

linux 正则表达式
正则表达式
标签(空格分隔):Linux实战教学笔记
---更多资料点我查看
第1章 什么是正则表达式
- 正则表达式就是为了处理大量的文本|字符串而定义的一套规则和方法
- 通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串。Linux正则表达式一般以行为单位处理。
简单说
- 为处理大量文本|字符串而定义的一套规则和方法
- 以行为单位出来,一次处理一行
正则表达式是一种描述一组字符串的模式,类似数字表达式,通过各种操作符组成更小的表达式
第2章 为何使用正则表达式
linux运维工作,大量过滤日志工作,化繁为简。
简单,高效。
正则表达式高级工具;三剑客都支持
第3章 容易混淆的两个注意事项
- 正则表达式应用非常广泛,存在于各种语言中,php perl grep sed awk 支持。ls * 通配符
- 但现在学的是Linux中的正则表达式,最常应用正则表达式的命令是grep(egrep),sed,awk。
- 正则表达式和通配符有本质区别
正则表达式用来找:【文件】内容,文本,字符串。一般只有三剑客支持
通配符用来找:文件名,普通命令都支持
第4章 正则表达式使用注意事项
-
linux正则表达式以行为单位处理字符串
-
便于区别过滤出来的字符串,一定配合grep/egrep命令学习。
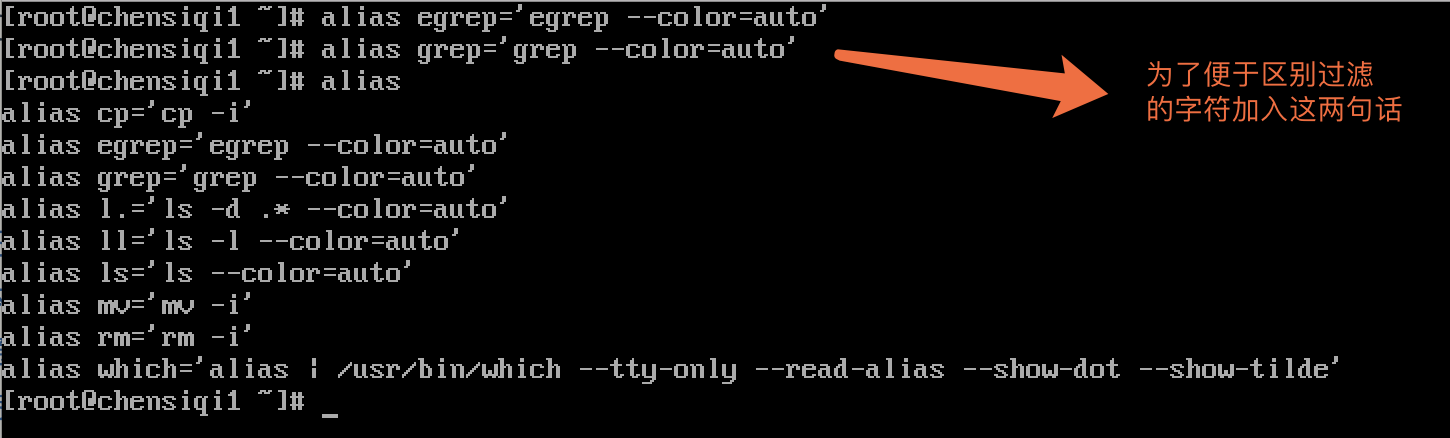
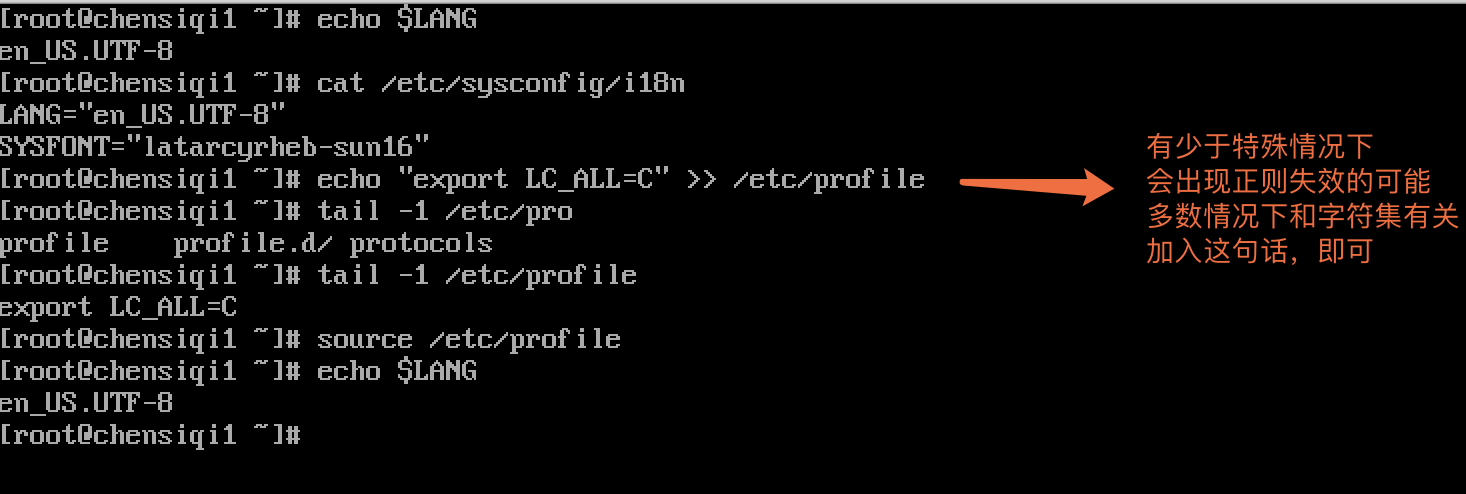
- 注意字符集,exportLC_All=C:无论何时,做何事都要注意字符集
第5章 正则表达式的分类
POSIX规范将正则表达式的分为了两种
- 基本正则表达式(BRE,basic regular expression)
