
pytorch——lenet,resnet,时间序列表示法,RNN
Lenet5
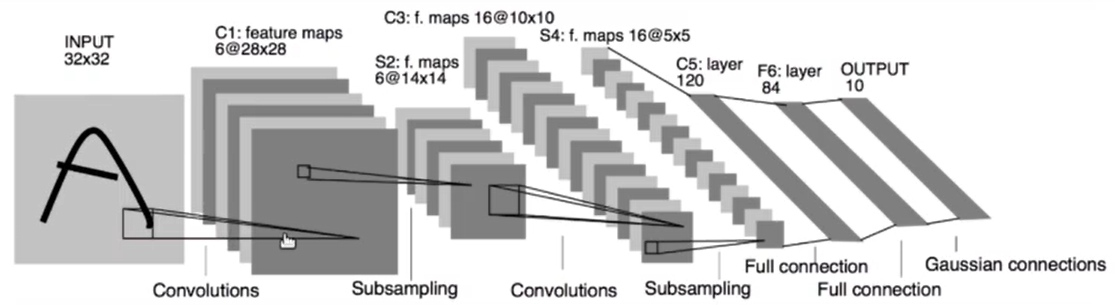
import torch from torch import nn class Lenet5(nn.Module): def __init__(self): super(Lenet5, self).__init__() #conv_unit为卷积层的部分 self.conv_unit=nn.Sequential( #假设输入的是(4,3,32,32) nn.Conv2d(3,6,kernel_size=5,stride=1,padding=0), #卷积层原来的输入通道是3,然后有6块kernel,输出通道就是6,每个kernel5*5 # 上一步之后(4,6,28,28) nn.AvgPool2d(kernel_size=2,stride=2,padding=0), #下采样,使得像素宽高下降一倍 # 上一步之后(4,6,14,14) nn.Conv2d(6,16,kernel_size=5,stride=1,padding=0), # 上一步之后(4,16,10,10) nn.AvgPool2d(kernel_size=2, stride=2, padding=0), # 上一步之后(4,16,5,5) ) self.Line_unit=nn.Sequential( nn.Linear(400,120), nn.ReLU(), nn.Linear(120,84), nn.ReLU(), nn.Linear(84, 10), ) def forward(self,x): x=self.conv_unit(x) get_img_number=x.shape[0] # print('卷积层最终输出',x.shape) #[4, 16, 5, 5] x=x.reshape(get_img_number,16*5*5) # print('卷积层打平', x.shape) #[4, 400] x=self.Line_unit(x) # print('最终输出', x.shape) #[4, 10] return x # testout=Lenet5() # print(testout.forward(torch.randn(4,3,32,32)))
使用lenet5训练cifar10
import torch from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader from lenet5 import Lenet5 device=torch.device('cuda') #定义cuda设备 model=Lenet5().to(device) #将模型组放到cuda上 criteon=torch.nn.CrossEntropyLoss().to(device) #采用交叉熵进行求损失 optimizer=torch.optim.Adam(model.parameters(),lr=0.001) def main(): #打开cifar-package文件夹,训练标志位改成true,变形里面将所有的图片都改成32*32像素 batchsz=32 cifar_train=datasets.CIFAR10('cifar-package',True,transform=transforms.Compose([ transforms.Resize((32,32)), transforms.ToTensor() ])) #这里的cifar_train只是一次加载一张图片的情况,需要使用dataloader多线程来多加载照片 cifar_train=DataLoader(cifar_train,batch_size=batchsz,shuffle=True) cifar_test=datasets.CIFAR10('cifar-package',False,transform=transforms.Compose([ transforms.Resize((32,32)), transforms.ToTensor() ])) #这里的cifar_train只是一次加载一张图片的情况,需要使用dataloader多线程来多加载照片 cifar_test=DataLoader(cifar_test,batch_size=batchsz,shuffle=True) for i in range(0,5): #由于dataloader是一个迭代器,循环迭代器中的所有内容(所有图片)用的是enumerate #dataloader迭代器中总共有1563次步数(batchsz),每次读取出来的32张图,最后一次特殊,只读出了16张图所以总共是50000张图!!! #label是正确标签 model.train() for batchsz,(x,label) in enumerate(cifar_train): x=x.to(device) label=label.to(device) # print(batchsz+1) #迭代器中总共有1563次步数 # print(x.shape) #每次读取出来的32张图 #print(label.shape) logits=model(x) loss=criteon(logits,label) #将当前输出和正确的输出标签进行比较计算loss optimizer.zero_grad() #梯度清零 loss.backward() optimizer.step() print('当前loss的值',loss.tolist()) #接下来弄训练集的 check_point = 0 model.eval() #设置模型是test模式 with torch.no_grad(): #设置测试过程不需要进行求导构建图,测试就用之前训练出来的参数 total_correct=0 total_num=0 for x, label in cifar_train: x = x.to(device) label = label.to(device) logits = model(x) #此时最终出来的logits的shape应该是[32,10] pred=logits.argmax(dim=1) #对1维度上的每张图片的10种预测找出概率最大的 total_correct=total_correct+torch.eq(pred,label).float().sum() #将预测值和标签进行比较,如果一样就加入对的列表 #-----------用于查看预测值和标签 # if check_point==0: # print(logits) # print(pred) # print(label) #总共有32张图,每张图有0-9十种可能,最后预测值是一个长32的列表,里面每一个都是十种可能里面数值最大的那个的下标 #比如预测的[6,7,1,3,0],标签也是[6,7,1,3,0],那就对了 total_num=total_num+x.size(0) check_point = 1 acc=total_correct/total_num #计算精度 print('精度数值',acc) #--------测试加载一次的情况,因为dataloader一次加载batchsz张图,我们设置了32 #最终一次loader是[32, 3, 32, 32]。32张图,每张图3个通道,每个通道32*32 # x,label=iter(cifar_train).next() # print(x.shape,label.shape) main() # print('打印出神经网络模型的结构',model)
resnet的线性单元
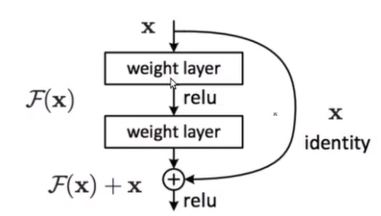
resnet模型
import torch from torch import nn from torch.nn import functional as F class Resnet_unit(nn.Module): def __init__(self,ch_in,ch_out): #resnet单元的输入和输出 super(Resnet_unit, self).__init__() self.conv1=nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=1,padding=0) #卷积层1 self.bn1=nn.BatchNorm2d(ch_out) self.conv2 = nn.Conv2d(ch_out, ch_out,kernel_size=3,stride=1,padding=0) #卷积层2 self.bn2=nn.BatchNorm2d(ch_out) self.extra=nn.Sequential() if ch_out!