自己总结
数据字段说明
一共有85个字段,包含用户和广告等数据
字段在Log类中,按照scala语法:由于元组一次无法传入85个字段,所以Log类中用了extends Product
ETL需求实现
在ETL2HDFS类中
初始化环境的时候,指定序列化方式:serializer,默认压缩方式为snappy,默认保存格式为parquet
// 初始化
val conf = new SparkConf()
// 指定序列化方式
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setAppName(this.getClass.getName)
.setMaster("local[2]")
切分为85个字段
数据过滤
指定schema生成DataFrame
// 切分并过滤
val filtered: RDD[Log] = datas
.map(line => line.split(",")) // 切分
.filter(_.length == 85) // 过滤 判断切分出来的字段是不是85个字段
.map(arr => Log(arr)) // 指定schema
// 生成df
val logsDF: DataFrame = spark.createDataFrame(filtered)
持久化到HDFS,默认保存方式为parquet
logsDF.write.mode(SaveMode.Append).save(output)
报表的统计
统计各省市数据量分布情况
在ProCityRpt类中
以省市进行分组,组内进行数据量统计
首先通过sparkSession对象获取数据,然后注册临时表,通过sql对临时表进行操作,来查询省,市以及数量等信息,
// 获取数据
val logsDF = ss.read.parquet(input)
// 注册临时表
logsDF.createOrReplaceTempView("t_log")
// 用sql进行操作
val sql = "select provincename, cityname, count(*) as cts from t_log group by provincename, cityname"
val countsDF = ss.sql(sql)
// 将df存储到mysql
val load = ConfigFactory.load()
val url = load.getString("jdbc.url")
val table = load.getString("jdbc.rpt_pc_count") //指定要创建的数据库表名
val props = new Properties()
props.put("user", load.getString("jdbc.user"))
props.put("password", load.getString("jdbc.password"))
countsDF.write.mode(SaveMode.Append).jdbc(url, table, props)
// 练习:存储到本地磁盘
// countsDF.repartition(1).write.mode(SaveMode.Append).json("d://out")
注意:数据库中的表可以没有,会进行自动创建,但是数据库必须得有,数据库不会自动创建
地域分布
在LocationCount对象中
用于计算报表指标的在utils下的RptUtils对象中
按照省市进行分组,组内聚合
其中有两个求比率的指标,在这里不做实现,在真正展示的时候拿到基础的聚合值去比较即可。
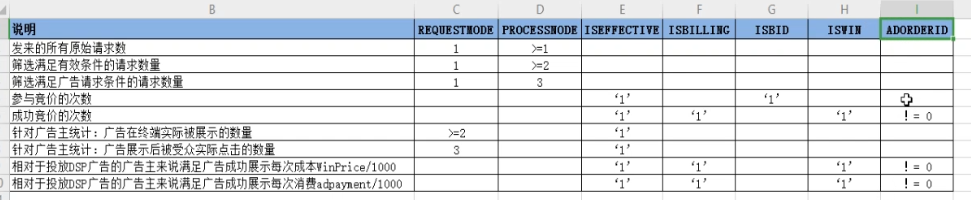
媒体分析统计的实现(sparkcore和sparksql)
需要注意扩展字典的获取和判断
扩展字典在统计的过程中,有时候需要不断地丰富里面的内容,此时用hdfs存储是不合适的,可以用redis存储,而且随着字典的不断更新,我们的应用程序也需要做多更新,这时可以直接获取redis的数据即可,不用广播变量。这种方式即节省缓存又可以灵活的更新数据。
用SparkCore和SparkSQL分别实现该需求
背景:为了给rtb作为分析用户行为习惯的基础数据,rtb通过对应的userid取到对应的标签数据,来分析用户,给用户推荐相应的广告产品。
标签的数据格式:key,value
key:用户操作的行为,比如点击的广告,操作某个媒体,输入的关键字等
value:用户操作该行为的次数
最终生成的标签是:(userid, List((tag, count),(tag, count),(tag, count)...))
关于userid需要注意的地方:rtb接收到的userid不是用户在媒体上注册的userid,因为不同的媒体产生不同的userid,这样会让rtb无法找到对应的标签。实际上rtb拿到 的userid就是于用户操作设备id或系统id。
商圈标签
为什么生成商圈标签,通过分析用户的地理位置(经纬度),解析出附近的商圈信息,就可以给该用户推荐对应的店铺或商品了
GeoHash
用字符串代表经纬为中心的一个矩形范围,GeoHash值之间越相似代表这两个值的位置越相近。字符串的长度代表范围的精度,越长精度越高。
GeoHash的应用场景
生成商圈标签过程中,如果将经纬度信息作为key进行聚合,而经纬度信息又比较精确,无法代表范围进行聚合。所以最好将经纬度信息转化为一个个分为信息,然后再生成对应的标签,此时用GeoHash操作。最终的目的是方便的给用户推荐附近一定范围内的店铺或相关商品。
GeoHash值的范围是通过生成字符串的长度决定的,length越大代表范围越小。一般生成用户画像中的商圈标签,GeoHash值的长度为6~8位。
对接百度地图
1、注册百度地图
2、生成密钥(创建应用)
3、调用api请求地图信息的代码实现
1、主要就是为了节约成本,通过经纬度获取到地理位置信息后存储到redis
2、提高效率,一个是网络传输,一个是获取自己的redis数据,肯定是获取redis的过程提高效率
注意:一定要定时更新redis中的商圈信息,多长时间更新一次,需要看业务的需求。
昨天操作的标签的聚合过程中,我们只是拿到第一个不为空的userid作为结果标签的数据的key,这样有可能出现一个问题,就是一个用户在不同的系统或不同的设备中的操作,一定会生成不同的userid,这样生成的标签一定不会聚合在一起。我们可以用图计算的方式实现同一个用户不同userid的标签数据尽量给关联起来。
图计算介绍
用图计算实现的过程,首先需要构建点的集合,再构建边的集合,最后调用图计算生成关系并进行join生成最后的关系结果数据。
图计算生成标签合并聚合过程
在GraphTagsContext类中,接收3个参数val Array(input, stopwords, day) = args
然后进行初始化,获取数据,获取停用字典, 对数据进行过滤(即对数据中的15个字段进行过滤,只要有不为空的即可),
将过滤后的数据生成key-value数据useridListAndRow=(useridList, row),
--构建点的集合{
获取redis连接
对useridListAndRow进行flatmap处理{
获取用户id集合useridList
获取row数据
// --生成广告标签和渠道标签
// --生成媒体标签(额外用到jedis)
// --生成设备标签
// --生成关键字标签(stopKeyWordsBroadcast)
// --生成地域标签
// --生成商圈标签
// 合并标签
val rowTag = adAndPlatformTag ++ appTag ++ deviceTag ++ keywordTag ++ locationTag
// 操作前:List((标签, 1),(标签, 1),(标签, 1),...)
