
k8s网络概述
前言
在介绍k8s的网络通信机制前,先介绍一下docker的网络通信机制,不同节点pod间网络通信,在docker里是这样访问的
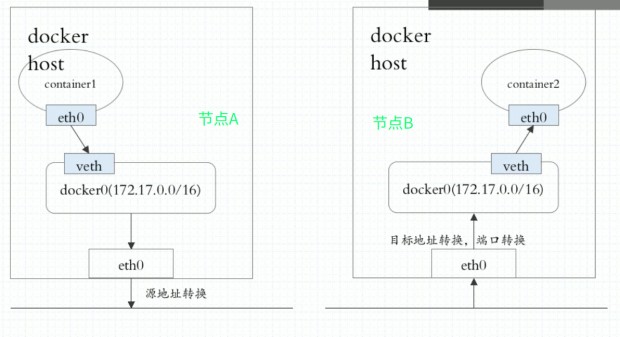
即: Container1 snat-> 节点A (docker0网桥) -> 节点B(docker0网桥) ->dnat -> pod2
这样的访问方式会产生很大的系统开销,因为需要产生两级NAT转换,container1访问出去时需要经过eth0的SNAT,报文达到对端节点的eth0后,做一次DNAT,当Container2发送响应报文时,又需要本节点物理网卡做一次SNAT,对端节点物理网卡做一次DNAT。
同样还会产生一个问题,Container1始终不知道它真正和谁在通信,它明明是访问Container2的地址,当目标地址指向的确是对端节点的物理IP。
k8s网络通信
下面再看看k8s是怎么解决网络通信的。
k8s要解决的网络通信模型有以下几种场景:
- 容器间通信,同一个pod内多个容器的通信
- pod之间通信,又分为同节点pod之间的通信,和不同节点pod之间的通信
- pod与Service通信
- service与集群外部进行通信
(2)pod之间通信,k8s要求pod和pod通信时,从一个pod IP到另一个pod IP不需要经过任何的NAT转换,要能够直达 ,双方所见的地址就是通信时的地址。
这里又分为同节点pod之间的通信,和不同节点pod之间的通信。
(3)pod与Service通信 podIP <--> clusterIP
(4)service与集群外部进行通信
Pod内部通信
pod内部给容器之间共享网络命名空间,就好比一台机器上有多个进程,他们之间通信可以通过lo口来实现。
同节点Pod之间通信
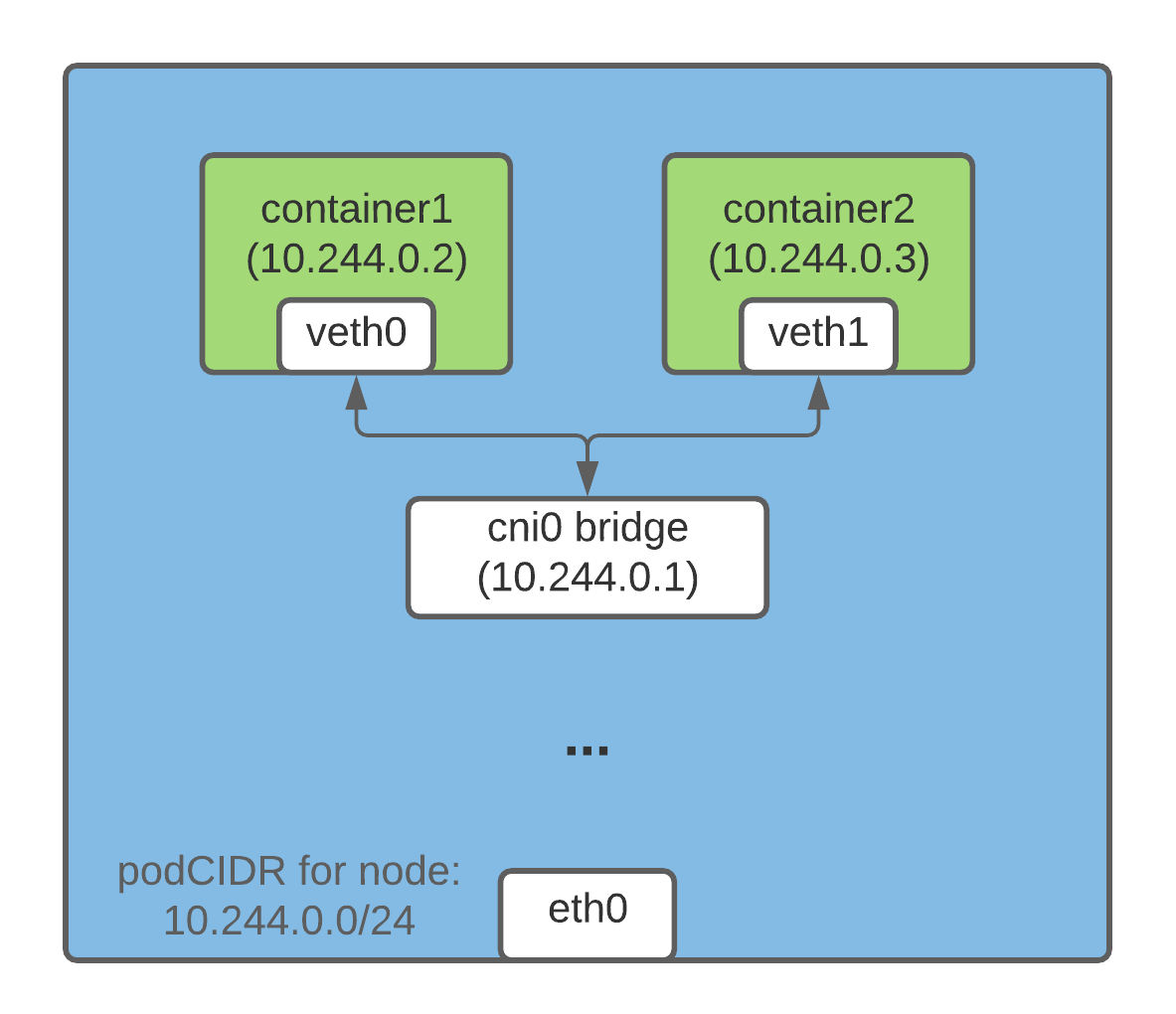
同一个节点内Pod之间是通过cni0网桥直接进行通信,和docker的通信方式一样。