=ch_in: self.extra=nn.Sequential( nn.Conv2d(ch_in, ch_out, kernel_size=5, stride=1, padding=0), nn.BatchNorm2d(ch_out), ) def forward(self,x): out=F.relu(self.bn1(self.conv1(x))) out=self.bn2(self.conv2(out)) # print(out.shape) #当输入[4,3,32,32]的时候输出的是[4, 6, 24, 24] out=self.extra(x)+out #反馈路线 return out #_______测试输出情况 # net=Resnet_unit(3,6) # net.forward(torch.randn(4,3,32,32)) #当输入[4,3,32,32]的时候输出的是[4, 6, 24, 24] #这个时候就出现了一个问题,就是在反馈路线的时候out+x也就是[4,3,32,32]+[4, 6, 24, 24]明显不可行 #这个时候就需要把input转换成合适的形式他们才能相加,自己写如果chin和chout不相等加上extra class Resnet18(nn.Module): def __init__(self): super(Resnet18,self).__init__() #(4,3,32,32) self.conv1=nn.Sequential( nn.Conv2d(3,8,kernel_size=3,stride=1,padding=0), nn.BatchNorm2d(8), #[4, 8, 30, 30] ) # #接下来使用三个res单元构建resnet网络 self.unit1=Resnet_unit(8,16) #[4, 16, 26, 26] self.unit2 = Resnet_unit(16, 20) #[4, 20, 22, 22] self.unit3 = Resnet_unit(20, 32) #[4, 32, 18, 18] #[4,32*18*18] self.linelayer1=nn.Linear(32*18*18,10) #[4,10] def forward(self,x): out=F.relu(self.conv1(x)) out=self.unit1.forward(out) out = self.unit2.forward(out) out = self.unit3.forward(out) out=out.reshape(out.shape[0],32*18*18) out=self.linelayer1(out) # print(out.shape) return out #---------参数测试 # net=Resnet18() # net.forward(torch.randn(4,3,32,32))
import torch from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader from lenet5 import Lenet5 from resnet import Resnet18 device=torch.device('cuda') #定义cuda设备 model=Resnet18().to(device) #将模型组放到cuda上 criteon=torch.nn.CrossEntropyLoss().to(device) #采用交叉熵进行求损失 optimizer=torch.optim.Adam(model.parameters(),lr=0.001) def main(): #打开cifar-package文件夹,训练标志位改成true,变形里面将所有的图片都改成32*32像素 batchsz=32 cifar_train=datasets.CIFAR10('cifar-package',True,transform=transforms.Compose([ transforms.Resize((32,32)), transforms.ToTensor() ])) #这里的cifar_train只是一次加载一张图片的情况,需要使用dataloader多线程来多加载照片 cifar_train=DataLoader(cifar_train,batch_size=batchsz,shuffle=True) cifar_test=datasets.CIFAR10('cifar-package',False,transform=transforms.Compose([ transforms.Resize((32,32)), transforms.ToTensor() ])) #这里的cifar_train只是一次加载一张图片的情况,需要使用dataloader多线程来多加载照片 cifar_test=DataLoader(cifar_test,batch_size=batchsz,shuffle=True) for i in