自己总结
数据采集
开始要进行数据采集,就是运行爬虫脚本,爬虫脚本项目名为spider-csair.
运行准备:要开始nginx服务,在master上,/opt/apps/openristy/nginx/sbin/ 下,运行./nginx
每个机器上都运行zkServer.sh start开启zookeeper服务,然后就可以开启kafka,[root@hadoop01 kafka_2.11-1.1.1]# nohup ./bin/kafka-server-start.sh ./config/server.properties > /zj/log/kafka.log 2>&1 &
通过shell消费消息/opt/apps/kafka/bin/kafka-console-consumer.sh --zookeeper master:2181 --from-beginning --topic nginxdata1906可以查看运行结果,接下来就可以运行spider-csair来获得采集到的数据了。
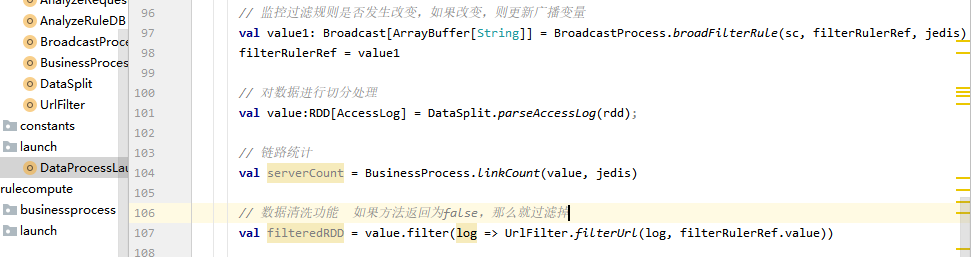
在数据采集的时候,做了一个链路统计的事情,就是在上面的基础上,对接redis,对接的时候,将数据封装成rdd,然后再map和ruduceByKey,得到结果为(server_addr, n),把这样的结果存入到redis中,可以在redis客户端中用keys *查看
数据清洗
数据已经从kafka获取过来了,已经用“#CS#”进行了数据的拼接,数据清洗的过滤规则保存在数据库中,需要获取数据库过滤规则到程序 中,并广播出去,但是规则是动态变化的,如果使用广播变量,需要做判断,判断数据库一旦发生变化,则重新广播,这时需要用到redis的标识标识为FilterChangerFlag,通过读取标识判断是否需要更新过滤规则。