不同节点Pod之间通信
Flannel网络插件
这里先要介绍下CNI,k8s自身没有提供网络解决方案,但它定义了一种容器网络接口,任何第三方的程序只要能解决上面这4种通信模型,那它就可以拿来做k8s的网络接口。有点类似golang里接口的概念。
目前比较常用的网络插件有flannel和calico,flannel的功能比较简单,不具备复杂网络的配置能力,calico是比较出色的网络管理插件,单具备复杂网络配置能力的同时,往往意味着本身的配置比较复杂,所以相对而言,比较小而简单的集群使用flannel,考虑到日后扩容,未来网络可能需要加入更多设备,配置更多策略,则使用calico更好。
kubelet会调用/etc/cni/net.d目录下的网络插件配置,由网络插件实现地址分配、接口创建、网络创建等功能 。
flannel有三种模式:
-
host gw
把节点作为网关,那每个节点的pod网络就应该都不一样,A节点的pod要访问B节点的pod时,先会发到本地网关,本地网关存有所有pod网络的路由信息,会匹配到B节点的pod网络并把数据发给B节点的网关,B节点网关也会检查本地路由信息,发现是发给本地pod的请求就会把请求发给本地pod。
此种方式需要各节点在同一个网络中,数据包直接以路由形式发给对方而不要像vxlan一样进行数据包的封装,这种方式有缺点,节点数量很多时,每个节点维护的路由信息会很大,而且由于节点在同一个网络,容易受到广播包的影响。 -
vxlan
当节点在同一个网络中时,会自动降级为host gw模式通信,其中vxlan又分为两种模式:
1、vxlan(默认)
2、directrouting,适用于宿主机同网段,不同网段时自动降级为vxlan
参见kube-flannel的配置:
kubectl edit configmap kube-flannel-cfg -n kube-system

