第四章-指令系统
指令系统
机器指令
基本概念
machine language instructions directly control a computer's central processing unit (CPU). Each instruction causes the CPU to perform a very specific task, such as a load, a store, a jump, or an arithmetic logic unit (ALU) operation on one or more units of data in the CPU's registers or memory.
机器指令直接控制着CPU的行为。每一条指令将会使得CPU实现一个任务,例如:一次载入,一次存储,一次跳转,或者对寄存器或者内存中数据的一次ALU的操作。
指令格式
基本格式

操作码
操作码:指明该指令所要完成的操作。
- 长度固定的操作码便于硬件设计,指令译码时间段,广泛应用于字长较长的,大中型计算机和超级小型计算机以及ROSC中。
- 长度不固定的操作码,其操作码分散在指令字的不同字段中,这种格式可有效地压缩操作码的平均长度,在字长较短的微型计算机中被广泛使用。
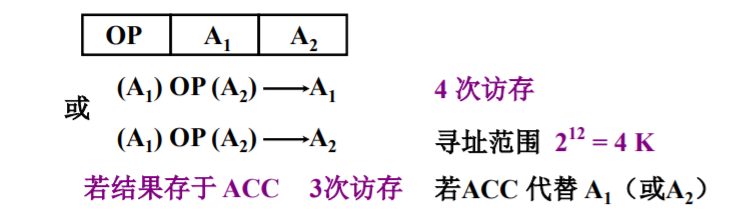
扩展操作码技术
操作码长度不固定会增加指令译码以及分析的难度。一般采用扩展操作码技术实现长度不固定的操作码。
实现:使操作码的长度对地址数的减少而增加,可以将不同地址数的操作码进行合理分配。
Eg:
如下图,使得字长为16位的指令,可以表明61条指令。有效的压缩了指令字长,又实现了译码的简单化。
值得注意的一点是:
- n地址码减少一种,n+1地址码就会增加 2地址字长 种。
地址码
地址码:该指令的源操作数的地址,结果的地址,下一条指令的地址。
地址的类型可以是主存地址,可以是寄存器地址,甚至是I/O设备的地址。
四指令地址
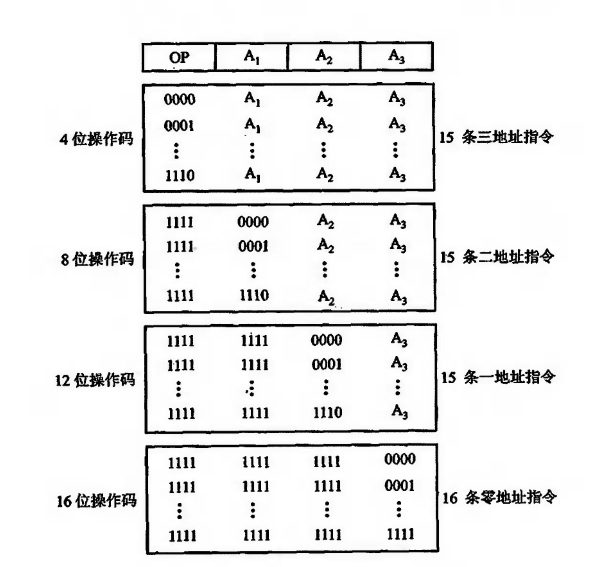
三指令地址

二指令地址

一指令地址

无指令地址
有些指令不需要操作数(eg:空操作,停机),或者操作数已经由该指令隐含表示(eg:程序返回,中断返回)。
当用一些硬件资源承担指令字中需要指明的地址码,可以在不改变指令字长的前提下,扩大指令操作数的寻址范围。
使用一些硬件资源来进行数据的存储,可减少访存次数。
当然了二者都可以缩短指令字长。
操作数与操作种类
操作数类型与表示
操作数类型(数据结构):面向应用、面向软件系统所处理的各种数据结构。 一般有:无符号整数,定点数,浮点数,ASCII,图,树,表等等。
操作数表示(数据表示):硬件结构能够识别、指令系统可以直接调用的那 些结构。一般有:无符号整数,浮点数,定点数等等。
一般而言,操作数表示是操作数类型的一个子集。
确定操作数表示实际上也是软硬件取舍折衷的问题。
- 一旦存在一个操作数表示,必然需要硬件可以支持对于该操作数的操作。
- 计算机即使只具有最简单的操作数表示,如只有整数 (定点)表示法,也可以通过软件方法处理各种复杂 的操作数类型,但是这样会大大降低系统的效率。
- 如果各种复杂的操作数类型均包含在操作数表示之中, 无疑会大大提高系统的效率,但是所花费的硬件代价也很高。
在计算机中,所有的数据都是以01字符串的形式进行表示,对于某个01字符串的类型确定一般取决于指令中操作码的种类。
也可以直接给数据添加标识(flag),虽然说这种方法有许多优点,但是需要在程序执行过程中,动态地检测标识符,动态开销比较大,因而就放弃了这种问题。
数据在存储器中的存放方式
边界对准存放方式
该存放方式的形式如下图
- 如果需要寻求某个长度的数据存储,可以依据地址的某尾0的个数进行判断。eg:双字的地址是8的整数倍,那么其起始地址的后三位必须为0.

