数据结构_链表_单链表理论(基于C语言实现)
 本文从实际应用的角度基于C语言讲述数据结构中链表的原理与应用,此篇为单链表篇
本文从实际应用的角度基于C语言讲述数据结构中链表的原理与应用,此篇为单链表篇
声明: 本文以轩哥大佬所讲述笔记为基础并结合多方资料所写
2024年4月22日 更新中
链表的原理与应用
顺序表的优点:
- 由于顺序表数据元素的内存地址都是连续的,所以可以实现随机访问,而且不需要多余的信息来描述相关的数据,所以存储密度高。
顺序表的缺点:
- 顺序表的数据在进行增删的时候,需要移动成片的内存,另外,当数据元素的数量较多的时候,需要申请一块较大的连续的内存,同时当数据元素的数量的改变比较剧烈,顺序表不灵活。
链式存储的线性表
链式存储指的是采用离散的内存单元来存储数据元素,用户需要使用某种方式把所有的数据元素连接起来,这样就可以变为链式线性表,简称为链表,链表可以高效的使用碎片化内存。
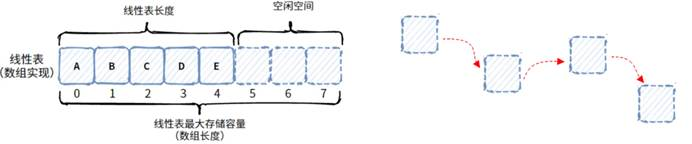
顺序表和链式表的区别:
顺序表使用连续的内存,链式表使用离散的内存空间。
用户如何访问链表中的某个元素?
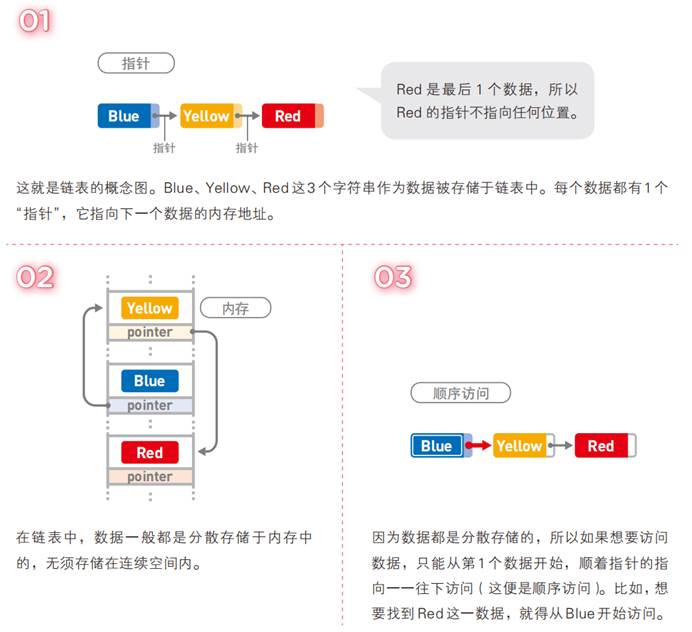
由于链表中的每个数据元素的地址是不固定的,所以每个数据元素都应该使用一个指针指向直接后继的内存地址,当然最后一个数据元素没有直接后继,所以最后一个数据元素指向NULL即可,作为用户只需要知道第一个数据元素的内存地址,就可以访问后继元素了。