range(0,5): #由于dataloader是一个迭代器,循环迭代器中的所有内容(所有图片)用的是enumerate #dataloader迭代器中总共有1563次步数(batchsz),每次读取出来的32张图,最后一次特殊,只读出了16张图所以总共是50000张图!!! #label是正确标签 model.train() for batchsz,(x,label) in enumerate(cifar_train): x=x.to(device) label=label.to(device) # print(batchsz+1) #迭代器中总共有1563次步数 # print(x.shape) #每次读取出来的32张图 #print(label.shape) logits=model(x) loss=criteon(logits,label) #将当前输出和正确的输出标签进行比较计算loss optimizer.zero_grad() #梯度清零 loss.backward() optimizer.step() print('当前loss的值',loss.tolist()) #接下来弄训练集的 check_point = 0 model.eval() #设置模型是test模式 with torch.no_grad(): #设置测试过程不需要进行求导构建图,测试就用之前训练出来的参数 total_correct=0 total_num=0 for x, label in cifar_train: x = x.to(device) label = label.to(device) logits = model(x) #此时最终出来的logits的shape应该是[32,10] pred=logits.argmax(dim=1) #对1维度上的每张图片的10种预测找出概率最大的 total_correct=total_correct+torch.eq(pred,label).float().sum() #将预测值和标签进行比较,如果一样就加入对的列表 #-----------用于查看预测值和标签 # if check_point==0: # print(logits) # print(pred) # print(label) #总共有32张图,每张图有0-9十种可能,最后预测值是一个长32的列表,里面每一个都是十种可能里面数值最大的那个的下标 #比如预测的[6,7,1,3,0],标签也是[6,7,1,3,0],那就对了 total_num=total_num+x.size(0) check_point = 1 acc=total_correct/total_num #计算精度 print('精度数值',acc) #--------测试加载一次的情况,因为dataloader一次加载batchsz张图,我们设置了32 #最终一次loader是[32, 3, 32, 32]。32张图,每张图3个通道,每个通道32*32 # x,label=iter(cifar_train).next() # print(x.shape,label.shape) main() # print('打印出神经网络模型的结构',model)

时间序列表示法
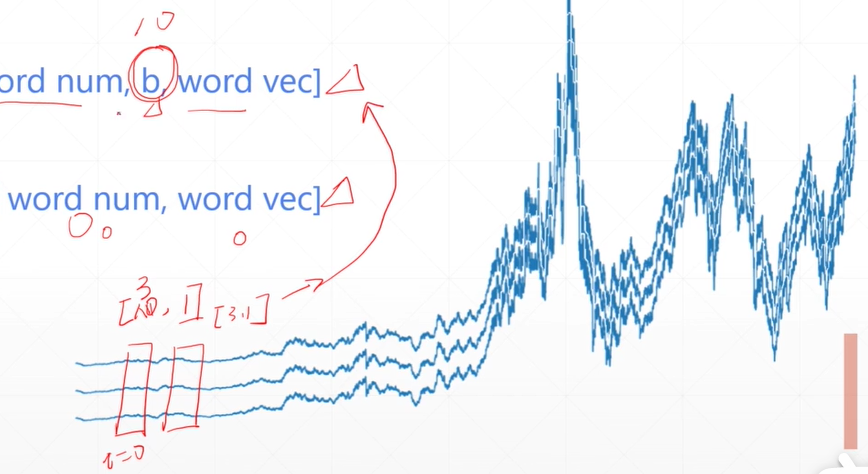
[1,3,1]表示在时间在t=1时刻,总共有三条曲线,每条曲线的值有一个
[5,3,100]表示的是有五个单词,这些单词构成3句话,每个单词用100维的向量进行表示
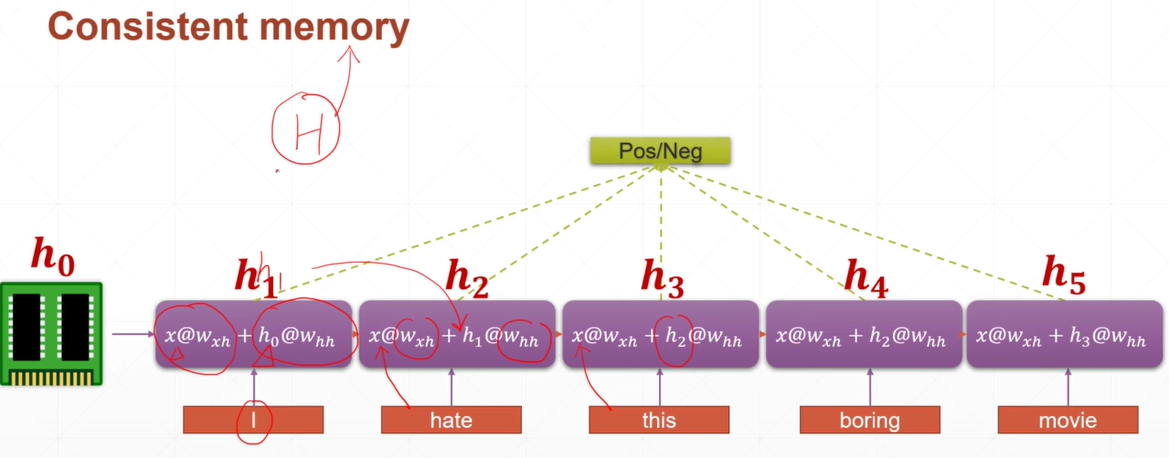
现在的目标是输入一句话然后对它进行判断,判断出这句话持肯定态度还是否定态度,这个时候每一个单词的部分都由两个部分构成
一个部分是共享权值wxh*输入,另一部分是历史记忆部分(这样就可以作出与之前上文有关的特点)。比如i中的h1=h0*whh,h0来自
上一次的历史记忆。h2=h1*whh,h1来自上一次的历史记忆
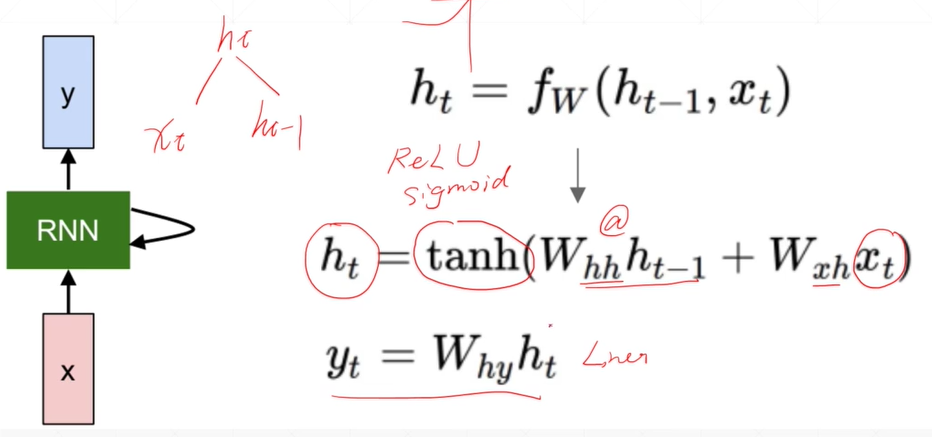
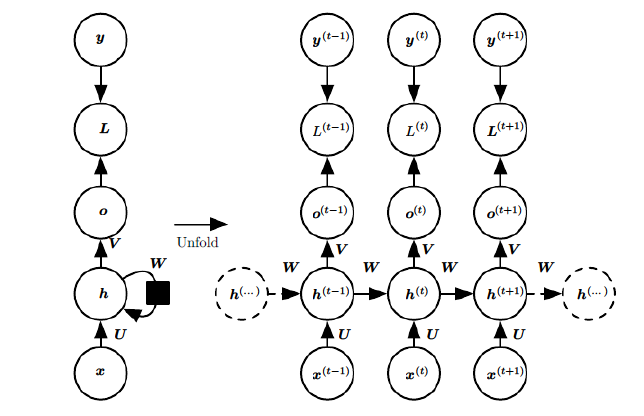
基础的神经网络只在层与层之间建立了权连接,RNN最大的不同之处就是在层之间的神经元之间也建立的权连接。
