Urllib获取数据
-
制定 URL,获取网页数据,以百度和豆瓣为例
-
from urllib import request 或 import urllib.request
# -*- coding = utf-8 -*-
import urllib.request as req
# 获取百度请求
def get():
url = "http://www.baidu.com"
# 获取一个get请求
response = req.urlopen(url)
# decode('utf-8')使用utf-8解码
print(response.read().decode('utf-8'))
# 获取一个post请求,使用辅助网址测试
def post_test():
data = bytes()
url = "http://httpbin.org/post"
response = req.urlopen(url, data=data)
print(response.read().decode('utf-8'))
# 获取一个get请求
def get_test():
# 使用try捕捉异常
try:
url = "http://httpbin.org/get"
# timeout=x 设置超时,避免长时间耗在这里
response = req.urlopen(url, timeout=10)
print(response.read().decode('utf-8'))
except Exception as e:
print("Error")
def get_baidu():
url = "http://www.baidu.com"
# timeout=x 设置超时,避免长时间耗在这里
response = req.urlopen(url, timeout=10)
# 获取响应状态码
print(response.status)
# 获取响应头中指定键值的内容
print(response.getheader('Date'))
# 获取响应头的全部内容
print(response.getheaders())
# 使用爬虫访问豆瓣,返回报错418,拒绝爬虫
def get_douban():
url = "https://movie.douban.com/top250"
# timeout=x 设置超时,避免长时间耗在这里
response = req.urlopen(url, timeout=10)
print(response.read().decode('utf-8'))
# 伪装访问,以豆瓣举例
def get_douban_disguise():
url = "https://movie.douban.com/top250"
# 自定义给服务器的报头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0"
}
# headers = x 设置向服务器发送的报头,这个res是我们封装的请求对象,不是响应对象
res = req.Request(url, headers=headers)
# 获取响应对象,跟未伪装不同的是,伪装过后,没有被豆瓣拒绝访问
response = req.urlopen(res)
print(response.read().decode('utf-8'))
# 定义分隔线长度
def split(num):
for i in range(1, num):
print("--------------", end='')
print("\n")
# 调用测试程序
def main():
split(10)
get_douban_disguise()
split(10)
# 主程序入口
if __name__ == '__main__':
main()
通过浏览器正常访问豆瓣top250,右键点击开发者模式(F12),获取 User-Agent 的内容
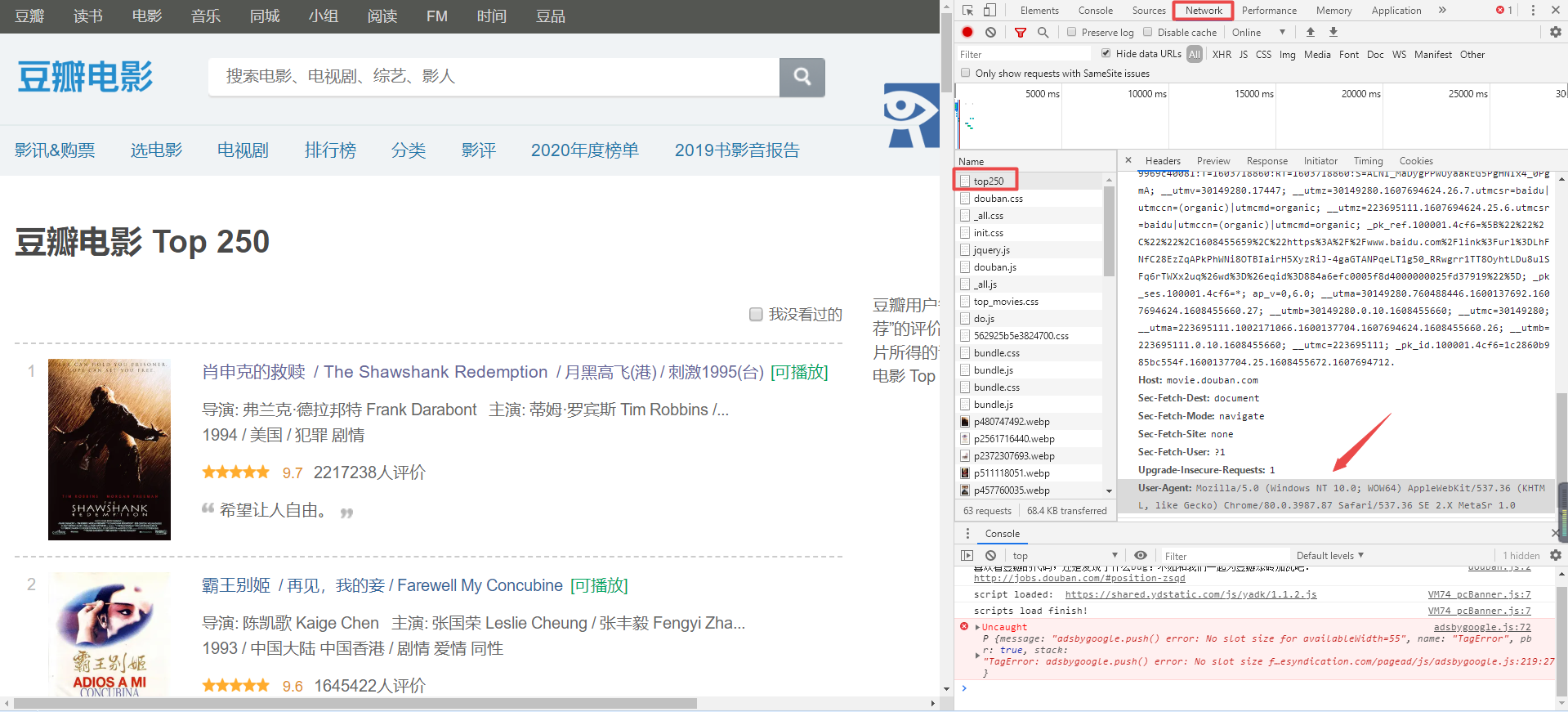
Urllib.request 的作用是获取html页面信息,这里以豆瓣top250的十个页面为例
- 根据url规律,循环生成url并执行获取操作
- 设置传给服务器的header头部信息,伪装自己是正规浏览器访问
- 获取response响应返回的html,使用utf-8编码解析