- 高级功能:扩展正则表达式(ERE,extended regular expression)
5.1 BRE和ERE的区别仅仅是元字符的不同:
- BRE(基础正则表达式)只承认的元字符有^$.[]*其他字符识别为普通字符:\(\)
- ERE(扩展正则表达式)则添加了(){}?+|等
- 只有在用反斜杠“”进行转义的情况下,字符(){}才会在BRE被当作元字符处理,而ERE中,任何元符号前面加上反斜杠反而会使其被当作普通字符来处理。
第6章 如何区分通配符和正则表达式
- 不需要思考的判断方法:在三剑客awk,sed,grep,egrep都是正则,其他都是通配符
- 区别通配符和正则表达式最简单的方法:
(1)文件目录名===>通配符
(2)文件内容(字符串,文本【文件】内容)===>正则表达式
- 通配符和正则表达式都有“*”,“?”,“【】”,但是通配符的这些符号都能自身代表任意字符,而正则表达式的这些符号只能代表这些符号前面的字符
第7章 基本正则表达式
7.1 基础正则表达式
| 字符 | 描述 |
|---|---|
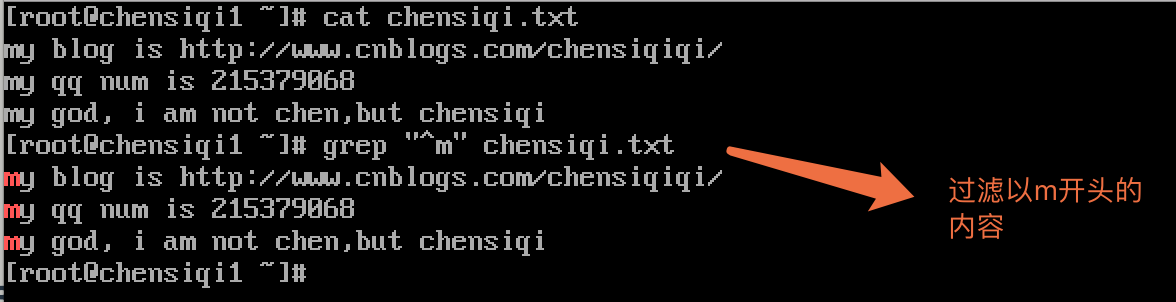
| ^ | ^word搜索以word开头的内容 |
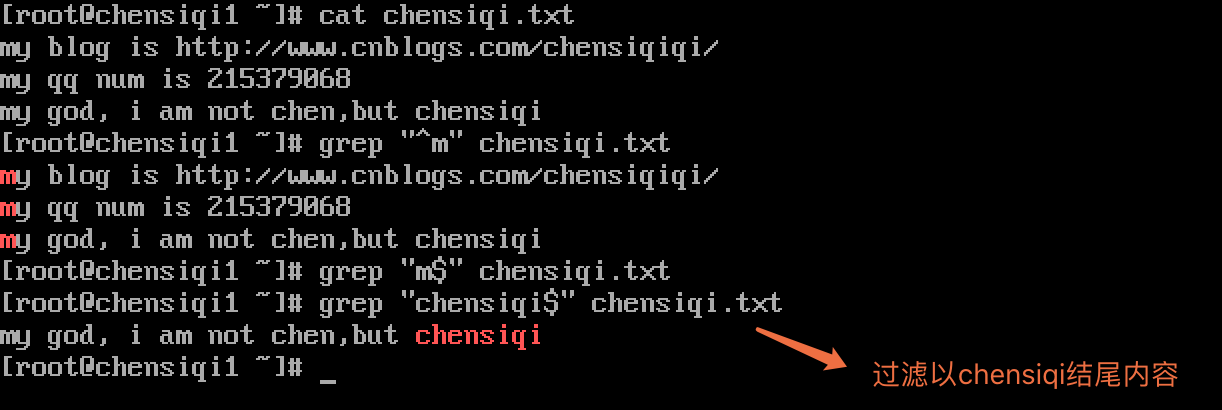
| $ | word$搜索以word结尾的内容 |
|---|
| ^$ | 表示空行,不是空格 |
|---|

| . | 代表且只能代表任意一个字符(不匹配空行) |
|---|

| \ | 转义字符,让有特殊含义的字符脱掉马甲,现出原形,如\.只表示小数点 |
|---|
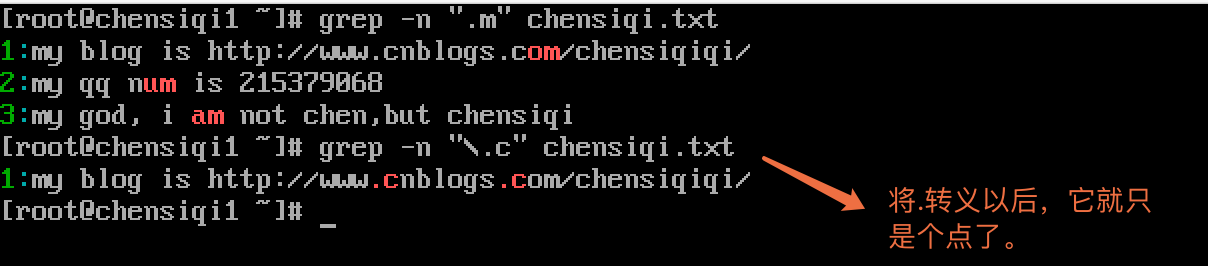
| * | 重复之前的字符或文本0个或多个,之前的文本或字符连续0次或多次 |
|---|

| .* | 任意多个字符 |