- UDP: 这种方式性能最差的方式,这源于早期flannel刚出现时,Linux内核还不支持VxLAN,即没有VxLAN核心模块,因此flannel采用了这种方式,来实现隧道封装。
这里只介绍Vxlan的实现方式
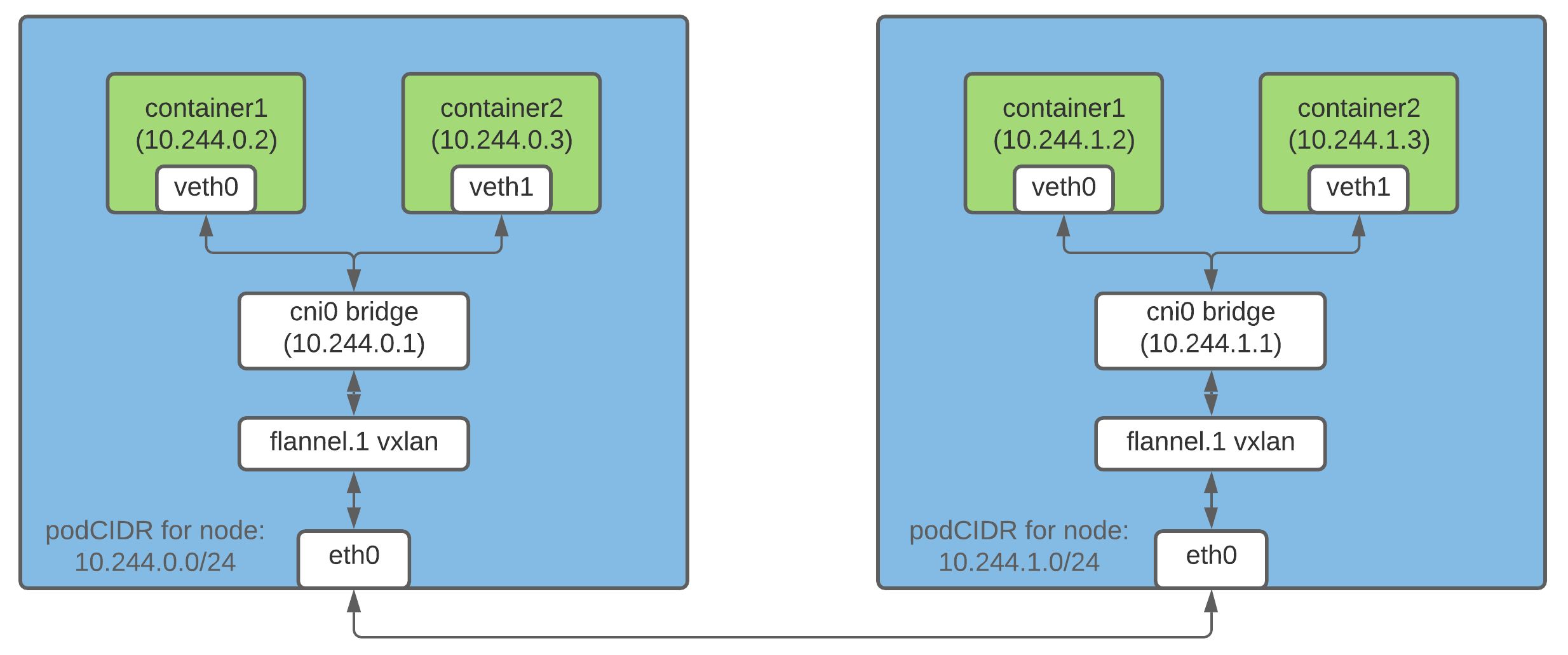
在k8s中,网桥变为cni0,Pod的数据包出去时,先经过cni0,再到flannel.1接口时会将数据包封装成vxlan协议的数据包发给对端,对端flannel.1解包后发给本地Pod,最终的效果就是pod间通信就像在二层网络一样,容器直接可以直接使用pod ip进行通讯。
在跨节点的pod通信时,在物理网卡上抓包时可以看到OTV类型的包的,表示的是overlay数据包。
在同节点的pod通信时,不会产生overlay数据包。
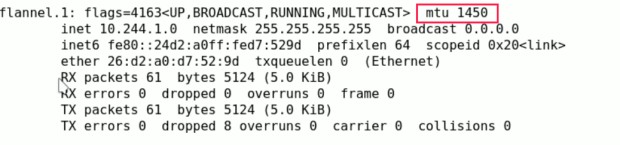
flannel.1网卡:
pod跨节点通信时,物理网卡要做成叠加网络的形式时,两个物理网卡之间应各自有个叠加报文封装的隧道,隧道的两端通常称为flannel.0/1,其地址很独特,ip地址为10.244.0.0(举例),掩码为255.255.255.255, 而且它的mtu是1450,不像物理网卡一样是1500,因为隧道要做叠加封装,要有额外的开销,所以要留出50给这个开销。如下图所示:
Pod网卡:
生成Pod时,会像docker一样创建一对虚拟接口/网卡,也就是veth pair,一端连接到容器中,另一端桥接到vethxxxx网卡并桥接到cni0网桥,如下图所示:
可以看到宿主机上的vethxxxx网卡都是桥接在cni0网卡上的。
通过ethtool -S (网卡名),可以看到peer的index,一对peer的index是相连的
测试
先在两个node节点上分别创建一个PodA。PodB,模拟不同不同节点不同网络的测试环境,然后在PodA上一直ping PodB的地址,然后在PodA所在的节点上抓包分析。