- 将html加入datalist,循环结束即获取了top250的十个html页面内容
# 获取html信息
def ask_url(url):
# 设置传给服务器的header头部信息,伪装自己是正规浏览器访问
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0"
}
# 用于保存获取的html文件
html = ""
# 最好用 try-except 捕捉异常
try:
# 封装一个Request对象,将自定义的头部信息加入进去
res = req.Request(url, headers=headers)
# 向指定的url获取响应信息,设置超时,防止长时间耗在一个页面
response = req.urlopen(res, timeout=10)
# 读取html信息,使用decode('utf-8')解码
html = response.read().decode('utf-8')
# 如果出错,就捕捉报错信息并打印出,这里使用Exception 泛泛的意思一下
except Exception as error:
# 出现异常时候,打印报错信息
print("Ask_url is Error : " + error)
# 将获得的html页面信息返回
return html
# -*- coding = utf-8 -*-
# 从 urllib 包中导入 request 子包,并给它取别名为 req
from urllib import request as req
# 循环所有的html页面信息
def get_data(base_url):
# 获得多有页面有价值的信息,然后集中存放与datalist列表中
datalist = []
# 循环遍历,修改?start=起始排行序号,获取不同分页的豆瓣top信息,url分页格式去豆瓣换页内容试试
# 例如第一页第 top 0-24,第二页是top 25-49条 ?start=25 这个参数,会让服务器响应第二页的25条信息
for i in range(0, 250, 25):
# 使用基础地址 'https://movie.douban.com/top250?start=' + 偏移地址如 '25'
url = base_url + str(i)
# 获取html存放与html变量中
html = ask_url(url)
# 可以看看获取的html信息
# print(html)
# 接下来是逐一解析数据
return datalist
# 获取html信息
def ask_url(url):
# 设置传给服务器的header头部信息,伪装自己是正规浏览器访问
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0"
}
# 用于保存获取的html文件
html = ""
# 最好用 try-except 捕捉异常
try:
# 封装一个Request对象,将自定义的头部信息加入进去
res = req.Request(url, headers=headers)
# 向指定的url获取响应信息,设置超时,防止长时间耗在一个页面
response = req.urlopen(res, timeout=10)
# 读取html信息,使用decode('utf-8')解码
html = response.read().decode('utf-8')
# 如果出错,就捕捉报错信息并打印出,这里使用Exception 泛泛的意思一下
except Exception as error:
# 出现异常时候,打印报错信息
print("Ask_url is Error : " + error)
# 将获得的html页面信息返回
return html
# 以下split、main两个函数和 if __name__ 程序主入口是我个人编程习惯,与上述内容无本质关联
# 定义分隔线长度
def split(num):
for i in range(1, num):
print("------------", end='')
print()
# 调用测试程序
def main():
split(10)
get_data("https://movie.douban.com/top250?start=")
split(10)
# 主程序入口
if __name__ == '__main__':
main()