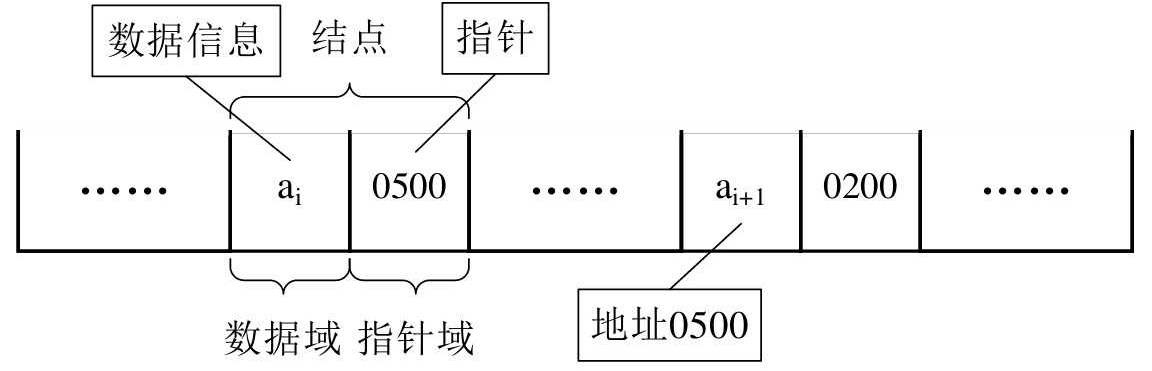
注意:如果采用链式存储,则线性表中每一个数据元素除了存储自身数据之外,还需要额外存储直接后继的地址,所以链表中的每一个数据元素都是由两部分组成:存储自身数据的部分被称为数据域,存储直接后继地址的部分被称为指针域,数据域和指针域组成的数据元素被称为结点(Node)。
链表的使用流程
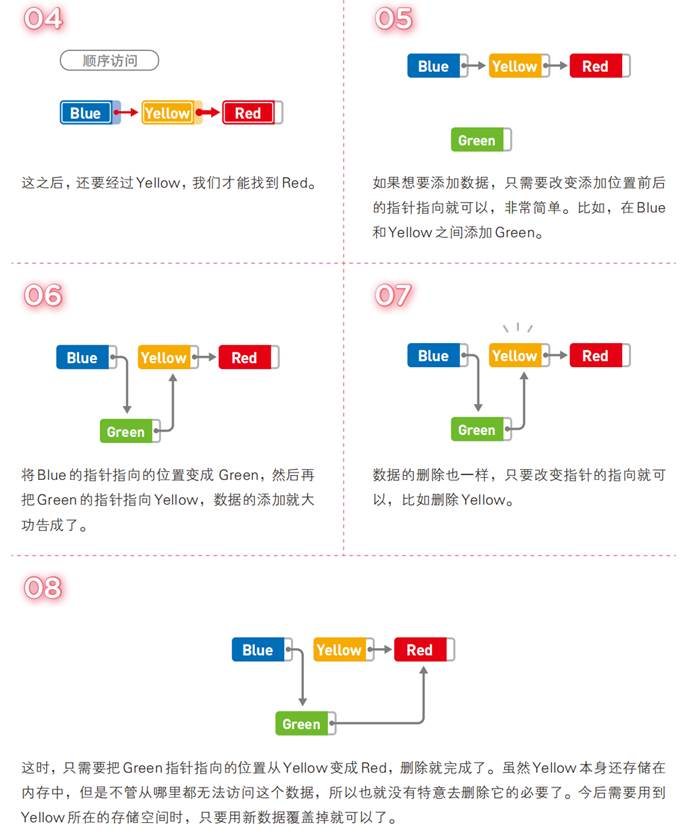
链表分类
根据链表的结点的指针域的数量以及根据链表的首尾是否相连,把链式线性表分为以下几种:单向链表、单向循环链表、双向链表、双向循环链表、内核链表。这几种链表的使用规则差不多,只不过指针域数量不同。

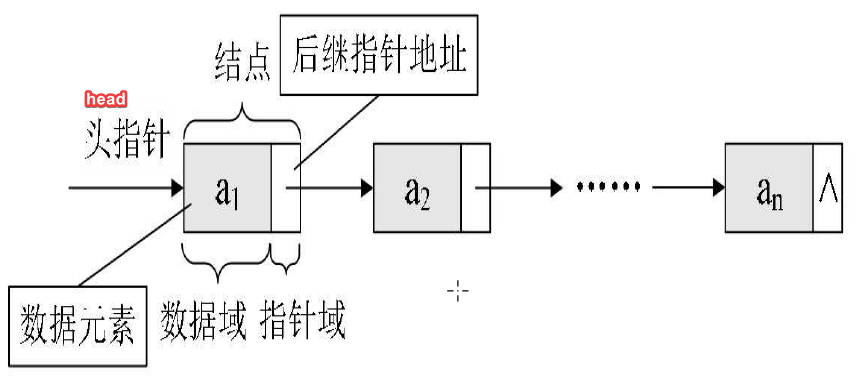
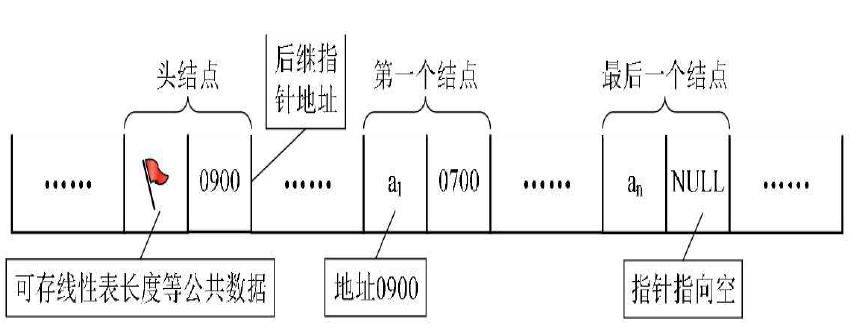
上图就是最简单的单向链表的内部结构,可以看到每一个结点都保存了一个地址,每个地址都是逻辑上相邻的下一个结点的地址,只不过末尾结点的指针指向NULL。
另外注意:可以看到链表中是有一个头指针的,头指针只指向第一个元素的地址,想要访问链表中的某个元素只需要通过头指针即可。