import torch import torch.nn.functional as F # 两种结构 # 第一种(时刻,曲线数量,曲线上的值是用多大的向量表示) # 第二种(单词数,句子数,每个单词是用多大的向量表示) rnn=torch.nn.RNN(input_size=100,hidden_size=20,num_layers=1) #input_size是曲线上的值是用多大的向量表示或者每个单词是用多大的向量表示 print(rnn._parameters.keys()) for i in rnn._parameters.values(): print(i.shape) #hidden_size是经过rnn层input_size会降到多少,代表记忆状态 x=torch.randn(10,3,100) #注意这里的第三位一定要和input_size匹配 out,h=rnn(x) print('out是所有时刻/单词上的',out.shape,'h是最后时刻/单词上的',h.shape)
下面这种比较好用,用下面的程序中这种
import torch import torch.nn.functional as F # 两种结构 # 第一种(时刻,曲线数量,曲线上的值是用多大的向量表示) # 第二种(单词数,句子数,每个单词是用多大的向量表示) cell1=torch.nn.RNNCell(input_size=100,hidden_size=30) #input_size是曲线上的值是用多大的向量表示或者每个单词是用多大的向量表示 cell2=torch.nn.RNNCell(input_size=30,hidden_size=20) h1=torch.zeros(3,30) #初始的h1是(三个曲线,隐藏层数30) h2=torch.zeros(3,20) ##初始的h2是(三个曲线,隐藏层数20) #hidden_size是经过rnn层input_size会降到多少,代表记忆状态 x=torch.randn(10,3,100) #注意这里的第三位一定要和input_size匹配。十个时刻,三个曲线,曲线上用100的向量表示 for i in x: #每次取出一个时刻的(3,100) # print(i.shape) h1=cell1(i,h1) #每次都是上一级输入和hi进行运算 h2=cell2(h1,h2) print(h2.shape)
预测正弦曲线
输入的是一个有相位偏移的sin函数的样本数据,标准标签y是没有相位偏移的sin函数
import numpy as np import torch from torch import nn from matplotlib import pyplot as plt num_time_steps=50 #生成的数据里面总共有50个点 input_size=1 hidden_size=16 output_size=1 lr=0.01 class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.rnn=nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=1, batch_first=True #如果要用[1,49,1]代表有一条曲线,这条曲线有49个时刻点,每个时刻点上一个值。就要设置batch_first=True ) for p in self.rnn.parameters(): nn.init.normal_(p,mean=0.0,std=0.001) self.linear=nn.Linear(hidden_size,output_size) def forward(self,x,h_prev): #输入的x是[1, 49,1] out,h_prev=self.rnn(x,h_prev) # print(out.shape,hidden_prev.shape) #放进rnn后出来的out是[1, 49, 16],最后一个时刻的是hidden_prev[1, 1, 16] out=out.reshape(-1,hidden_size) # print(out.shape) #后面的线性层是要把16变成1,那么前面的[1,49,16]就要进行变换成[49,16],等和线性层[16,1]进行变换 out=self.linear(out) # print(out.shape) #线性层出来后变成[49, 1] out=out.unsqueeze(dim=0) # print(out.shape) #再拓宽一个维度变成[1, 49, 1] return out,h_prev model=Net() criteon=nn.MSELoss() optimizer=torch.optim.Adam(model.parameters(),lr) h_prev=torch.zeros(1,1,hidden_size) #[多少个曲线,rnn中的num_layers层数,隐藏层层数] for iter