先抓取flannel.1网卡上的包:
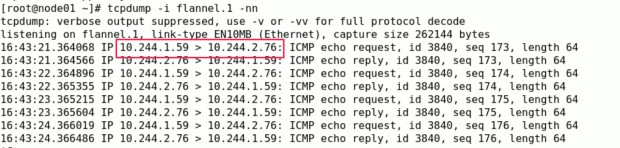
可以看到两个Pod是直接通过podIP访问的。
再抓取物理网卡上的包:
tcpdump -i ens32 -nn host (PodB所在节点物理网卡IP)

可以看到两个物理网卡之间通信有vxlan的包,并且包里可以看到是两个pod之间的icmp包
再查看主机路由:
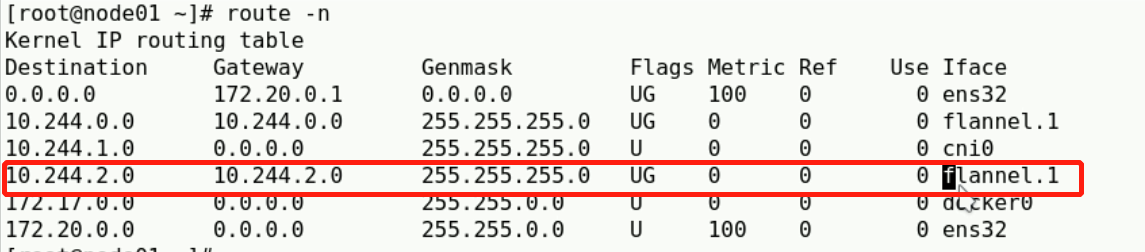
可以看到Pod跨节点访问时的默认网关是fannel.1
如果改成directrouting模式,再次从物理网卡上抓包,可以看到pod之间不会走vxlan进行包封装了,直接通过物理网卡通信

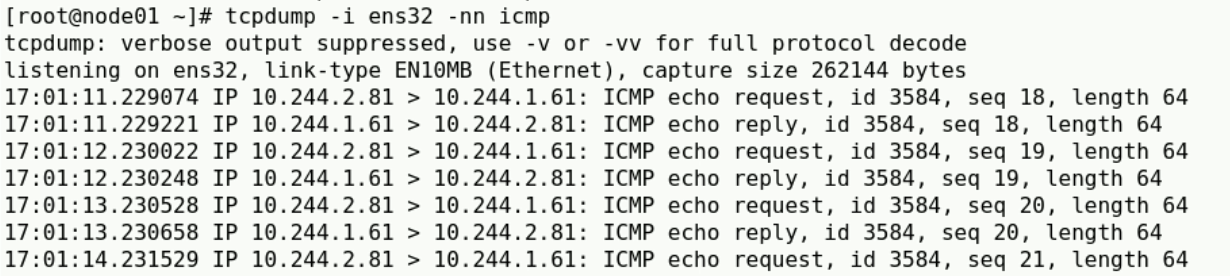
查看宿主机路由

Pod与Service通信
Pod与Service通信是通过Keube-Proxy模块来实现的,它会监听service的变化并管理sevice的Endpoints,该service对外暴露一个Virtual IP,也成为Cluster IP, 集群内通过访问这个Cluster IP:Port就能访问到集群内对应的serivce下的Pod。
Pod和Service是两种不同的网络,那么怎么实现Service和Pod的互通呢?kube-proxy提供了三种模式,iptables、ipvs、userspace,这里我们只介绍iptable的实现。
因为service地址就是iptables里的一个虚拟IP,而iptables在每个节点上都会存在,所以外部请求转发到任意一个物理节点,都能通过iptables规则把请求转发到后端Endpoints。
Service与集群外部进行通信
可以通过nodePort获取ingress将服务暴露出去。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App