|---|

| ^.* | 以任意多个字符串开头,.*尽可能多,有多少算多少,贪婪性 |
|---|
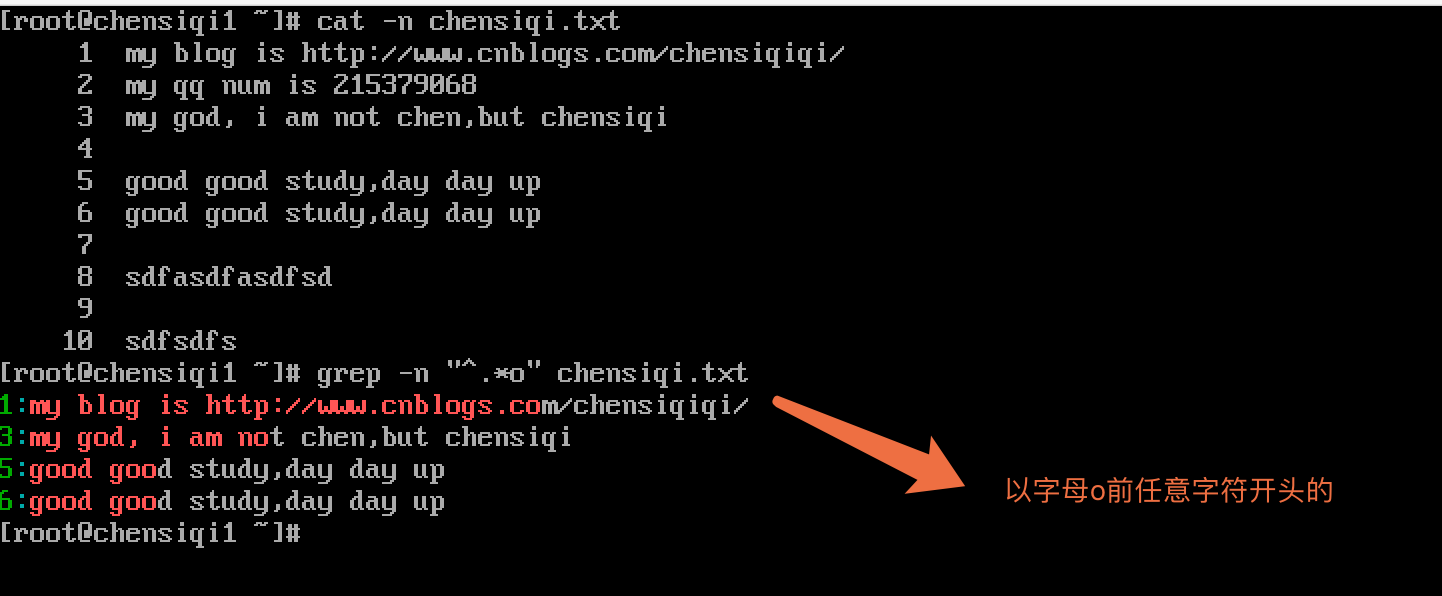
| 括号表达式 | |
|---|---|
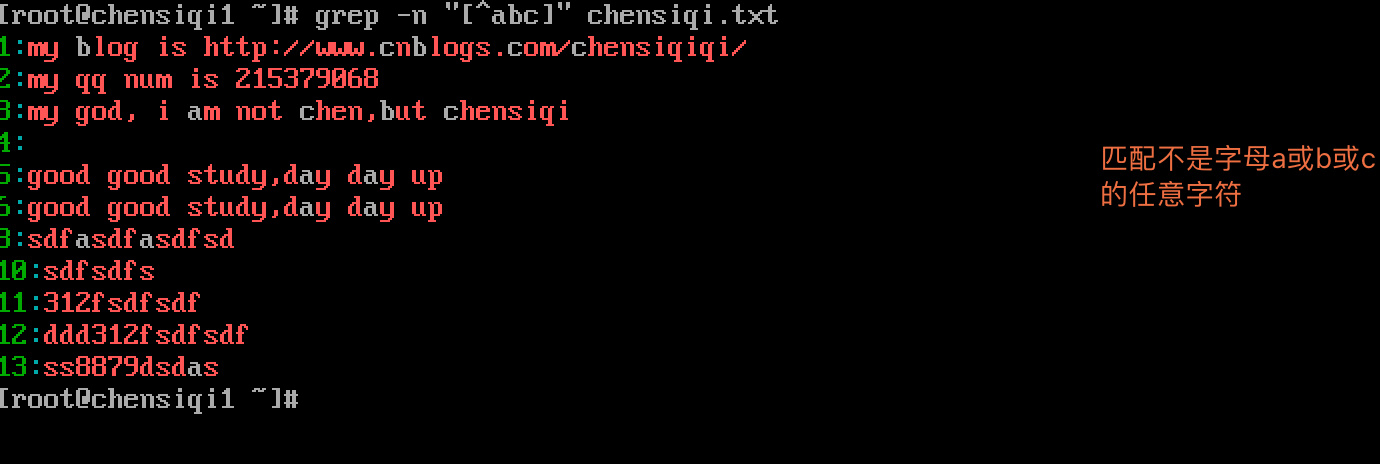
| [abc][0-9][\.,/] | 匹配字符集合内的任意一个字符a或b或c:[a-z]匹配所有小写字母;表示一个整体,内藏无限可能;[abc]找a或b或c可以写成[a-c] |

| [^abc] | 匹配不包含^后的任意字符a或b或c,是对[abc]的取反,且与^含义不同 |
|---|
| a\{n,m\} | 重复前面a字符n到m次(如果用egrep或sed -r可去掉斜线) |
|---|
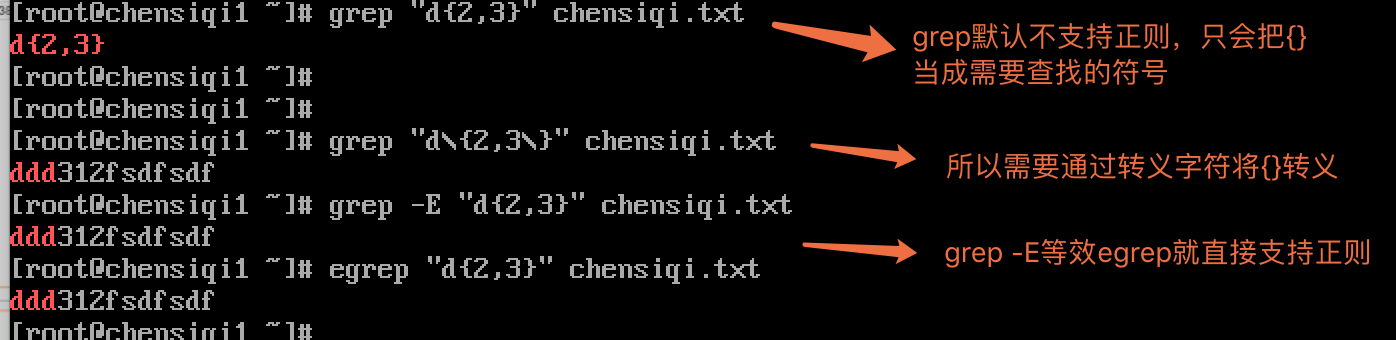