思考:使用顺序表的时候需要创建一个管理结构体来管理顺序表,请问链表需不需要创建???
回答:可以根据用户的需要来选择,一般把链表分为两种:一种是不带头结点的链表,一种是带头结点的链表,头结点指的是管理结构体,只不过头结点只存储第一个元素的内存地址,头结点并不存储有效数据,头结点的意义只是为了方便管理链表。
(1) 不带头结点的链表
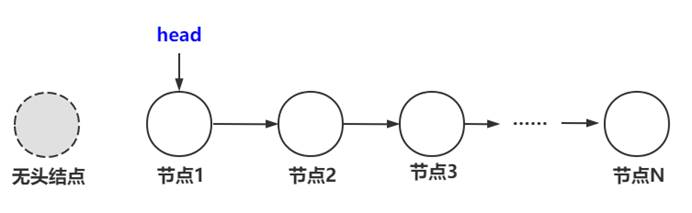
(2) 附带头结点的链表
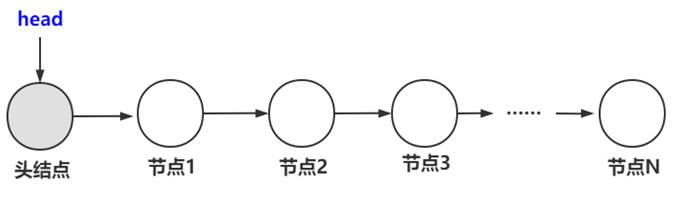
可以知道,头指针是必须的,因为通过头指针才可以访问链表的元素,头结点是可选的,只是为了方便管理链表而已。
链表结点
注意:在链表中,还有两个专业名称,一个是首结点,一个是尾结点,三者之前的区别如下:
A. 头结点:是不存储有效数据的,只存储第一个数据元素的地址,头指针只指向头结点。
B. 首结点:是存储有效数据的,也存储直接后继的内存地址,首结点就是第一个结点,首结点是唯一一个只指向别的结点,不被别的结点指向的结点。
C. 尾结点:是存储有效数据的,尾结点就是链表的最后一个结点,所以尾结点中存储的地址一般指向NULL,尾结点是唯一一个只被别的结点指向,不能指向别的结点的结点。
构造头结点的数据类型以及构造有效结点
为了方便管理单向链表,所以需要构造头结点的数据类型以及构造有效结点的数据类型,如下:
构造链表的结点