数据脱敏:
用户请求数据里面携带了用户敏感数据,比如手机号、身份证号,为了安全性考虑,需要对数据做脱敏处理
在数据采集过来后,需要用正则匹配的方式进行匹配对应的需要脱敏的数据,匹配 成功后,再进行加密
代码实现:
手机号加密过程 ,首先定义正则,匹配字符串中的手机号,找到手机号的前一个字符和后一个字符,判断是否是数字,如果不是数字就替换,相反就不替换
身份证加密过程和手机号雷同
最后把加密的字符串替换手机号和身份证号
业务类为EncryedData
数据分类
获取脱敏后的数据进行分割,分割出一个个字段,获取request这个字段进行分类判断,判断是属于哪种类型(国内查询、国际查询、国内预定、国际预定),这些 类型还分单程和往返,所以一共 有八种类型。当前匹配出类型后,将数据进行打标签(打标签就是给数据标识 是0 或者1),再通过url匹配出的类型去数据库读取规则,进行body解析
分类规则表:nh_classify_rule
在mysql的nh_classify_rule中,flight_type 0表示国内,1表示国外,operation_type 0表示查询,1表示预定
需求实现:
获取规则表并进行广播(从数据库获取,在)
实时监控规则信息是否更新(就是在redis里设置标签 ClassifyRuleChangeFlag)
按照分类规则进行数据分类
获取分类规则业务类:AnalyzeRequest,对分类规则进行处理并广播的业务类:BroadcatProcess,分类打标签业务类:RequestTypeClassifer
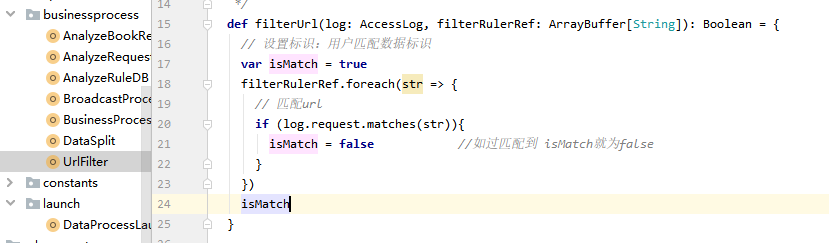
获取单程还是往返分类:用的是过滤后的数据中的http_referer字段进行分类判断,方法与上述一致。
// 单程或往返标签
val travelType = TravelTypeClassifier.classifyByRefererAndRequestBody(log.http_referer)
数据解析
分类好的数据其实是乱码的,我们人为看不清,就需要对这种数据进行解析,具体实现
封装的bean有QueryRequestData和BookRequestData。在解析的过程中,指定了标识AnalyzeRuleChangeFlag,标识放在redis中。具体就是当解析规则封装到bean的AnalyzeRule中的时候,进行数据解析时要进行广播,先获取redis里的标识,标识为true表示解析规则发生变化。查询数据解析在AnalyzeRequest中,解析好将数据封装到bean的QueryRequestData中;预定数据解析在AnalyzeBookRequest,解析好的数据封装到bean的BookRequestData中。
数据是人所看不懂的,在进行规则匹配后,就可以得到人能看懂的数据
// 标识
val needUpdateAnalyzeRule = jedis.get("AnalyzeRuleChangeFlag")
// 判断
if (!needUpdateAnalyzeRule.isEmpty && needUpdateAnalyzeRule.toBoolean) {
// 查询规则
val queryRules = AnalyzeRuleDB.queryRule(0)
// 预定规则
val bookRules = AnalyzeRuleDB.queryRule(1)
// 用于存储规则数据
val queryBooks = new mutable.HashMap[String, List[AnalyzeRule]]()
queryBooks.put("queryRules", queryRules)
queryBooks.put("bookRules", bookRules)
queryBookRuleBroadcast.unpersist()
jedis.set("AnalyzeRuleChangeFlag", "false")
sc.broadcast(queryBooks)
} else {
queryBookRuleBroadcast
}
在DataProcessLauncher的main中:
// 数据解析
// 查询数据的解析
val queryRequestData = AnalyzeRequest.analyzeQueryRequest(
requestTypeLable, log.request_method, log.content_type,
log.request, log.request_body, travelType,
queryBookRuleBroadcast.value("queryRules")
)
// 预定数据的解析
val bookRequestData = AnalyzeBookRequest.analyzeBookRequest(
requestTypeLable, log.request_method, log.content_type,
log.request, log.request_body, travelType,
queryBookRuleBroadcast.value("bookRules")
)
数据加工(判断是否是高频率ip)
就是查找黑名单的。
在数据处理的时候,如果出现了历史黑名单ip,我们要进行标记,这就是高频ip
所以,首先需要读取数据库的黑名单数据,加载并广播
还需要实现实时监控广播变量更新逻辑:监控是否改变就是在redis中设置IpBlackRuleChangeFlag标识
通过请求数据的ip和黑名单数据进行比较,打上相应的标签(高频ip)
// 获取ip黑名单信息
val ipBlackList = AnalyzeRuleDB.queryIpBlackList()
// 广播黑名单
@volatile var ipBlackListRef = sc.broadcast(ipBlackList)
// 监控黑名单是否发生改变
ipBlackListRef = BroadcastProcess.ipBlackListRule(sc, ipBlackListRef, jedis)
如果改变就用从数据库中获取的黑名单,再吧redis里的标识IpBlackRuleChangeFlag设为false,否则就用原来的黑名单
数据结构化
将数据按照ProcessedData格式封装,其中有日期格式、集合格式数据需要转换为字符串,后期会将数据处理后的 终结果ProcessedData发送kafka供后续rulecompute业务进行处理
// 数据结构化,“”:原始数据,业务暂时没涉及到,所以给空字符串;log日志,包括很多;分类标签(国内,国际,查询,预定),单程/往返标签,请求数据的解析,预定数据的解析,高频率Ip
DataPackage.dataPackage( //数据结构化(打包)的具体实现在DataPackage中
"", log, requestTypeLable, travelType, queryRequestData,
bookRequestData, highFrqIpGroup)
用//dataProcess.foreach(println) //我自己进行的测试
来进行查看数据(注:这里foreach的使用,结果还留在executor端,没有到达Driver端)