边界未对准存放方式
该存放方式的形式如下图
- 该存放方式对于字长较长的数据进行存取时,需要读取两次存储器,而后还需要对高低字节的位置进行调整,才能求得相应的数据,如下图的阴影部分的数据。
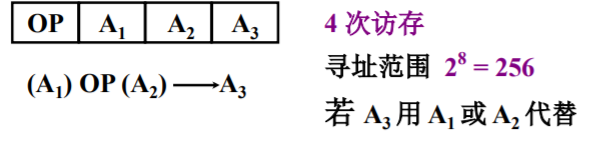
比较
-
边界对准存放方式较为直观,而且存取较为简单
-
边界未对准存放方式会充分利用存储器空间,但存放较大规模数据较为复杂。
操作类型
数据传送
| 源 | 寄存器 | 寄存器 | 存储器 | 存储器 |
|---|---|---|---|---|
| 目的 | 寄存器 | 存储器 | 寄存器 | 存储器 |
| Eg | MOVE | STORE,MOVE,PUSH | LOAD,MOVE,POP | MOVE |
MOVE指令根据后缀进行判断存储源位置以及目的位置类型。
算法逻辑
- 算数操作:加、减、乘、除、增 1、减 1、求补、浮点运算、十进制运算
- 逻辑操作:与、或、非、异或、
- 位操作:位测试、位清除、位求反........
移位
算数移位,逻辑移位,循环移位(带进位和不带进位)
转移
- 无条件移位,Eg:JMP
- 条件移位,Eg:JZ(结果为0跳转), JO(结果溢出跳转), JC(结果有进位跳转), SKP(跳过一条指令)
- 调用与返回。
- 陷阱(意外事故的中断)。
输入输出
-
由端口地址到CPU寄存器
-
由CPU寄存器到端口地址
寻址方式
数据寻址:确定本条指令的操作数地址
指令寻址:确定下一条欲执行指令的指令地址
下面主要介绍数据寻址的寻址方式。
一般而言,指令的地址码字段都不代表操作数的真实地址,而一般称其为形式地址,记作A,而其真实地址为EA,EA由寻址方式与形式地址共同确定。
对于寻址方式的总结

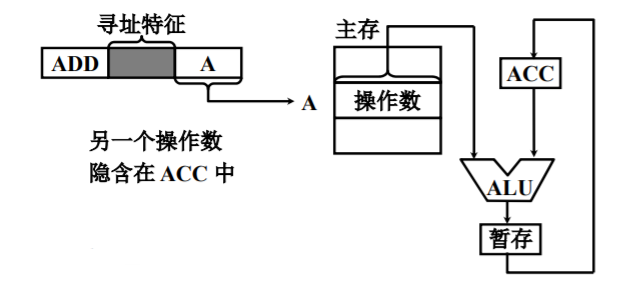
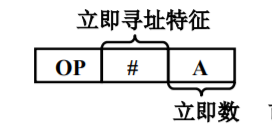
立即数寻址
直接将操作数本身放在形式地址的位置,即形式地址A就是操作数本身,采用补码进行存放。
其寻址特征一般为‘#’。
- 只要取出指令,便可立即获得操作数,不必访问存储器。
- 形式地址A的位数限制了所能表示立即数的范围
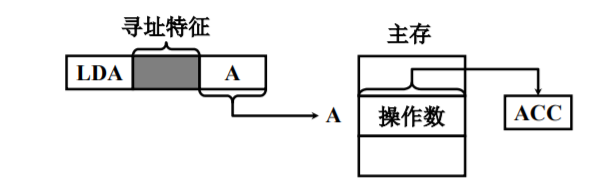
直接寻址
形式地址A 就是操作数的真实地址EA。
- 执行阶段访问一次存储器
- A的位数决定了该指令操作数的寻址方位
- 操作数的地址不易修改
隐含寻址
操作数的地址不显式地给出,而是隐含在操作码或者某个寄存器中。一般而言,其隐含的地址为某个寄存器的地址。
- 指令字中少了一个地址字段,可缩短指令字长
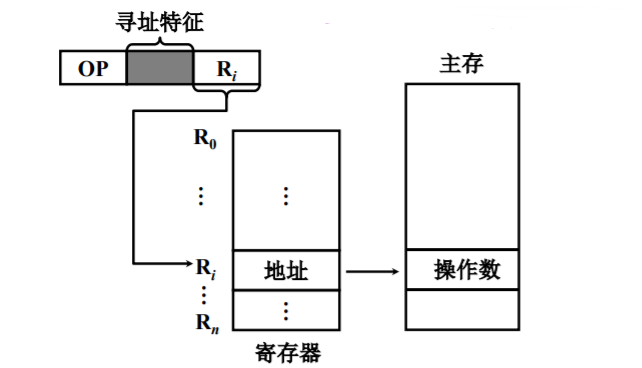
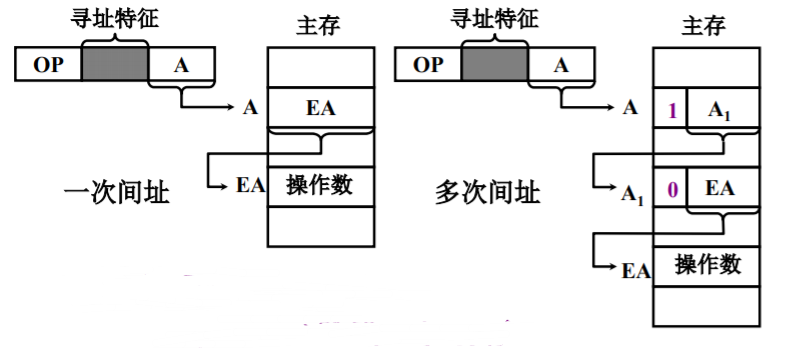
间接寻址