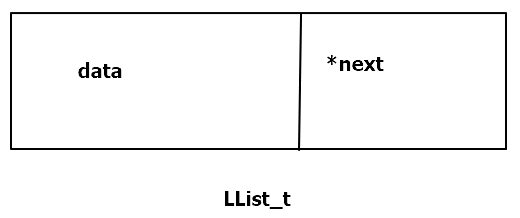
//DataType_t指的是单向链表中的结点有效数据类型,用户可以根据需要进行修改
typedef int DataType_t;
//构造链表的结点,链表中所有结点的数据类型应该是相同的
typedef struct LinkedList
{
DataType_t data; //结点的数据域
struct LinkedList *next; //结点的指针域, 存放下一个结点的地址
}LList_t;
创建一个空链表(仅头结点)
(1) 创建一个空链表,由于是使用头结点,所以就需要申请头结点的堆内存并初始化即可。
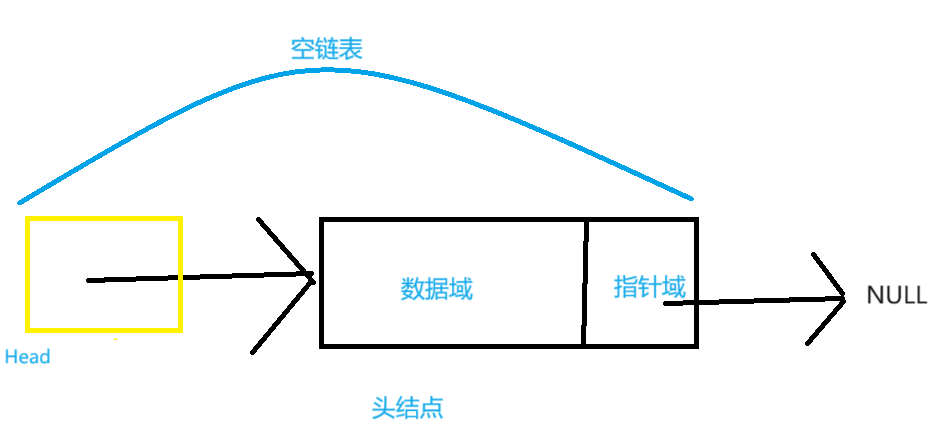
//创建一个空链表,空链表应该有一个头结点,对链表进行初始化
LList_t * LList_Create(void)
{
//1.创建一个头结点并对头结点申请内存, 只申请一个节点大小, calloc会初始化为0
LList_t *Head = (LList_t *)calloc(1,sizeof(LList_t));
//错误处理
if (NULL == Head)
{
perror("Calloc memory for Head is Failed");
exit(-1);
}
//2.对头结点进行初始化,头结点是不存储有效内容的!!!
