流程简单一目了然
-
每个分区一个逻辑存储的设计,在一定程度上增大了写盘之前处理的并发数(这点会在瓶颈分析部分)
-
自建缓存的设计使得写盘相对可控,不会污染pagecache导致写放大
槽点
-
不可靠。没有落盘就进行ack,在大多数金融级场景里不可接受
-
相对kafka和RocketMQ作为已有产品,解决的问题不够清晰(详见瓶颈分析)
-
多副本没开源。。。其实最早看的动力就是想看下这一块
-
性能测试文档分析有点粗暴,没有对数据结果进行更进一步分析,以及针对已有数据设计更多更有针对性的场景
瓶颈分析
由于某些不可描述的原因,为了避免麻烦,暂时不能详细说解决方案,但是说瓶颈应该没啥问题。由于多副本尚未开源,以下仅讨论存储引擎部分。
背景
分析瓶颈之前,先介绍下各种消息队列存储模型以方便后续分析。
kafka
每一个partition都有日志和索引文件,如下图所示。kafka的瓶颈主要在于,当单机分区数增加或者强制写盘次数增加时,随机写带来的开销。这一点由于机械结构的磁盘需要寻道,会导致表现的特别明显。
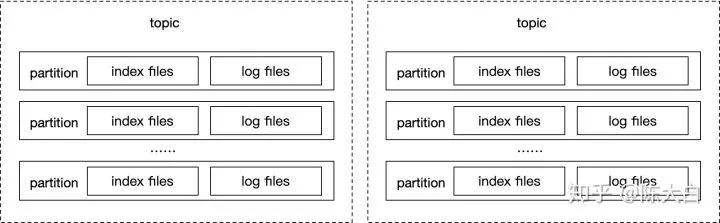
所以kafka的瓶颈主要在于:
-
不适合单机多主题多分区的场景;
-
不适合可靠性要求高的场景(强制刷盘后返回);
RocketMQ
全局顺序日志,逻辑索引,索引可以通过日志进行重建。所以在高可靠场景下(每条消息必须刷盘),即使单机的分区数很多,也不会大幅度影响性能。
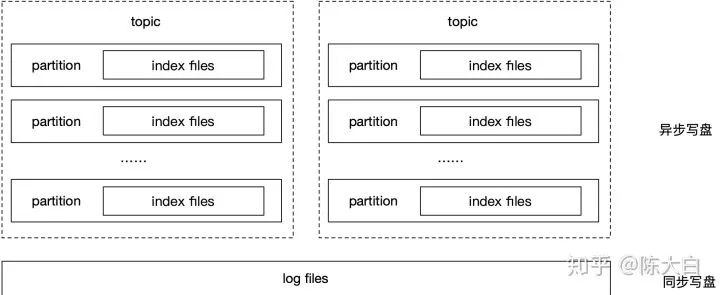
RocketMQ的缺点主要在于:
-
由于要保证日志和索引文件顺序一致,锁加在了最外面,导致内存的追加、序列化、获取索引偏移量、获取日志偏移量只能单线程执行;这种设计导致cpu主频高低直接影响tps,并且在cpu核数提升的情况下提升不明显(以上分析均以IO不是瓶颈的情况下讨论,实际上小流量RocketMQ也跑不到IO瓶颈)
-
虽然做了组提交(刷盘),但是效果不明显。同步写盘的模式下,当消息比较小时,有明显的写放大
JMQ4
JMQ4[1]的突出设计就是综合了kafka和RocketMQ的存储模型。
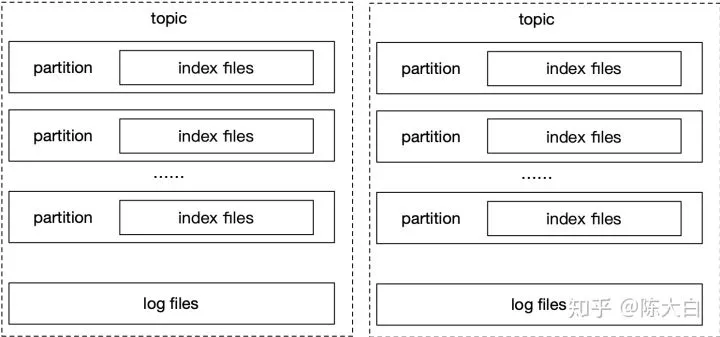
对于单个主题的多个分区,JMQ4写同一个日志文件;而对于不同的主题,则采用不同的日志文件进行存储。
-
如果broker只有一个主题,则相当于RocketMQ模型
-
如果broker有多个主题,每个主题一个分区,则相当于Kafka每个主题在此broker上只有一个分区时的模型
特点:
-
在一定程度上缓解了Kafka在多主题下的劣势;
-
同时在多主题时提升了一部分并行度解决了RocketMQ的单线程瓶颈;
-
同时还可以保证高可靠。
TubeMQ
TubeMQ存储结构如下:
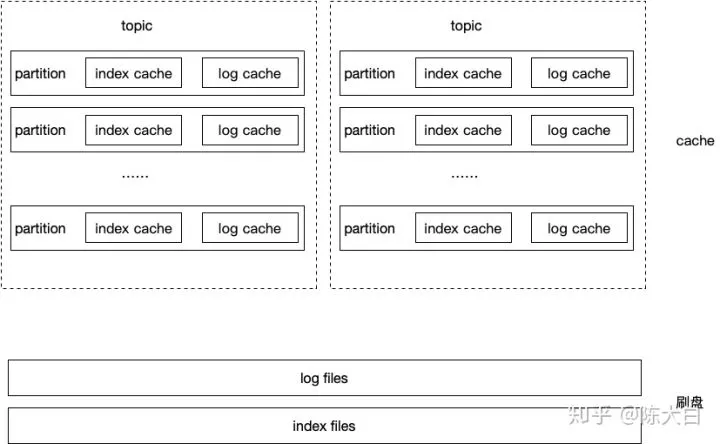
-
实际采用全局的日志文件和索引文件存储,类似RocketMQ,因此一定程度上避免了kafka在分区数增加时性能下降的问题(尤其在机械结构的磁盘上)
-
每个分区单独的逻辑模型,锁仅仅加在patition级别,在写磁盘之前模型可以认为就是kafka的分区模型,因此解决了RocketMQ的单线程处理问题。当然采用全局日志文件的话写磁盘肯定要加锁,从全局来看相当于细化了90%以上的锁粒度
-
自建的索引层+异步写盘模式保证了写放大不会太厉害,且不会污染pagecache。(当然有槽点未竟全功,因为某些原因不能细说哈哈)
通过以上分析,是不是感觉很完美?其实相对于Kafka和RocketMQ,TubeMQ由于写内存成功就返回,导致不可靠,从而导致解决的问题并不够清晰
-
如果需要高可靠,我会选择RocketMQ或者JMQ4(可能未开源?不太了解)
-