形式地址是:操作数的有效地址所在的存储器单元地址。
- 执行指令阶段需要2次访存,指令执行时间较长。
- 扩大寻址范围,A的位数通常会小于指令字长,而指令字长等于存储字长。
- 便于编制程序,使用简洁寻址便于处理子程序返回的问题,当主程序调用多次某一子程序时,每次调用仅仅需要修改操作数即可,不必改变指令内容。
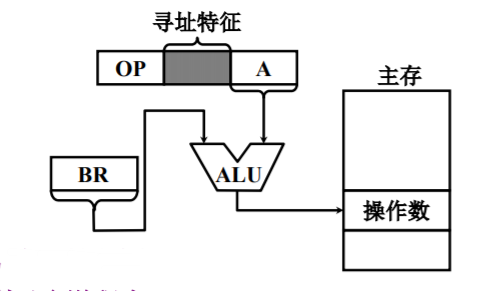
寄存器寻址
形式地址是:寄存器的地址,该寄存器中存放操作数。也就是该指令将使用寄存器进行数据的存储。
- 执行阶段不需要访存,只访问寄存器,执行速度较快
- 寄存器个数有限,可缩短指令字长
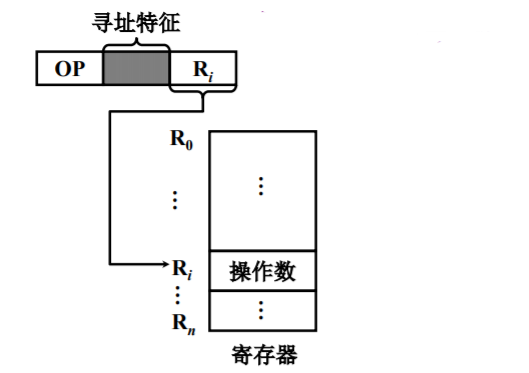
寄存器间接寻址
形式地址是:寄存器的地址,该寄存器中存放操作数的有效地址所在的存储器单元地址。
- 较间接寻址少访问存储一次。
- 具备间接寻址的优点。
基址寻址
基址寻址需设有基址寄存器,其操作数的有效地址为:形式地址与基址寄存器的地址(基地址)相加。
- 基址寻址有利于扩大操作数的寻址范围。因为基址寄存器的地址可以大于形式地址的位数,二者相加可以有效扩大操作数的寻址范围。例如:将主存空间分成若干段,每段首地址存于基址寄存器内,段内的位移量由形式地址给出。
- 基址寻址在多道程序中极为有用。用户不必考虑自己的程序存于主存的那一空间区域,完全可以由操作系统或者管理程序根据主存的物理地址,将用户的程序安置于主存的任一部分。而用户只需要给出形式地址(逻辑地址),就可以进行访问。
采用专用寄存器作基址寄存器(隐式)
- 基址寄存器内容由操作系统或管理程序确定
- 在程序的执行过程中基址寄存器内容不变,形式地址 A 可变
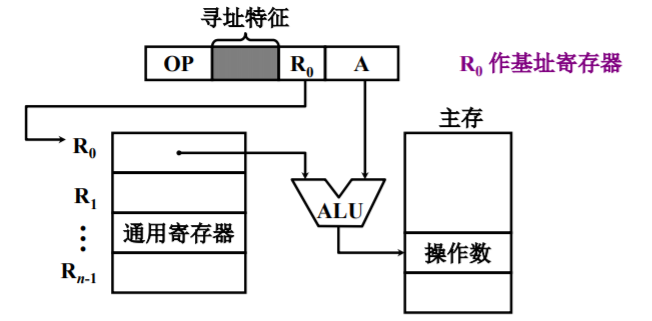
采用通用寄存器作基址寄存器(显式)
- 由用户指定哪个通用寄存器作为基址寄存器
- 基址寄存器的内容由操作系统确定
- 在程序的执行过程中 R0 内容不变,形式地址 A 可变
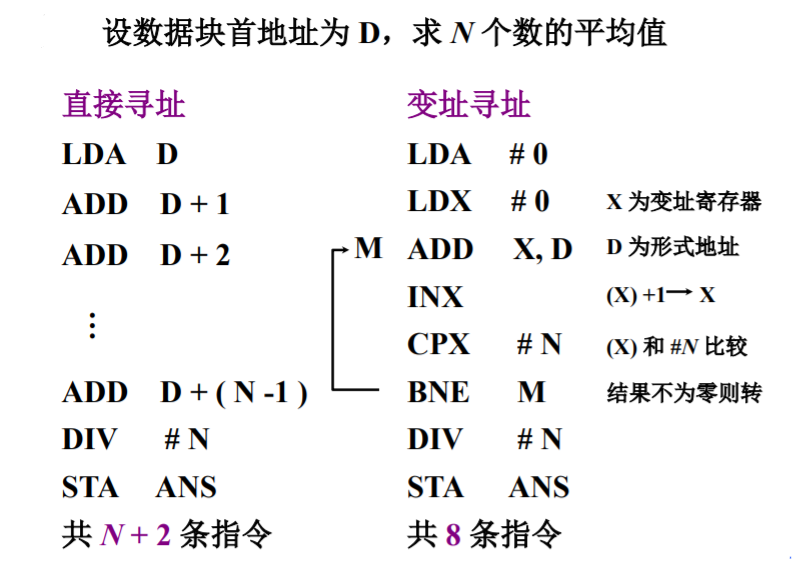
变址寻址
变址寻址需设有变址寄存器,其操作数的有效地址为:形式地址与变址寄存器的地址(基地址)相加。
这与基址寻址极为类似。
基址寻址与变址寻址的区别
- 基址寻址主要用于为程序和数据分配存储空间,故基址寄存器的内容通常由操作系统或者管理程序进行确定,在程序执行过程中不可变,而指令字中A可变。
- 变址寻址主要用于处理数组问题,的变址寄存器的内容由用户设定,而指令字中的A不可变。在数组处理问题中,可设定A为数组首地址,不断修改变址寄存器中的地址,很容易形成数组中任意数据的地址,适合编制循环程序。
下面为使用变址寄存器编制循环的例子:其中直接寻址需要N+2条指令,而变址寻址仅仅需要8条。
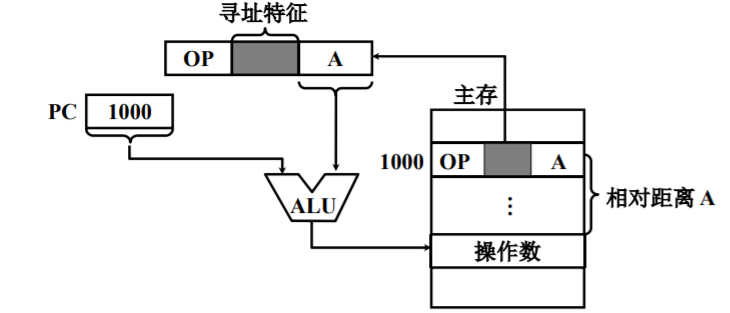
