
Prometheus自定义远端存储实现
前言
prometheus默认把数据存在本地文件,随着时间的增长,文件会越来越大,当查询一个时间跨度很大指标时,会很消耗资源,查询效率会很低。
为此prometheus引入了远端存储。为了适应不同的远端存储,prometheus并没有选择对接各种存储,而是定义了一套读写存储接口,并引入了Adapter适配器,将prometheus的读写请求转化为第三方远端存储接口,从而完成数据读写。整体架构如下图:
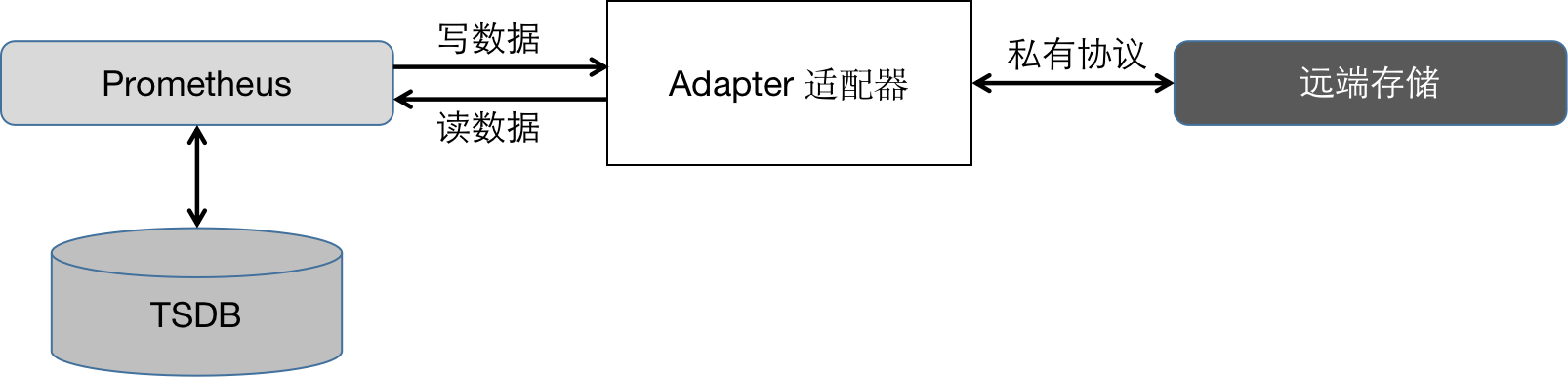
远端接口规范
prometheus源码里提供了influxdb的远程读写实现,具体代码在
documentation/examples/remote_storage/remote_storage_adapter目录下,可以自己去看下,这里只讲下实现原理。
写接口
比如现在上报了一个指标:
df{instance="localhost:5000",job="prometheus",mount="/boot",step="15s"}
prometheus在向远端存储发起写请求时,都是采用HTTP的形式发送数据,数据格式如下:
{
"timeseries": [{
"labels": [{
"name": "__name__",
"value": "df"
}, {
"name": "instance",
"value": "localhost:5000"
}, {
"name": "job",
"value": "prometheus"
}, {
"name": "mount",
"value": "/home"
}, {
"name": "step",
"value": "15s"
}],
"samples": [{
"value": 6,
"timestamp": 1632204968206
}]
}]
}
适配器的写接口要做的就是把这个json格式的数据 写到我们自己的存储里。
读接口
现在我要查询一个指标:
df{mount="/boot"}
prometheus在调用远程存储的读接口时,会传入以下格式的参数:
{
"queries": [{
"start_timestamp_ms": 1632208558163,
"end_timestamp_ms": 1632208858163,
"matchers": [{
"name": "mount",
"value": "/boot"
}, {
"name": "__name__",
"value": "df"
}],
"hints": {
"start_ms": 1632208558163,
"end_ms": 1632208858163
}
}]
}
再比如查询topk:
topk(3, rate(df[1m]))
对应的传参如下:
{
"queries": [{
"start_timestamp_ms": 1632216783085,
"end_timestamp_ms": 1632217083085,
"matchers": [{
"name": "__name__",
"value": "df"
}],
"hints": {
"func": "rate",
"start_ms": 1632217023085,
"end_ms": 1632217083085,
"range_ms": 60000
}
}]
}
而prometheus期望接口返回的数据格式如下:
{
"results": [{
"timeseries": [{
"labels": [{
"name": "instance",
"value": "localhost:5000"
}, {
"name": "job",
"value": "prometheus"
}, {
"name": "mount",
"value": "/boot"
}, {
"name": "step",
"value": "15s"
}, {
"name": "__name__",
"value": "df"
}],
"samples": [{
"value": 6,
"timestamp": 1632208920000
}, {
"value": 4,
"timestamp": 1632208950000
}, {
"value": 10,
"timestamp": 1632208980000
}, {
"value": 10,
"timestamp": 1632209010000
}, {
"value": 1,
"timestamp": 1632209040000
}, {
"value": 9,
"timestamp": 1632209070000
}]
}]
}]
}
Demo
open-falcon是小米公司开源的一款监控工具,其后端采用rrd存储,rrd是一个时序数据库,以文件的形式存储在硬盘中,其特定为一个指标对应一个rrd文件,rrd文件固定大小为100kb左右,因为它采取了预聚合的方式,无论数据存多久,rrd文件大小都是固定不变的,在查询时间跨度很大的情况下,它会自动根据查询时间范围来选择聚合策略将数据返回给用户。
示例代码在 https://gitee.com/zqwlai/prometheus/tree/falcon-adapter/documentation/examples/remote_storage/falcon-adapter ,有兴趣的同学可以看下。
主要逻辑就是写数据时对接open-falcon的transfer模块,将数据写入,查询数据时从open-falcon的api模块获取。
总结
适配器的实现原理就是把prometheus的上报数据转换为远端存储自己的格式,读取数据时再把远端存储的数据转换为prometheus期望的数据格式。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性