

Kafka的高吞吐率是怎么实现的
https://blog.csdn.net/jiayi_yao/article/details/124858036
1.ack=0;这个不算,一般不采用
2.磁盘顺序读写,达到内存读写的速度。先读后写。预读取磁盘内容到cache里,然后从cache里面读取。先写入cache里,后写入磁盘中。
3.0拷贝技术
原始是四次读写(即四次上下文切换)两次cpu拷贝,都非常浪费时间。两次DMA拷贝。
0拷贝技术两次读写(上下文切换)0次cpu拷贝。节省时间。两次DMA拷贝。

kafka的0拷贝
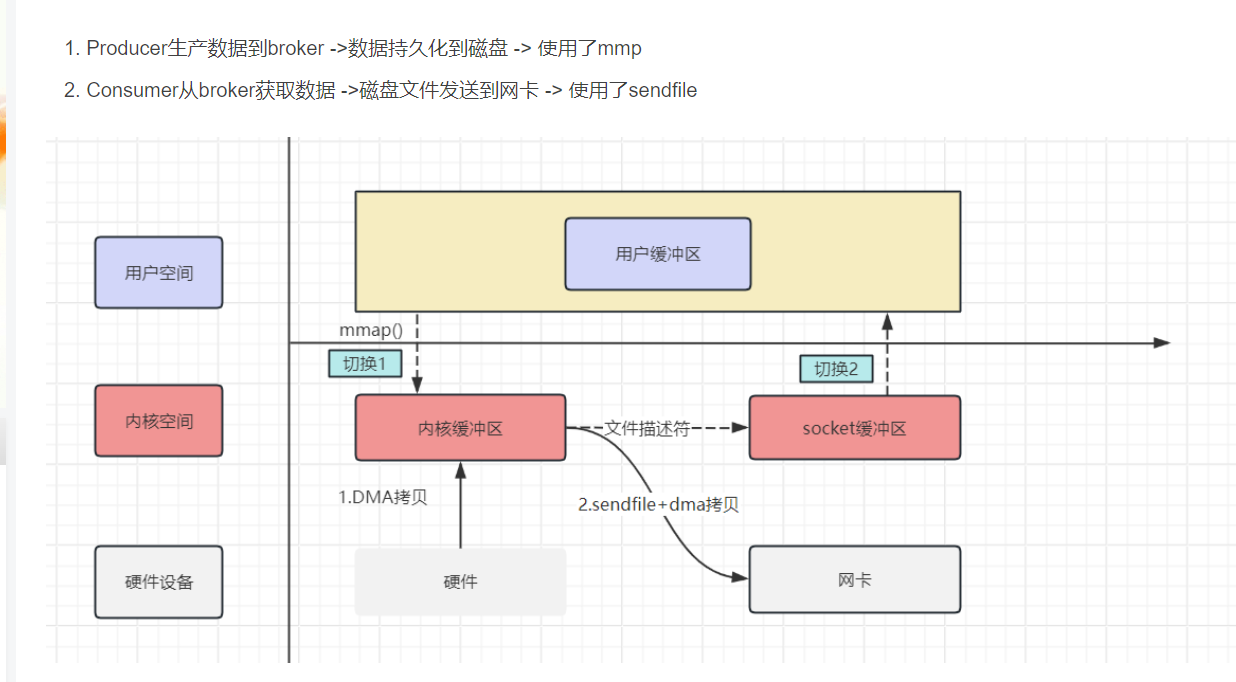
https://blog.csdn.net/m0_50546235/article/details/136892707
4.endtoend的压缩方式。压缩包在broker不解压,到消费者端解压。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现