相对寻址
有效地址为:程序计数器PC的内容与指令字中的形式地址相加结果。
- 常用于转移类指令,转移后的目标地址与当前指令之间存在一段相对距离。
- A的位数决定的该寻址方式的寻址范围。
- 转移地址不固定,可随PC值变化而变化,无论程序在主存的那段区域,都可正确运行,对于编写浮动程序比较有利。
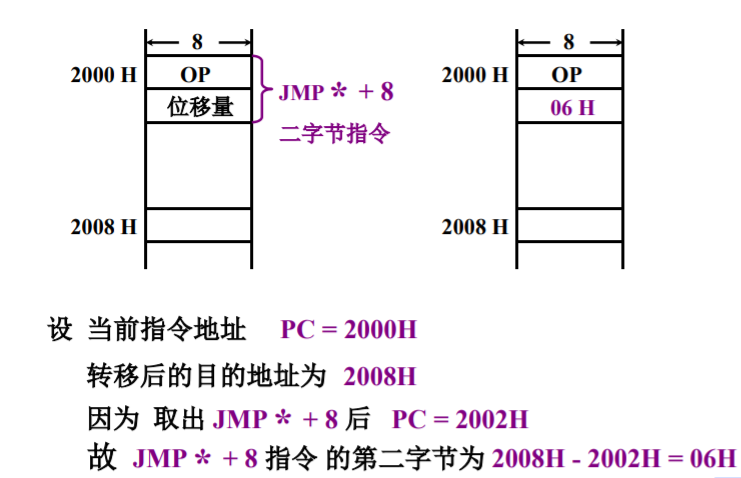
对于编制这类寻址,需要注意:当前指令PC的地址是下一条指令的地址。
参见下面的例子
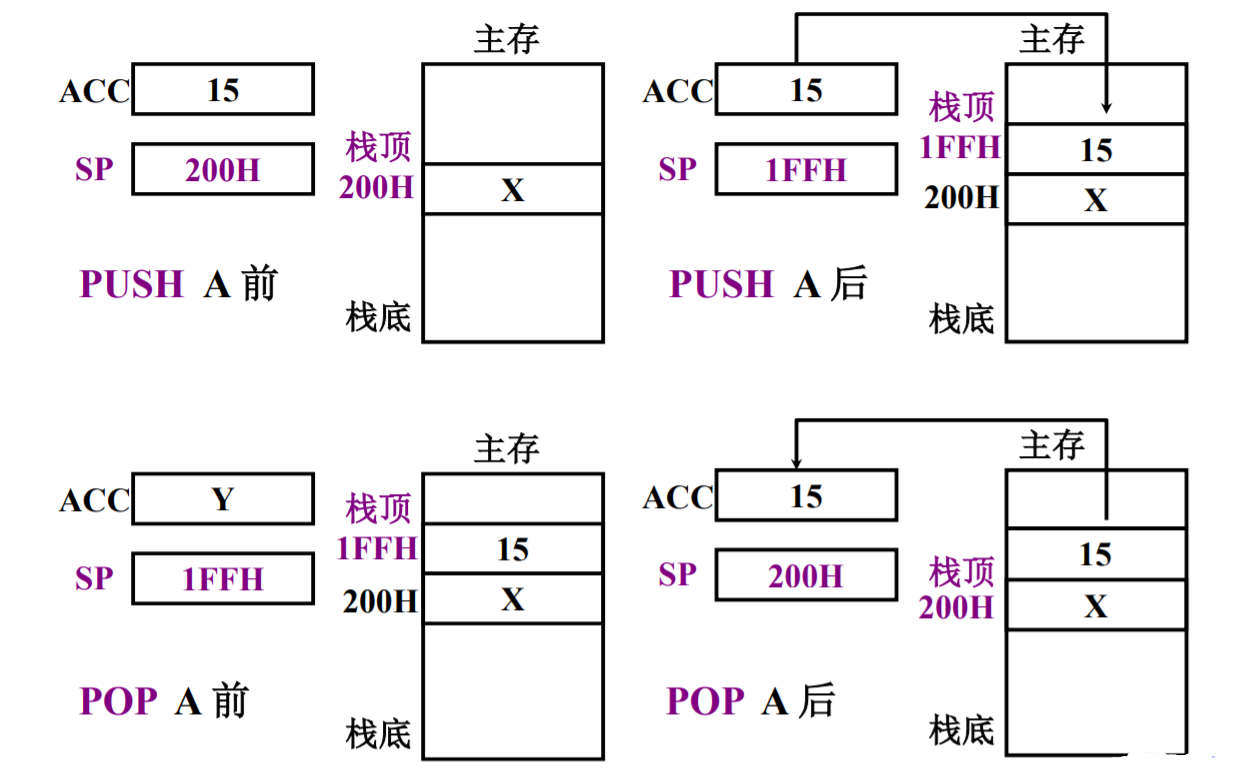
堆栈寻址
直接将数据压栈或者出栈。
软堆栈:使用内存的一部分空间作为堆栈
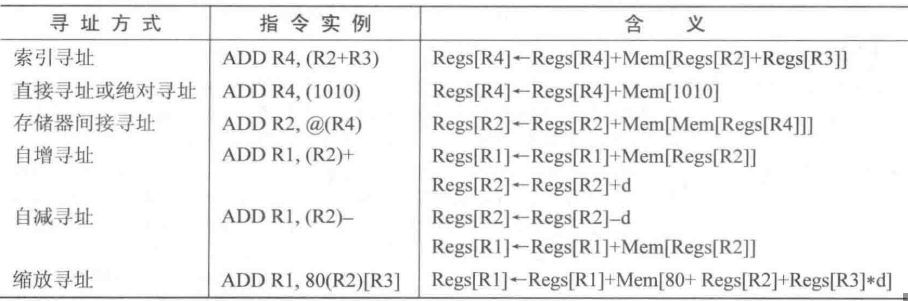
自增寻址
- 指令实例:Add R1, (R2)+
- 含义:
- Regs[R1]←Regs[R1]+Mem[Regs[R2]]
- Regs[R2]←Regs[R2]+d
自减寻址
- 指令实例:Add R1, -(R2)
- 含义:
- Regs[R2]←Regs[R2] - d
- Regs[R1]←Regs[R1] + Mem[Regs[R2]]
缩放寻址
- 指令实例:Add R1, 100(R2)[R3]
- 含义: Regs[R1]←Regs[R1]+Mem[ 100+Regs[R2]+Regs[R3]*d ]
指令系统结构的分类
可以从指令系统的具体实现,更为精确的是,CPU中存储操作数的方式将指令系统结构划分为三类:
- 堆栈型结构,CPU的存储单元为堆栈
- 累加器型结构,CPU的存储单元为累加器
- 通用寄存器型结构,CPU的存储单元为通用寄存器
在通用寄存器型结构中,依据操作数来源的不同,又可以进一步划分为
- 寄存器-存储器型结构(RM)。ALU指令的操作数可以来源于存储器,也可以来源于寄存器。
- 寄存器-寄存器型结构(RR)。ALU指令的操作数只能来源于寄存器。
此时,仍然可以进行进一步的划分,依据ALU指令的操作数的个数以及ALU指令操作数中可以来源于存储器的操作数个数可以进行进一步的划分。
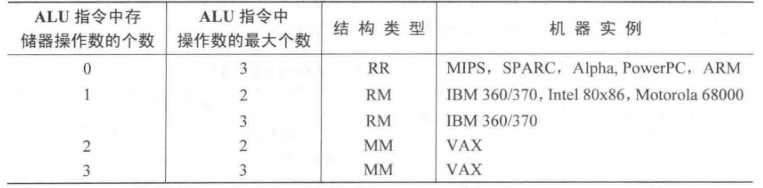
这里所指的ALU指令可以认为是一般的计算指令,例如ADD
堆栈型结构,累加器型结构,通用寄存器型结构比较
ALU指令操作数显隐式分析
- 堆栈型结构,ALU指令的所有操作数都隐式给出,其操作数一般为栈顶元素和次栈顶元素。
- 累加器型结构,ALU指令的一个操作数隐式给出,存储在累加器中,ALU指令的其他操作数显式给出。
- 通用寄存器型结构,ALU指令的所有操作数都显式给出。
完成一个操作的指令条数也是可以评价一个指令体系结构的标准,例如完成ADD操作,堆栈型比累加器型和RM型的指令条数多,在一定程度上反映了其劣处。