Head->next = NULL;
//3.把头结点的地址返回即可
return Head;
}
创建一个新结点
(2) 创建一个新结点,并为新结点申请堆内存以及对新结点的数据域和指针域进行初始化。
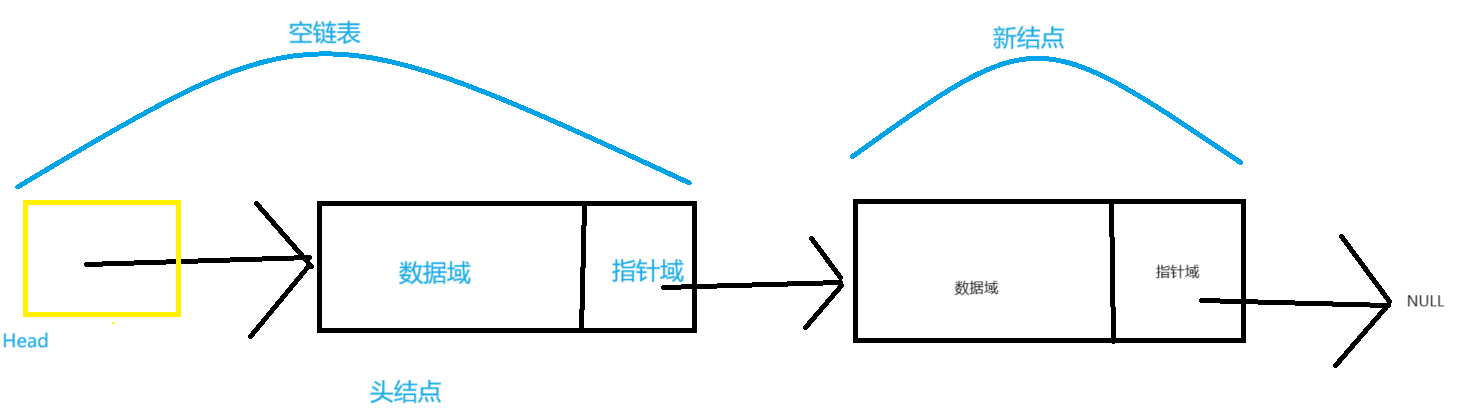
//创建新的结点,并对新结点进行初始化(数据域 + 指针域)
LList_t * LList_NewNode(DataType_t data)
{
//1.创建一个新结点并对新结点申请内存
LList_t *New = (LList_t *)calloc(1,sizeof(LList_t));
if (NULL == New)
{
perror("Calloc memory for NewNode is Failed");
return NULL;
}
//2.对新结点的数据域和指针域进行初始化
New->data = data;
New->next = NULL;
return New;
}
将新结点插入链表
一定要先链接再 增加/删除
(3) 根据情况把新结点插入到链表中,此时可以分为尾部插入、头部插入、指定位置插入。
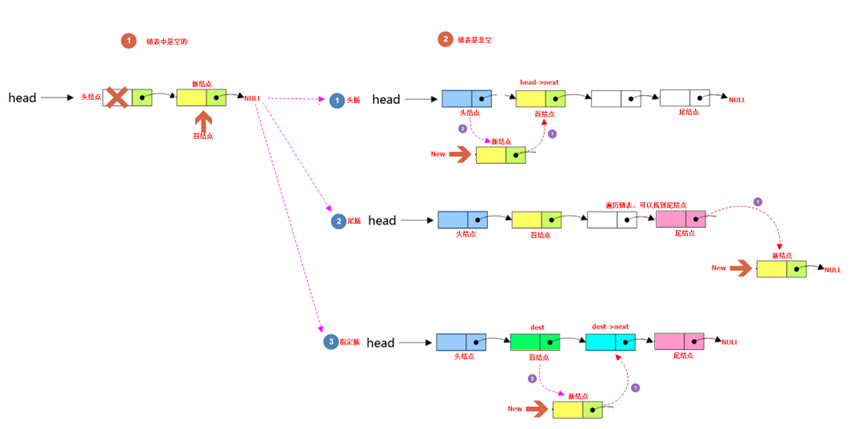
头插法
/**
* @function name: LList_HeadInsert
* @brief 单链表中的头插法
* @param @Head:头指针
@data:要插入的数据
* @retval true插入成功 false插入失败, 申请内存失败
*/
bool LList_HeadInsert(LList_t *Head,DataType_t data)
{
//1.创建新的结点,并对新结点进行初始化
LList_t *New = LList_NewNode(data);
if (NULL == New)
{
printf("can not insert new node\n");
return false;
}
//2.判断链表是否为空,如果为空,则直接插入即可
if (NULL == Head->next)
{
Head->next = New;
return true;
}
//3.如果链表为非空,则把新结点插入到链表的头部
New->next = Head->next;
