Hadoop 的安装和使用
Hadoop包括三种安装模式:
-
单机模式:只在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统HDFS;
-
伪分布式模式:存储采用分布式文件系统HDFS,但HDFS的名称节点和数据节点都在同一台机器上;
-
分布式模式:存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上;
Hadoop安装步骤:
- 准备Hadoop、Jdk压缩包
- 更新软件包最新列表
- 安装SSH
- 安装Java并配置环境
- 安装Hadoop
- 运行Hadoop样例
1. 准备Hadoop、Jdk压缩包
- Jdk:由于官网下载jdk还要登录oracle账号很麻烦,可自行通过百度等其它方式下载
- Hadoop:https://hadoop.apache.org/releases.html
注:binary是编译好的可以直接使用,source是还没编译过的源代码,需要自行编译
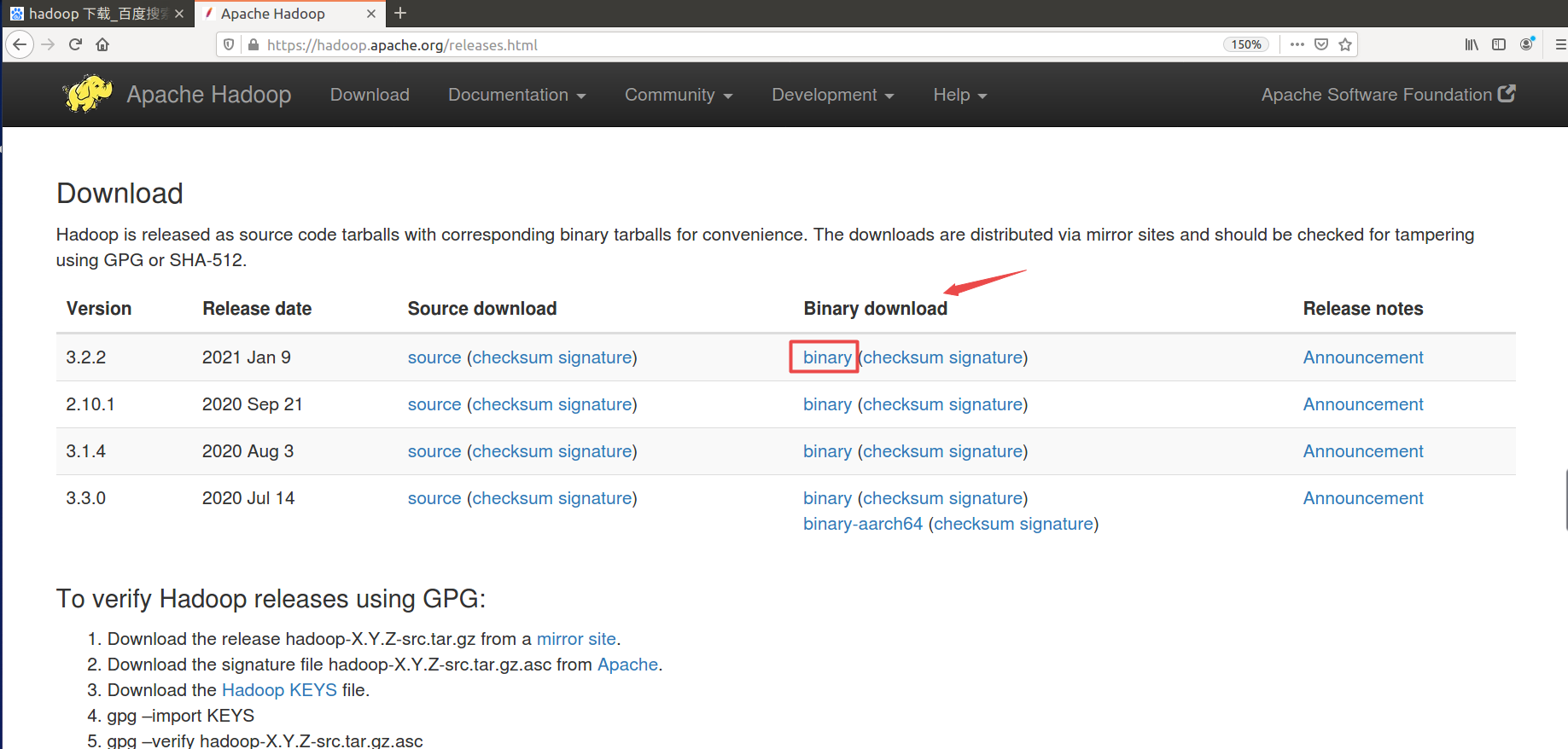
根据推荐下载源下载
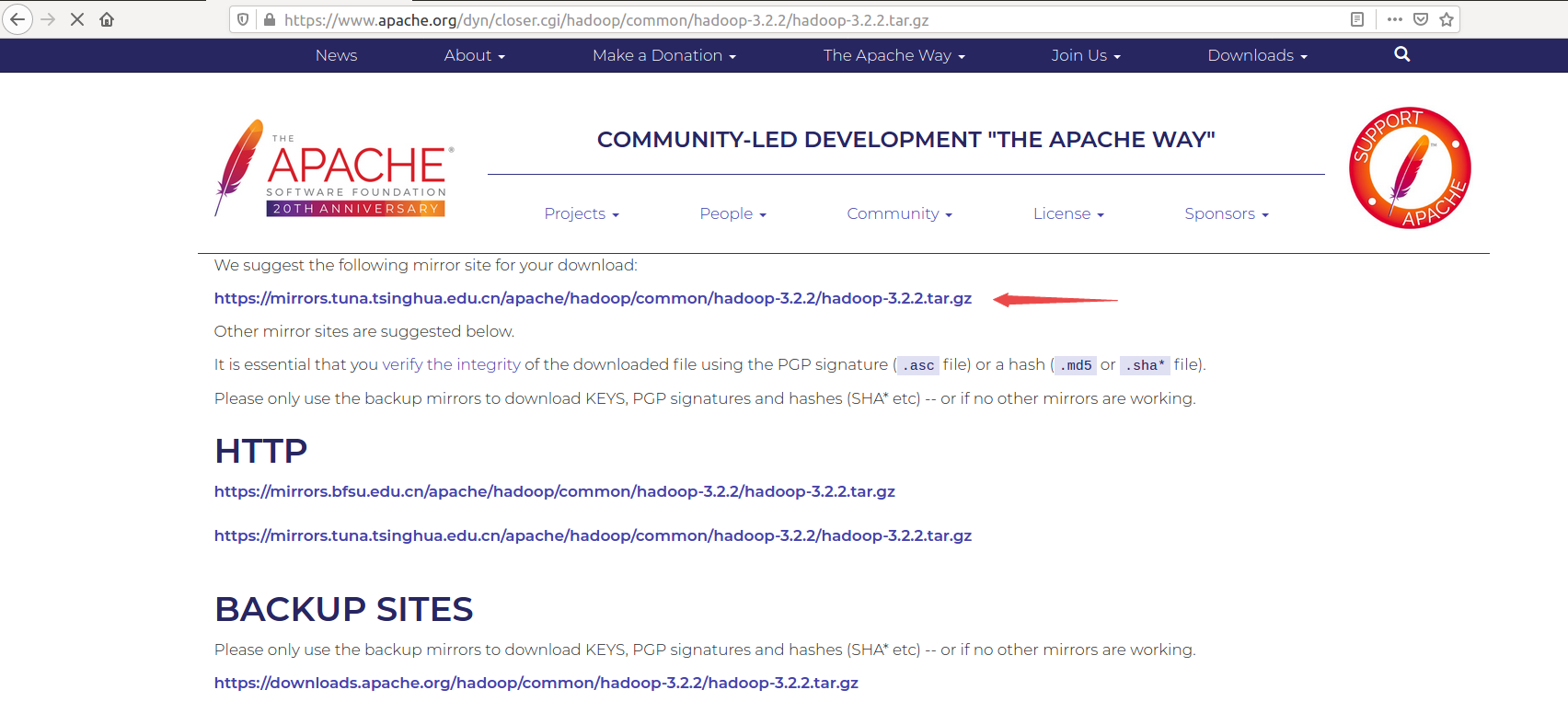
百度网盘分享:
Jdk-8u171-linux-x64:
链接:https://pan.baidu.com/s/1_lji-tSNTeo_bXTP49HddQ 提取码:45bw
Hadoop-3.2.2:
链接:https://pan.baidu.com/s/1WlLfa13YeMGYr0ZSeXtkgQ 提取码:uxq3
这里使用hadoop3.2.2版本和jdk1.8版本
2. 更新软件包最新列表
hadoop@zq:~$ sudo apt-get update
如果是新增加的hadoop用户可能没有sudo权限,报错:hadoop is not in the sudoers file. This incident will be reported.