但是这也并不绝对,RR型的指令条数虽然多于RM型,但是,其更适合流水,运算速度不一定会慢。
因而,评价一个指令体系需要多方面的考虑。
优劣略览
堆栈型和累加器型计算机的优势:
- 指令字比较短
- 程序占用的空间都比较小
堆栈型计算机的瓶颈:
- 不能随机的访问堆栈,难以生成有效的代码
- 对于栈顶的访问速度在某种程度上难以进行大幅度提升
累加器型计算机的瓶颈:
- 只有一个中间结果暂存器,需要频繁的访问存储器
通用寄存器型计算机的优势:
- 寄存器可以存放变量。可以减少存储器的通信量,加快程序的执行速度。
- 编译器根据程序需要,可以更加容易,有效地分配和使用寄存器。例如:在表达式求值方面,(A * B) - (C * D),对于堆栈型和寄存器型计算机,二者在减少访存的前提下,只能顺序计算。
对于RR和RM的各种类型计算机的分析:
寄存器-寄存器型(0,3)
- 指令字长固定,指令结构简洁,是一种简单的代 码生成模型,各种指令的执行时钟周期数相近。
- 与指令中含存储器操作数的指令系统结构相比, 指令条数多,目标代码不够紧凑,因而程序占用 的空间比较大。
寄存器-存储器型(1,2)
- 可以在ALU指令中直接对存储器操作数进行引用,而不必先 用load指令进行加载,容易对指令进行编码,目标代码比较紧凑。
- 指令的执行时钟周期因操作数的来源(寄存器或存储器)的不同而差别比较大。
- 在一条指令中同时对寄存器操作数和存储器操作数进行编码,有可能限制指令所能够表示的寄存器个数。
- 由于有一个操作数的内容将被破坏,所以指令中的两个操作数不对称。
存储器-存储器型(2,2)或(3,3)
- 目标代码最紧凑,不需要设置存储器来保存变量。
- 指令字长变换很大,特别是3个操作数指令。
- 而且每条指令完成的工作也差别很大,所需要的时钟周期差别也比较大。
对于这一部分,随着可以直接使用的存储器操作数目的增加,一方面使得代码更加紧凑,一方面使得指令字长会受到影响,以及不同指令的执行周期差别较大,难以确定总的执行周期。
指令系统的设计和优化
指令系统的设计可以分成两个部分:
- 指令功能的设计
- 指令格式的设计
指令功能的设计
一般而言,在指令系统的设计过程中,最先完成的设计是指令功能的设计。
概念
指令功能的设计包含以下部分:
- 考虑所要实现的基本功能
- 决定这些基本功能中哪些基本功能由硬件实现,那些基本功能由软件实现。
设计方式
在决定那些基本功能由硬件实现,那些基本功能由软件实现时,主要的考虑因素有三个:速度,成本,以及灵活性。
使用硬件实现的功能速度快、成本高、灵活性差。与之相反,软件实现的功能速度慢、价格便宜、灵活性好。
其实这一步就是决定软硬件界面的分界线。一般而言,这里采用“大概率事件优先”原则,使用频率较高的基本功能以硬件实现,使用频率较低的功能以软件实现。
指令系统功能的基本要求
完整性
在一个有限可用的存储空间内,对于任何 可解的问题,编制计算程序时,指令系统所提供的 指令足够使用。