如果能接受丢失消息,随着ssd价格下降,无疑kafka就是个很好的选择(在ssd情况下,异步刷盘,kafka的弱点基本被掩盖)
JMQ4,kafka,TubeMQ还有个共同的问题,单线程瓶颈通过多个逻辑分区/日志进行解决,并不能真正的解决问题。考虑一个实际问题,一个broker往往存在热点分区或者主题,占了总流量很高的比例。以上解决方案对于特定的某个热点分区,还是只能单线程处理,而其他资源只能浪费。换言之,构建一个场景,100个主题,1个流量占90%,其余99个占10%.压测数据会比100个主题平分流量出现明显的下降。
压测数据分析
背景介绍完以后,我们来看压测场景[2]
场景一:基础场景,单topic情况,一入两出模型,分别使用不同的消费模式、不同大小的消息包,分区逐步做横向扩展,对比TubeMQ和Kafka性能
TubeMQ吞吐量不随分区变化而变化,同时TubeMQ属于顺序写随机读模式,单实例情况下吞吐量要低于Kafka
单主题单分区的情况下,大家模型退化成一样(甚至TubeMQ因为自建缓存写入更可控)。kafka在200B,2k,1k三种单主题单分区场景性能均高了70%左右。如此稳定的表现(尤其在模型相似的情况下),难道不应该着重分析下瓶颈,就这样一带而过?虽然知道,但是不方便说emmmm
场景二:单topic情况,一入两出模型,固定消费包大小,横向扩展实例数,对比TubeMQ和Kafka性能情况
TubeMQ随着实例数增多,吞吐量增长,在4个实例的时候吞吐量与Kafka持平,磁盘IO使用率比Kafka低,CPU使用率比Kafka高;Kafka随分区实例数增多,没有如期提升系统吞吐量;TubeMQ按照Kafka等同的增加实例(物理文件)后,吞吐量量随之提升,在4个实例的时候测试效果达到并超过Kafka 5个分区的状态
我们来看下数据

TubeMQ 4个实例4个10个分区和kafka比有点欺负人哈哈。
参见上一节,相当于在写盘之前,TubeMQ有40个线程在工作,kafka应该调整成40个分区比才有意义(否则结果理论分析就行)。当然因为还要换成ssd,因为上图kafka瓶颈明显在机械盘的随机写上,不用ssd也没有太多测试价值。
场景八:评估多机型情况下两系统的表现
在SSD盘存储条件下,Kafka性能指标达到最好,TubeMQ指标不及Kafka;
其余场景都是老调重弹,懂了模型基本都在预期之内。要跟kafka比的话,除非用单分区,否则其它场景确实用ssd才更有意义。指标不及kafka正常应该分析下原因,这才是压测的意义吧。
在SATA盘存储条件下,TubeMQ性能指标随着硬件配置的改善有明显的提升;Kafka性能指标随硬件机型的改善存在不升反降的情况;
“Kafka性能指标随硬件机型的改善存在不升反降的情况”这个结论得到的有点不负责任。。。TS60机型测的是1-100个主题,BX1机型测的是500个主题,性能降低原因很明显(机械盘分区变多寻道时间增加)。。
就写到这里吧,最后安利下我们的MQ,以下均为机械磁盘,500B消息,同机房延迟0.04-0.1ms左右:
-
单主题即能写满磁盘IO,完全解决了以上单线程瓶颈,几乎没有写放大(压测场景)
-
保证消息可靠(每条消息同步刷盘)的情况下50w tps,平均响应时间6ms;10w tps以下平均响应时间2ms
-
主从同步双写再回复客户端的情况下tps 40w+
-
同机型,单主题单机性能物理机是RocketMQ,kafka的4-5倍,虚拟机是RocketMQ的10倍
emmm,可惜没开源,不配拥有姓名哈哈,至于ssd情况下异步能不能达到百万tps。。。下个月有了结果来更新。
参考资料:
[1]如何实现百万TPS?详解JMQ4的存储设计
[2]TubeMQ VS Kafka性能对比测试总结
原文:https://www.zhihu.com/question/346540432/answer/895769818