in range(2000): # ----------生成样本数据----------- start = np.random.randint(3, size=1)[0] # 随机生成1到3之间的整数 # print(start) time_steps = np.linspace(start, start + 10, num_time_steps) # 生成从start到start+10之间的十个数字当作x轴 # print(time_steps) data = np.sin(time_steps) # 对其计算sin当作y轴 # print(data) data = data.reshape(num_time_steps, 1) # 将y轴数据改成列向量 # print(data) x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1) #注意这里的x指的是从0-48,总共49个数据,x是用于训练的输入 y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1) #注意这里的y值1-49,总共49个数据,y是正确的标签 #现在是用有一点相位偏移的数据x来进行输入,输出与没偏移的y来进行求均方根误差 #需要弄出来的x输入是[1,49,1]代表有一条曲线,这条曲线有49个时刻点,每个时刻点上一个值。 # print(x.shape) # print(y.shape) output,h_prev=model(x,h_prev) #把输入x(有偏移的错误的sin函数数据)放进模型里进行训练 h_prev=h_prev.detach() #hidden_prev不参与梯度计算,hidden_prev也就是hi,相当于之前的记忆体 loss=criteon(output,y) model.zero_grad() #清空倒数信息 loss.backward() optimizer.step() if iter%100==0: print(iter,loss.item()) #__________接下来是进行预测的部分,上面已经把模型的参数设计好——————接下来就是设定一个初始点,然后放进模型里面进行预测,将预测出来的值再 #放进模型进行迭代下一次预测 start = np.random.randint(3, size=1)[0] # 随机生成1到3之间的整数 # print(start) time_steps = np.linspace(start, start + 10, num_time_steps) # 生成从start到start+10之间的十个数字当作x轴 # print(time_steps) data = np.sin(time_steps) # 对其计算sin当作y轴 # print(data) data1 = data.reshape(num_time_steps, 1) # 将y轴数据改成列向量 # print(data) x = torch.tensor(data1[:-1]).float().view(1, num_time_steps - 1, 1) # 注意这里的x指的是从0-48,总共49个数据,x是用于训练的输入 y = torch.tensor(data1[1:]).float().view(1, num_time_steps - 1, 1) # 注意这里的y值1-49,总共49个数据,y是正确的标签 # print(time_steps) predictions=[] print(data[0]) input=torch.tensor([[[data[0]]]]).float() #输入的初始点是标准的sin的值的列表的第0位 # print(input.shape) for i in range(0,50): pred,h_prev=model(input,h_prev) #把输入放进模型得到预测出来的值和记忆块hi input=pred#将预测值赋予下一次的输入 # print(pred) predictions.append(pred.tolist()[0][0][0]) #把预测值放进列表好出图 plt.scatter(time_steps,data) #这里画出来的是以时刻列表time_steps为x轴,相应的标准的sin的值的列表为y轴 plt.scatter(time_steps,predictions) #这里画出来的是以时刻列表time_steps为x轴,相应的预测值当y轴 plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号