要求指令系统功能齐全、使用方便。
规整性
- 对称性:所有与指令系统有关的存储单元的使用、操作码的设置等都是对称的。
- 均匀性:指对于各种不同的操作数类型、字长、操作种类和 数据存储单元,指令的设置都要同等对待。
- 一般而言,所实现的有限的规整性。实现完全的规整性太复杂也并不现实。
正交性
在指令中各个不同含义的字段,如操作类型、 数据类型、寻址方式字段等,在编码时应互不相关、相 互独立。
高效率
指指令的执行速度快、使用频度高。
兼容性
主要是要实现向后兼容,指令系统可以增加新 指令,但不能删除指令或更改指令的功能
控制指令功能的具体实现
控制指令可以分成以下三种:
- 分支指令,有条件的改变控制流
- 跳转指令,无条件的改变控制流
- 过程调用和过程返回指令
Ps:
一般而言,分支指令和跳转指令都会显式地给出目标地址,而过程返回指令会由于不知道其返回地址,使用PC相对寻址进行处理。
PC相对寻址,是指:在指令中给出相应的偏移量,以当前PC中值与偏移量之和即为目标地址。
分支条件表示 优 点 缺 点 条件码(CC):在程序的控制下,由ALU 操作设置特殊的位 可以自由设置分支条件 条件码是增设的状态,而且它限制了指令的执行顺序,因为必须保证条件码能顺利地传送给分支指令 条件寄存器:比较指 令把比较结果放入任 何一个寄存器,检测 时就检测该寄存器 简单 占用了一个寄存器 比较分支:比较操作 是分支指令的一部分, 比较受限制 一条指令 完成了两 条指令的 功能 采用流水方式时,该指令的操作可能太多,在一拍内做不完
指令格式的设计
概念
确定指令字的编码方式,包括操作码字段以及地址码字段的编码和表示方式。
指令设计的两种方式
等长扩展码
其实就是扩展码技术。
可以根据该指令使用的频率以及该指令中操作数的地址位数进行操作码的选取。

定长操作码
固定长度的操作码:所有指令的操作码都是同一的长度。
可以保证操作码的译码速度、减少译码的复杂度。
指令系统的发展和改进
一个方向是强化指令功能,实现软件功能向硬件功能转移, 基于这种指令集结构而设计实现的计算机系统称为复杂指令集计算机(CISC, complex instruction set computer)
另一个方向是尽可能地降低指令集结构的复杂性,以达到简化实现, 提高性能的目的。基于这种指令集结构而设计实现的计算机系统称为精简指令集计算机(RISC, reduced instruction set computer)
沿CISC方向发展和改进指令系统
面向目标程序增强指令功能
目的
- 减少程序的执行时间
- 减少程序所占的空间
方法
- 对于使用频度较高的指令,用硬件加快其执行
- 对于使用频度较高的指令串,使用一条的新的指令进行代替
具体例子
- 增强运算型指令的功能,例如:多项式计算,十进制运算等等
- 增强数据传送指令的功能,例如:成组传送指令