Head->next = New;
return true;
}
指定位置插入
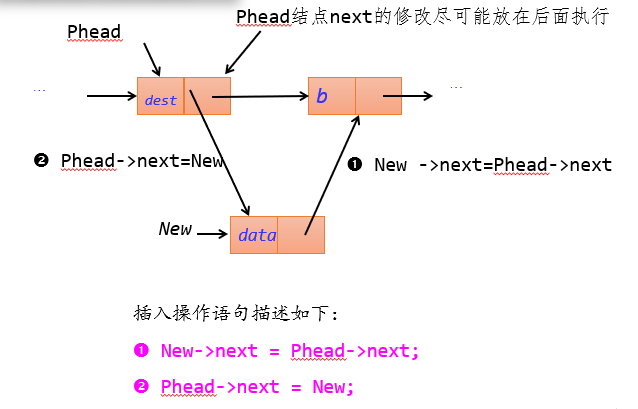
/**
* @function name: LList_DestInsert
* @brief 单链表中的指定元素后插入
* @param @Head: 头指针
@dest: 要查找的结点
@data: 要插入的数据
* @retval true插入成功 false插入失败
*/
bool LList_DestInsert(LList_t *Head,DataType_t dest,DataType_t data)
{
//指向首节点
LList_t *Phead = Head->next;
//1.遍历, 先找到目标结点
while(NULL != Phead && dest != Phead->data)//查找data值为dest的结点
{
Phead = Phead->next;//把头的直接后继作为新的头结点
}
if (NULL == Phead) //不存在元素为dest的结点, 返回false
return false;
//2.若目标结点存在, 创建新的结点,并对新结点进行初始化
LList_t *New = LList_NewNode(data);
if (NULL == New)
{
printf("can not insert new node\n");
return false;
}
New->data = data;
//3.把新结点插入到目标结点的后面
New->next = Phead->next;//新结点先链接后面的结点
Phead->next = New;//让目标元素结点链接新结点
return true;
}
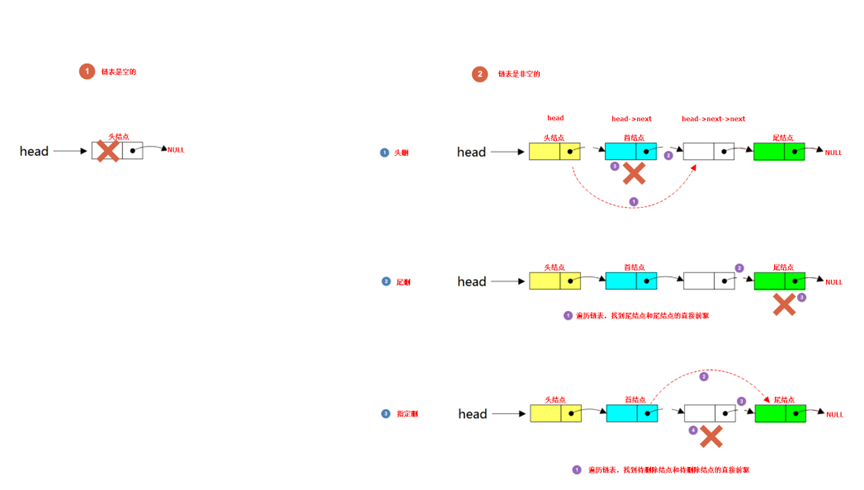
(4) 根据情况可以从链表中删除某结点,此时可以分为尾部删除、头部删除、指定元素删除。
本文来自博客园,作者:舟清颺,转载请注明原文链接:https://www.cnblogs.com/zqingyang/p/18151907



· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现