数据推送
-
-
将数据经过过滤,将数据放到consumer的send方法中发送到kafka
-
需要生成两个生产者做数据的生产,一个负责写查询数据,一个负责写预定数据

要在kafka中创建两个主题
processedQuery:存放处理后的查询数据,
processedBook:存放处理后的预定数据
可以用kafka的shell消费消息命令查看结果:/opt/apps/kafka/bin/kafka-console-consumer.sh --zookeeper master:2181 --from-beginning --topic processedQuery

实时监控
在任务运行的过程中,我们需要对任务进行实时的监控,每处理一批数据,我们要看下处理的速度和时间,还有状 态,从而能显著的跟踪任务的进行状态。其实就是监控数据量。
实时监控用到spark,开启spark:./bin/spark-shell ,在localhost:4040中可以看到job提交流程处理。这里我用的单机版spark,直接用http://localhost:4040/metrics/json/ (记录日志的)来获取日志数据信息然后数据是json的,可以json解析,包含appid,appname,拿到批处理的开始时间和结束时间,计算批处理花费的时间


任务速度的监控:批处理的平均计算速度 = 批处理的数据量 / (批处理结束时间 - 批处理开始时间)
// 为了做监控统计,需要调用action拿到链路的流量
val serverCountMap = serverCount.collectAsMap()
// 实时监控
SparkStreamingMonitor.streamMonitor(sc, rdd, serverCountMap, jedis)
在SparkStreamingMonitor中
// appid
val appid = sc.applicationId
// appname
val appname = sc.appName
// 指定当前app的4040服务路径
val url = "http://localhost:4040/metrics/json/"
// 通过4040服务获取json数据
val jsonObj = SparkMetricsUtils.getMetricsJson(url)
// 获取gauges
val result = jsonObj.getJSONObject("gauges")
// startTimePath
val startTimePath = appid + ".driver." + appname + ".StreamingMetrics.streaming.lastCompletedBatch_processingStartTime"
// startTime
val startTime = result.getJSONObject(startTimePath)
// 转换为long类型,便于 计算
var processStartTime: Long = 0L
// 判断是否为空
if (startTime != null) {
processStartTime = startTime.getLong("value")
}
反爬虫统计字段规则
总体统计:
192.168.56.112 244.12.134.56 单位时间内的IP段访问量(前两段)
基于IP的统计
单位时间内的访问总量
单位时间内的关键页面访问总量
单位时间内的UA出现次数统计
单位时间内的关键页面最短访问间隔
单位时间内小于最短访问间隔(自设)的关键页面查询次数
单位时间内关键页面的访问次数的Cookie数少于X(自设)
单位时间内查询不同行程的次数

获取kafka的query数据并进行处理,按照“#CS#”进行切分,就是消费
将切分的数据进行结构化封装,ProcessedData
加载实时统计计算的数据库规则,同步到广播变量,实时更新广播变量
将结果封装进行打分
根据打分分数阈值过滤ip,进行黑名单的统计
消费Kafka数据并拆解和封装
获取kafka数据
切分并解析
封装到ProcessedData
加载规则
需要加载数据库规则,共后期指标的计算
需要加载的规则:
关键页面(也会动态改变,需要更新关键页面数据)需要广播 nh_query_critical_pages
ip黑名单 需要广播 nh_blacklist
注意:流程是动态变化的,而且在运行时只能有一个流程起作用,多个流程会逻辑混乱
* 根据页面内容,流程分实时、准实时、离线,我们现在仅实现实时
* status的值,0代表开启,1代表关闭
统计指标:
获取结构化数据
判断ip是否为空,如果为空(“null”, 1)
窗口操作:reduceByKeyAndWindow,窗口长度为5分钟,滑动间隔为批次间隔的大小,注意:窗口长度和滑动间隔一定是批次间隔的倍数
某个IP,5分钟内总访问量
某个IP,5分钟内的关键页面访问总量
某个IP,5分钟内的UA种类数统计
某个IP,5分钟内的关键页面最短访问间隔
获取规则,匹配request的关键页面,判断当前是否是关键页面
在获取当前url的时候和ip加关键页面
返回((ip, 关键页面), 时间)
分组取value,对时间做转换,然后排序获取时间差
最后返回最小时间间隔
某个IP,5分钟内小于最短访问间隔(自设)的关键页面查询次数
实现思路同上,只不过加上相关阈值做判断即可
某个IP,5分钟内查询不同行程的次数
某个IP,5分钟内关键页面的访问次数的Cookie数
nh_rules_maintenance_table:规则名称表
nh_strategy:阈值表
nh_rule:规则明细表
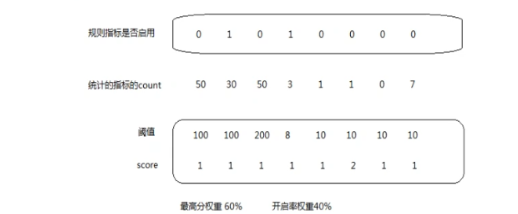
涉及到的字段:

最高分权重60%,满分 60分,如果已经超过了60分,已经是黑名单了
最高分权重计算:统计出每个指标的count,如果你的count值大于阈值,取对应的score,前提是 这个指标是否启动,每个开启 的指标的score的值相加,再乘以0.6,看是否达到60分
开启率权重:指规则开启的数量的权重,需要计算开启指标的数量和指标总数的比值
实现思路:
-
通过上面的指标进行封装样例类,供后期打分使用
-
通过ip和request,取出统计结果,封装到map中
-
通过循环规则,进行数据封装,将数据封装到方法中,通过计算打分判断阈值,再进行每个规则开启和关闭判断
-
根据命中规则,来计算分值权重(40%)
-
再使用算法进行反爬的分数计算
-
得到最终的分数,返回当前ip是否是爬虫
-
将结果封装到AntiCalculateResult
过滤非黑名单
过滤非黑名单:用filter进行过滤,通过判断打分是否超过阈值,如果超过阈值,那么就是黑名单数据。
//阈值判断结果,打分值大于阈值,为true,那就是黑名单
flowScore.isUpLimited //获取flowScore的isUplimited属性,此属性是boolean的
对黑名单去重
// 过滤掉重复的数据,(ip,流程分数)相同的key和value,取key,起到过滤效果
val distincted: RDD[(String, Array[FlowScoreResult])] = rdd.reduceByKey((x, y) => x)
// 反爬虫黑名单数据(ip,流程分数)
val antiBlackList: Array[(String, Array[FlowScoreResult])] = distincted.collect()
黑名单reids恢复
从hdfs到redis
因为redis是内存数据库,为了防止redis数据丢失,我们会在代码中设置数据恢复过程,因为之后我们会将黑名单 的结果推送到hdfs,所以在这里我们可以预先将hdfs的数据恢复到redis,避免redis数据丢失 注意,只有在redis中dang的值不为no的时候才会进行数据恢复
黑名单数据备份到redis
streaming消费kafka数据黑名单备份到reids。
将黑名单数据实时存储到redis,redis黑名单库中的键 ip:flowId,redis黑名单库中的值: flowScore|strategyCode|hitRules|time
1、 循环黑名单数据
2、 创建redis的key和value
3、 存储黑名单数据到redis,设置超时时间为1小时
4、 添加黑名单DataFrame-备份到ArrayBuffer
黑名单数据实时存储hdfs,用于redis数据恢复
为了防止数据丢失,需要将DataFrame实时存储到hdfs中,用于redis数据恢复
构建datafream, 存储datafream
将kafka中的结构化的数据同步到hdfs中
将数据处理后到kafka中的结构化的数据同步到hdfs
高内聚,低耦合,和封装
(oop)面向对象编程的一个关键原则之一就是封装,把暴漏的数据封装起来,尽可能的让对象管理它们自己的状态,因为过多的依存性会造成紧耦合性系统,使得任意一点小的改动都可能造成许多无法预料的结果。而数据封装机制是一个控制对象数据和状态强有力的方法,它对外部世界隐藏其内部细节,这就意味着每一个对象都应该尽可能少的了解系统的其他部分或者被其他部分所了解,这样一来一旦发生了变化,需要了解这一个变化的对象会比较少,因此变化也就相对来说便于改动。
内聚:内聚指的是一个模块内部各部分之间的关联程度,一个好的内聚模块应当只做好一件事
耦合:耦合指各个对象之间的关联程度。它影响
封装原则:隐藏对象的属性和实现细节,仅对外公开接口,并且控制访问层级。
在面向对象方法中,用类来实现上面的要求,用类来实现封装,用封装来实现高聚合,低耦合。