- 增强程序控制指令的功能,例如:循环指令
面向高级程序语言的优化实现
目的
- 缩小机器语言与高级语言之间的语义差距,使得编译器可以对高级语言所编写的代码进行较好的优化。
方法
- 对高级语言中执行频率高,执行时间长的语句,增强相应的指令功能。
- 增强指令系统结构的规整性,减少指令系统结构中的各种例外情况。
面向操作系统的优化实现改进指令系统
就是对操作系统更加友好
总的来讲,沿CISC方向发展和改进指令系统就是:指令不够我就加指令,指令不快我就硬件实现指令
CISC结构的问题
- 在CISC结构的指令系统中,各种指令的使用频率相差悬殊。据统计,有20%的指令使用频率最大,占 运行时间的80%。也就是说,有80%的指令在20% 的运行时间内才会用到。
- CISC结构指令系统的复杂性带来了控制器硬件的复杂性,控制器硬件大量占用芯片面积,给VLSI(超大规模集成电路)设计造成很大困难。这不仅增加了研制时间和成本,而且还容易造成设计错误。
- CISC结构的指令系统中,许多复杂指令需要很复杂的操作, 导致CPI比较大。
- 在CISC结构的指令系统中,由于各条指令的功能不复杂,规整性不好, 不利于采用流水技术来提高系统的性能。
沿RISC方向发展和改进指令系统
RISC机器的指令系统设计原则
- 指令条数少,指令功能简单。在确定指令系统时,只选取使用频度很高的指令,在此基础上补充一些最有用的指令。
- 采用简单而又统一的指令格式,减少寻址方式。
- 指令的执行在单周期内完成(采用流水线技术后)。
- 只有load和store操作指令才访问存储器,其它指令操作均在寄存器之间进行。
- 大多数指令都采用硬连线逻辑进行实现。
- 强调优化编译器的作用,为高级语言程序生成优化的代码。以简单有效的方式支持高级语言。
RISC系统效能分析

对于RISC系统而言,IC一般较大,但CPI较低,Tclk也比较低。
下面是MIPS(RISC)与VAX(CISC)的对比
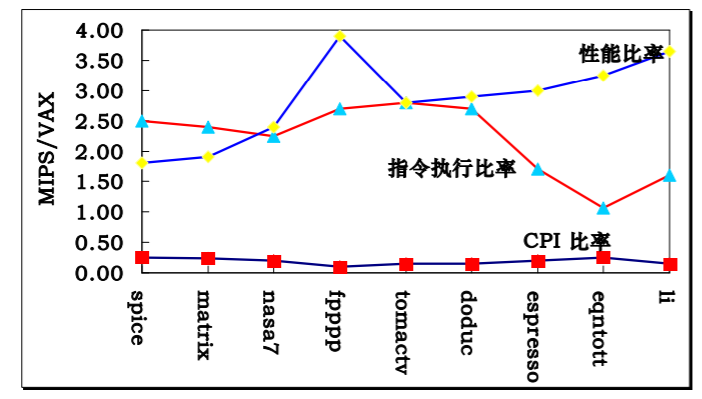
MIPS指令系统结构
下面所介绍的将会是MIPS64的一个子集。
MIPS是一个典型的RISC架构的指令系统。
寄存器
-
32个64位通用寄存器(General-Purpose Registers, GPRs)。即:R0, R1, R2,...., R31。其中R0的内容永远是0。
-
32个32位单精度浮点寄存器(Floating-Purpose Registers, FPRs)。即:F0, F1, F2,...., F31。其中可以存储32个单精度浮点数,也可以存储16个双精度浮点数。
-
一些特殊寄存器。如浮点状态寄存器,用来保存有关浮点操作结果的信息。
数据类型
- 整型数据:8位,16位,32位。
- 浮点数据:32位单精度浮点数,64位双精度浮点数
寻址方式
- 立即数寻址。eg:ADD R1,R2,#42