// 操作后:List((userid, 0),(userid, 0),(userid, 0),(标签, 1),(标签, 1),(标签, 1),...)
val vd: List[(String, Int)] = useridList.map((_, 0)) ++ rowTag
最后获取useridList中的第一个uid作为顶点(每条数据有多个不同的uid),携带vid,(uid.hashCode.toLong, vd)
} }
--构建边的集合
useridList.map(uid => {
Edge(useridList.head.hashCode.toLong, uid.hashCode.toLong, 0) //(useridList的第一个uid,map出的useridList里uid)得到的是很多的(k,v)
}
生成图计算对象并进行图计算,然后再join点集合,再去除相同的uid
val graph = Graph(vertexRDD, edgeRDD)
val vertices: VertexRDD[VertexId] = graph.connectedComponents().vertices
// 将数据join进来并调整数据
val joinedRDD: RDD[(VertexId, (VertexId, List[(String, Int)]))] = vertices.join(vertexRDD)
val mapedRDD: RDD[(VertexId, List[(String, Int)])] = joinedRDD.map{case (uid, (commonid, useridAndTags)) => (commonid, useridAndTags)}
最后聚合标签里的数据,得到的结果是 RDD[(VertexId, List[(String, Int)])]类型的
// 聚合标签数据
//groupBy(_._1)根据第一个值进行groupBy
val sumedTags: RDD[(VertexId, List[(String, Int)])] = mapedRDD.reduceByKey{
case (list1, list2) => (list1 ++ list2).groupBy(_._1).mapValues(_.map(_._2).sum).toList
}
关于每天的标签结果数据存储到hbase和最终标签数据存储到es的问题描述
hbase可以存储大量的数据,可以提供很快的检索速度,可以指定某个字段当做检索的key值,检索很快,标签数据不就是k,v数据嘛,最终的数据可以用hbase和es存储
为什么用es存储最终的标签数据呢,一方面是es可以存储海量的数据,一方面es可以提供丰富的检索功能。
关于标签的衰减问题描述
在生成最终的标签数据之前(指定是在hbase和es做标签合并之前),也就是在合并标签之前,需要进行标签数据的衰减,目的是为了提高标签的有效性,标签的聚合值需要和 衰减系数(83%)相乘,得到的结果进行判断,看是否小于阈值(0.5),如果小于直接过滤掉,如果不小于阈值则和hbase生成的标签进行合并聚合。(权重就是自己算的聚合后的值,今天最终的标签=今天的标签+昨天最终的标签)
关于标签模型的分类和数量
分类的方式有多种,可以根据用户的不同的特征去分,可以根据业务的模型去分等等,一般会按照用途去分:用户基本信息(姓名,电话,住址,家庭住址)、用户行为习惯(喜欢去哪旅游,喜欢去健身房或者那些地方)、购物习惯、不同领域的定位(每次坐飞机都是头等舱是个有钱大佬)
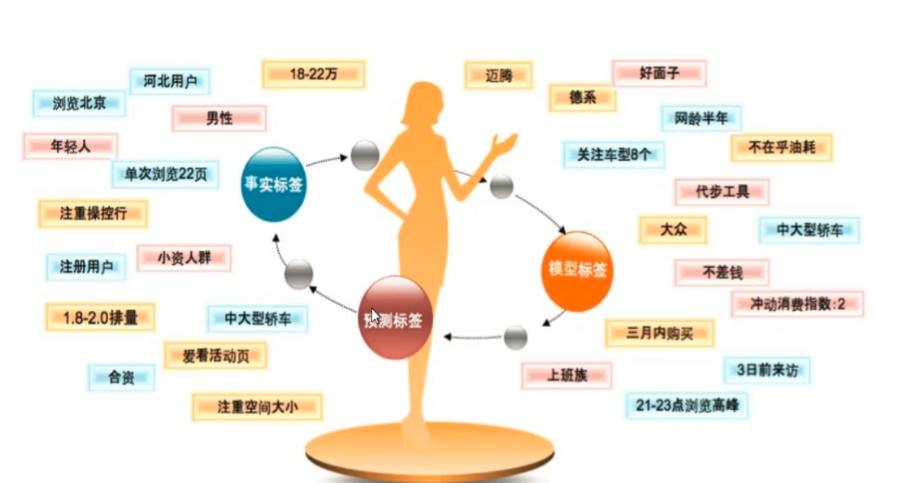
当面试官问你做过哪些标签的时候,可以说我们根据业务将标签分为大致几种(比如上图中的事实,模型,预测等),我主要负责做模型标签,具体的标签有:代步工具,大众,三月内购买,上班族等标签。说到10个就可以了