hadoop@zq:~$ exit # 返回管理员账号
logout
zou123@zq:~$ sudo -s # 切换超级管理员
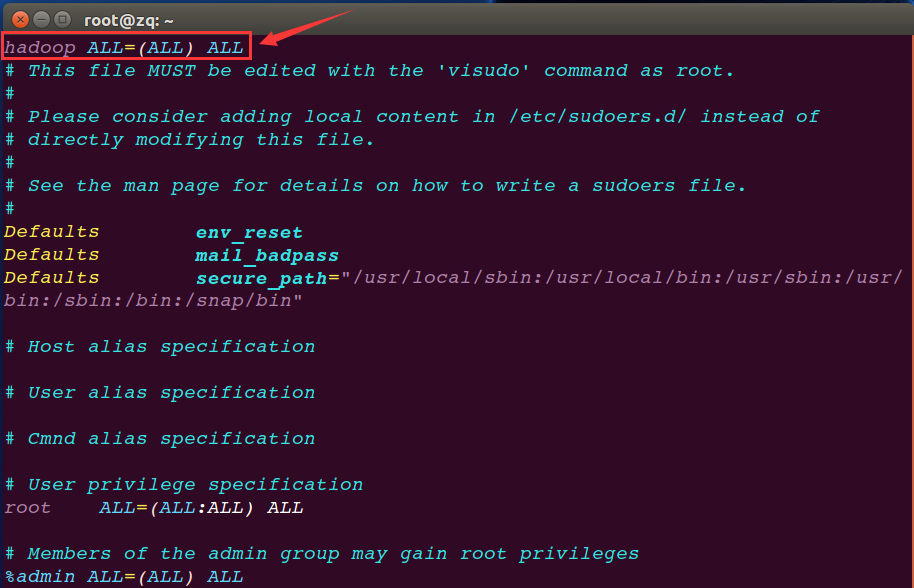
root@zq:~# vim /etc/sudoers # 用Vim编辑 sudoers文件
新增一条语句,hadoop ALL=(ALL) ALL
:wq! 这是只读文件,需要强制保存
3. 安装SSH
hadoop@zq:~$ sudo apt-get install openssh-server
用本机命令登录
hadoop@zq:~$ ssh localhost
执行该命令后会输入“yes”,然后按提示输入密码,就登录到本机了

exit退出SSH,然后ssh-keygen生成密钥,并将密钥加入到授权中
# 若进入目录失败,则重新安装SSH
hadoop@zq:~/.ssh$ ls
known_hosts
# 三个密码都省略,直接回车
hadoop@zq:~/.ssh$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
# 将id_rsa.pub的内容追加到authoried_keys中
hadoop@zq:~/.ssh$ cat id_rsa.pub >> authorized_keys
# 再次登录本地,无需输入密码
hadoop@zq:~/.ssh$ ssh localhost
4. 安装Java并配置环境
# 执行如下命令创建“/usr/lib/jvm”目录用来存放JDK文件
hadoop@zq:~/.ssh$ cd /usr/lib
hadoop@zq:/usr/lib$ sudo mkdir jvm
# 将已下载的jdk进行解压缩
hadoop@zq:~/Downloads$ sudo tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/lib/jvm
在Hadoop用户目录下配置Java运行环境
# 使用Vim打开.bashrc文件,保存
hadoop@zq:~$ vim ~/.bashrc
# 在文件的开头位置,添加如下几行内容,这里jdk目录名为 jdk1.8.0_171
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_171
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# 继续执行如下命令让.bashrc文件的配置立即生效
hadoop@zq:~$ source ~/.bashrc
# 查看Java版本,验证是否安装成功
hadoop@zq:~$ java -version

5. 安装Hadoop
# 解压Hadoop压缩文件到usr/local
hadoop@zq:~/Downloads$ sudo tar -zxvf hadoop-3.2.2.tar.gz -C /usr/local
# 给hadoop-3.2.2文件改名为hadoop
hadoop@zq:/usr/local$ sudo mv hadoop-3.2.2 hadoop
# 修改文件权限
hadoop@zq:/usr/local$ sudo chown -R hadoop ./hadoop
hadoop@zq:/usr/local$ cd hadoop
# 查看hadoop版本,验证是否安装成功
hadoop@zq:/usr/local/hadoop$ bin/hadoop version

6. 运行Hadoop样例
# Hadoop附带了丰富的例子,运行如下命令可以查看所有例子:
hadoop@zq:/usr/local/hadoop$ cd /usr/local/hadoop
hadoop@zq:/usr/local/hadoop$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar
# 运行grep例子
hadoop@zq:/usr/local/hadoop$ cd /usr/local/hadoop
# 创建input文件夹
hadoop@zq:/usr/local/hadoop$ mkdir input
# 拷贝hadoop目录下所有.xml文件到input文件夹
hadoop@zq:/usr/local/hadoop$ cp ./etc/hadoop/*.xml ./input
hadoop@zq:/usr/local/hadoop$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-
examples-*.jar grep ./input ./output 'dfs[a-z.]+'
# 查看结果
hadoop@zq:/usr/local/hadoop$ cat ./output/*

Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行,伪分布式、分布式将在后续补充