- 寄存器寻址。eg:ADD R1,R2,R3
- 偏移量寻址:变址寻址,基址寻址(相对寻址)。eg:LW R2,40(R3)
拓展来讲,偏移量寻址又可以拓展为:寄存器间接寻址以及16位绝对寻址。
- 当偏移量为0时,寄存器间接寻址
- 当寄存器位R0时,16位绝对寻址
Ps:在MIPS中,不论是立即数寻址还是偏移量寻址,立即数字段与偏移量字段都是16位。
指令格式
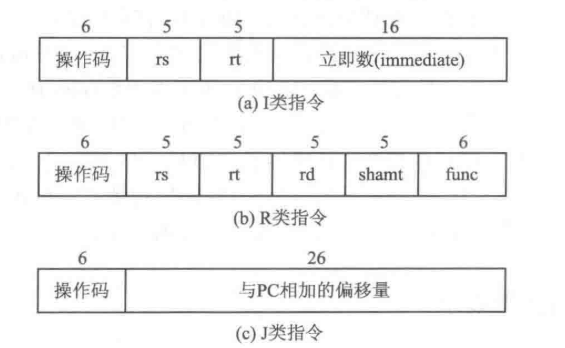
I型指令
| 指令 | 效果 |
|---|---|
| Load | Regs[rt] << Regs[rs] + immediate |
| Store | Regs[rs] + immediate << Regs[rt] |
| 寄存器-立即数ALU指令 | Regs[rt] << Regs[rs] op immediate |
| 分支指令 | PC << Regs[rs] + immediate |
| 寄存器跳转,寄存器跳转并链接(链接:设置返回地址) | PC << Regs[rs] |
R型指令
寄存器-寄存器型ALU指令,专用寄存器读写指令,move指令。
| 指令 | 效果 |
|---|---|
| 寄存器-寄存器型ALU指令 | Regs[rd] << Regs[rs] func Regs[rt] |
J型指令
跳转指令,跳转并链接指令,自陷指令,异常返回指令。
指令的低26位为偏移量,与NPC(next PC)相加得到形成跳转的地址。
操作类型
Ps:符号说明
- 符号“←”表示数据传送操作,其后附带一个下 标n,也即“←n” 表示传送一个n位数据。
- 符号“##”用来表示两个域的串联操作,它可以出现在数据传送操作的任何一边。
- 域的下标用来表明从该域中选择某一位。域中位的标记是从最高位开始标记,并且起始标记为0。下标可以是一个单独的数字,如Regs[R4]0 表示选择寄存器R4中内容的符号位;下标也可 以是一个范围,如Regs[R3]24..31表示选择寄存器 R3中内容的最低一个字节。
- 上标表示复制一个域,如024可以得到一个24位全为0的一个域。
- 变量Mem用来表示存储器中的一个数组,存储器按照字节寻址,它可以传送任何数目的字节。
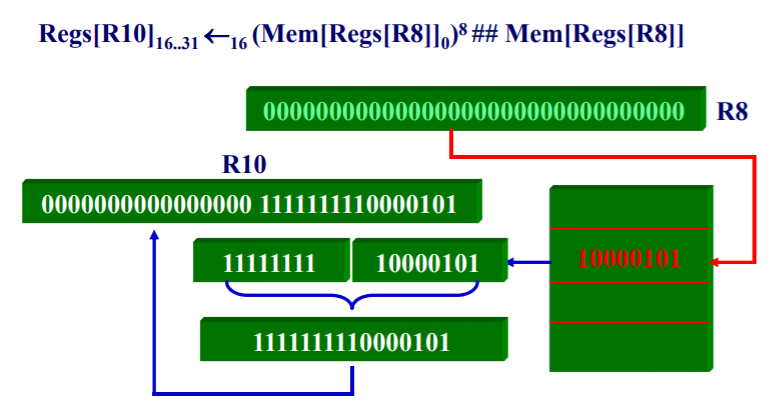
load store

ALU指令

控制指令
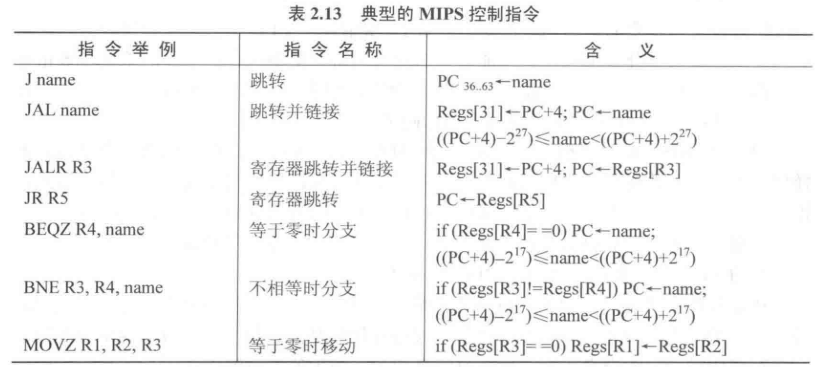
对于控制指令的细节之处:就是name的取值,不知道为什么上面会那么进行取值,那么范围不就盲目扩大了吗?而下面的这个是按照之前的指令格式中相应位数进行取值的。

浮点指令
操作包括加、减、乘、除。且都具有单精度双精度两种格式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号