

希尔排序、快速排序、KMP算法
希尔排序
-
背景
- 对N个样本进行排序,顺序为从小至大
-
步骤
- 第一步:对样本不断确定分组的间隔gap,确定分组次数X -》对应第一个循环
- 第一次gap = N/2;第二次gap = gap/2;直至分成一组,即gap=1;
- 第二步:从头开始遍历这X个组 -》对应第二个循环
- 实际遍历的时候从gap开始依次遍历即可
- 第三步:对第一步分组的内部M个元素进行排序
- 从组内的第二个元素开始,与前面元素进行对比插入;直至从组内第M个开始;
- 第一步:对样本不断确定分组的间隔gap,确定分组次数X -》对应第一个循环
-
代码
int shell_sort(vector<int> data){ int gap = 0;//分组的跨度 int i = 0, j = 0; for(gap = data.size()/2; gap >= 1; gap /= 2){// 分组的次数 for(i = gap; i < data.size(); i++){// 每组遍历 int tmp = data[i]; for(j = i-gap; j >= 0 && tmp < data[j]; j = j - gap){//组内排序 // 组内tmp和之前的组内元素进行对比,比该元素大的元素向后偏移1位; //直到找到比tmp小的第一位元素x,将tmp赋值给x的下一位 data[j+gap] = data[j]; } data[j+gap] = tmp; } } return 0; }
快速排序
-
背景
- 对N个样本进行排序,顺序为从小至大
-
步骤
- 第一步:选取哨兵(参考值),并保存哨兵 -》一般为当前集合的第一个元素
- 第二步:为哨兵找到合适的位置 -》前面部分比哨兵大,后面部分比哨兵小
- 从前到后,找第一个比哨兵大的数,赋值给哨兵的位置,此时值为x
- 从后到前,找第一个比x小的数,赋值给哨兵的位置
- 重复第一步第二步,直到i和j相遇,此时的位置刚好把哨兵的值夹在中间
- 第三步:对分完之后子集合重复上述操作---》递归左右子集
-
代码
int sort(vector<int>& v, int left, int right){ if(left >= right) return 0; int i = left; int j = right; int key = data[left]; while (i < j){//保证i一定会与j相遇 while(i < j && key < data[j]){//避免内部循环的时候i越过j j --; } data[i] = data[j]; while(i < j && key >= data[i]){//避免内部循环的时候i越过j i ++; } data[j] = data[i]; }//结束循环时i == j data[i] = key;// 找到了对应的中间位置,属于哨兵的位置 sort(data, left, i-1); sort(right, i+1, right); return 0; } int quick_sort(vector<int>& data){ sort(data, 0, data.size() - 1); return 0; }
KMP算法
-
背景
快速查找文本中相同字符串 -》利用匹配字符串pattern对文本字符串text进行搜索匹配
-
前提说明
ab 前缀:a 后缀:b 最长相等前后缀:0--》x abc 前缀:a,ab 后缀:b,bc 最长相等前后缀:0--》x abca 前缀:a,ab,abc 后缀:a,bc,bca 最长相等前后缀:1--》a abcab 前缀:a.ab.abc.abca 后缀:b,ab,cab,bcab 最长相等前后缀:2--》ab abcabc 前缀:a,ab,abc,abca,abcab 后缀:c,bc,abc,cabc,bcabc 最长相等前后缀:3--》abc - 前缀和后缀
- 前缀:不包含最后一个字符的前面的所有集合
- 后缀:不包含第一个字符的后面的所有集合
- 最长相等前后缀
- 前缀和后缀中存在相等最大长度的字符串
- next数组 -》也被称为前缀表
- pattern中字符的滑动窗口从第一个字符不断后移,每一个窗口下的最长相等前后缀的集合
- 例:上述next数组为next[6] = {0, 0, 0, 1, 2, 3}; -》字符有n个,数组大小为n
- 前缀和后缀
-
步骤
- 第一步:求出next数组
- 第二步:利用next数组进行匹配字符串
-
代码
void make_next(const char * pattern, int * next){// 得到next数组-》前缀表 int q = 0, k = 0; int m = strlen(pattern); next[0] = 0;//默认第一个字符的最长相等前后缀为0 for(k = 0, q = 1; q < m; q ++){// 下文有k的含义,k遍历前面部分,q遍历后面部分 // 不匹配进行回退,不止会回退一次 while( k > 0 && pattern[q] != pattern[k]){ k = next[k-1]; }//最差情况k == 0 if(pattern[q] == pattern[k]){ k ++; } next[q] = k; } } int kmp (const char * text, const char * pattern, int * next){ int n = strlen(text);// 文本字符串长度 int m = strlen(pattern);// 匹配字符串长度 make_next(pattern, next);// 得到next数组 int i, q; for(i = 0, q = 0; i < n; i ++){ // 不匹配进行回退,不止会回退一次 while( q > = && pattern[q] != pattern[i]){ q = next[q-1];// 对next数组的指针进行回退 } if(pattern[q] == text[i]){ q ++; } if(q == m){ return i-q+1;// 得到匹配字符串的初始位置 } return -1; } } -
图示
- 求出next数组

- 匹配字符串
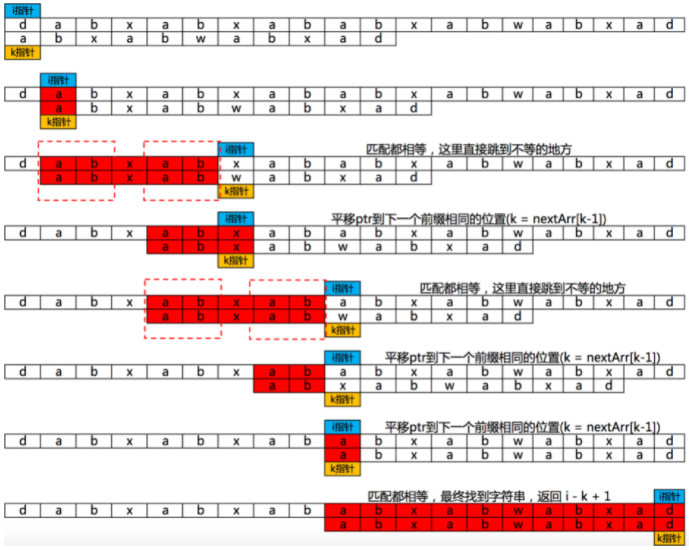
- 求出next数组
-
额外说明
-
求next数组的过程可以看作利用以求出的next数组,进行前面字符和后边字符的匹配
-
k = next[k-1] / q = next[q-1];
- 这两个位置都是利用next数组进行回退
- 因为一旦遇到不匹配的字符,对于pattern中该字符前面的字符串,后缀已经匹配相等的部分直接使用前缀相等的部分代替,从而减少匹配次数
-
由于kmp中text字符串的指针一直处于线性遍历,因此时间复杂度相比于暴力遍历的时间复杂度有大部分降低
- 暴力遍历的时间复杂度为O(m*n); -》m为text字符串长度,n为pattern字符串长度
- kmp的时间复杂度为O(m); -》m为text字符串长度
-
k的含义:
- 代表前面字符指向的位置
- 已经前后缀匹配成功的个数
-
-
KMP参考资料


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)