| a\{n,\} | 重复前面a字符至少n次,如果用egrep或sed -r可去掉斜线 |
|---|---|
| a\{n\} | 重复前面a字符n次,如果用egrep或sed -r可去掉斜线 |
| --- | --- |
第8章 扩展正则表达式ERE
| 特殊字符 | 含义与例子 |
|---|---|
| + | 重复前一个字符一次或一次以上,前一个字符连续一个或多个,把连续的文本/字符取出 |

| ? | 重复前面一个字符0次或1次(.是有且只有1个) |
|---|
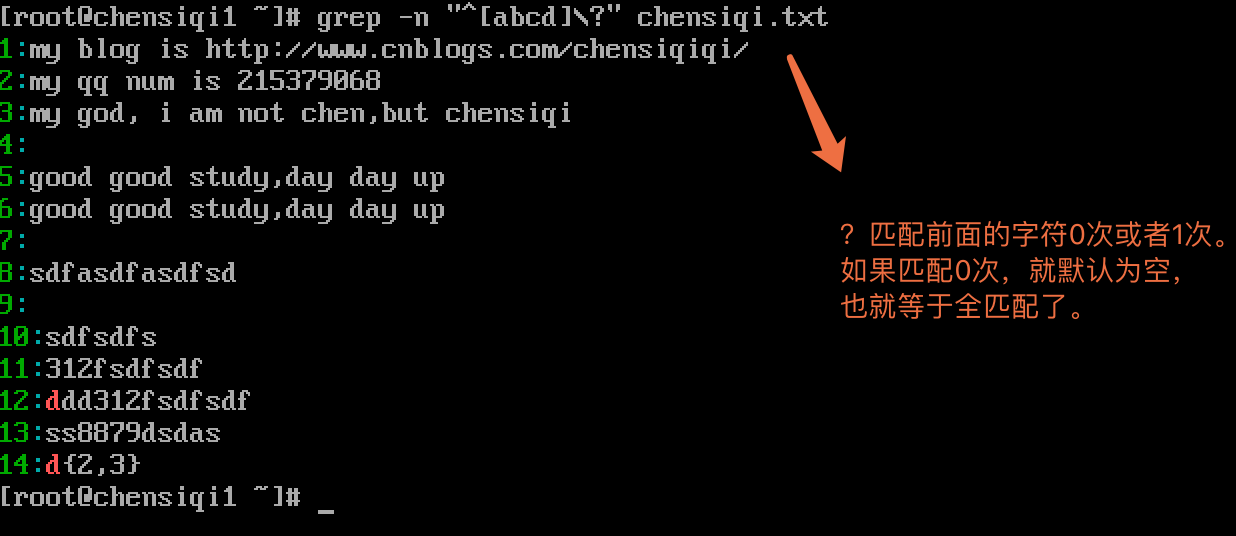
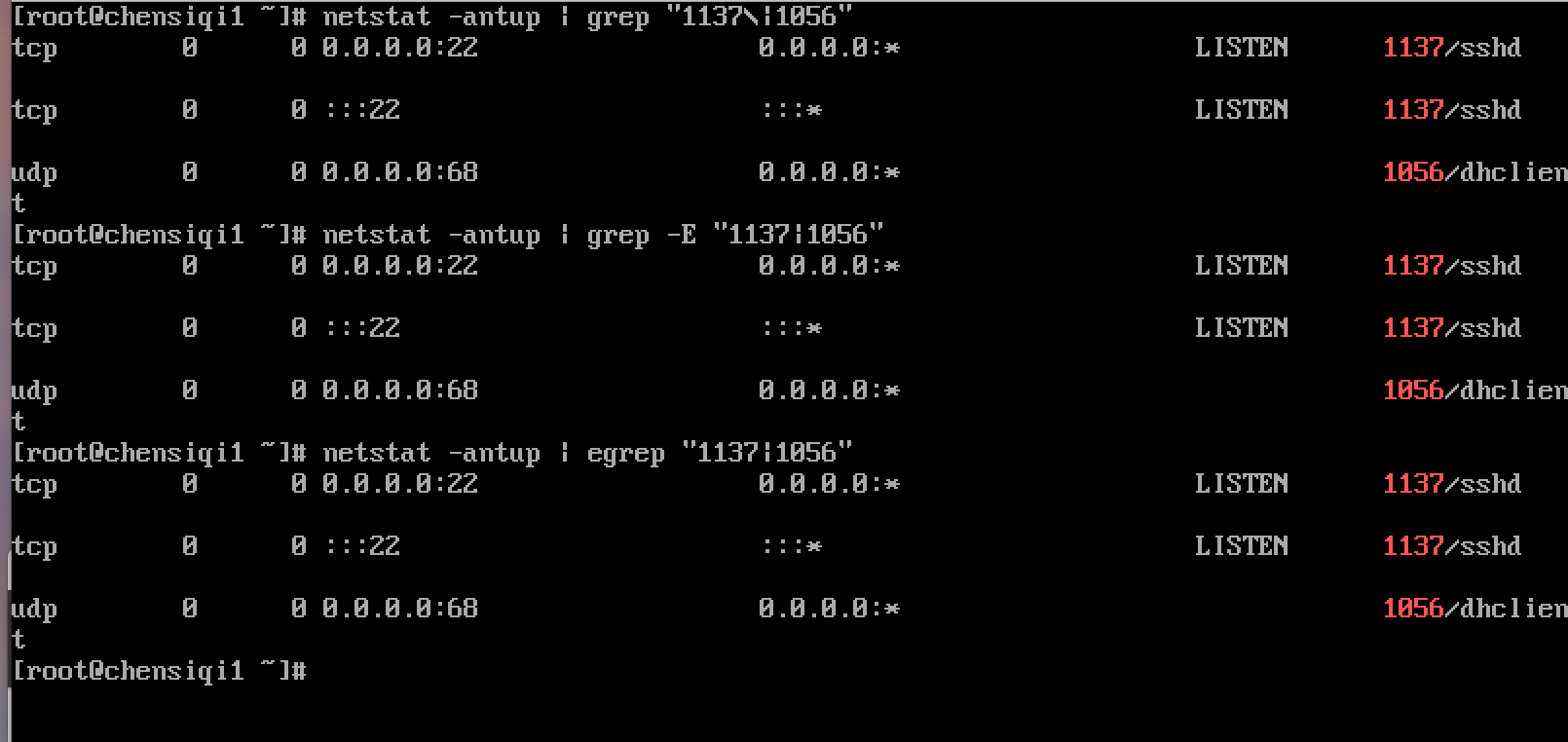
| 管道符 | 表示或者同时过滤多个字符 |
|---|
| () | 分组过滤被括起来的东西表示一个整体(一个字符),后向引用 |
|---|
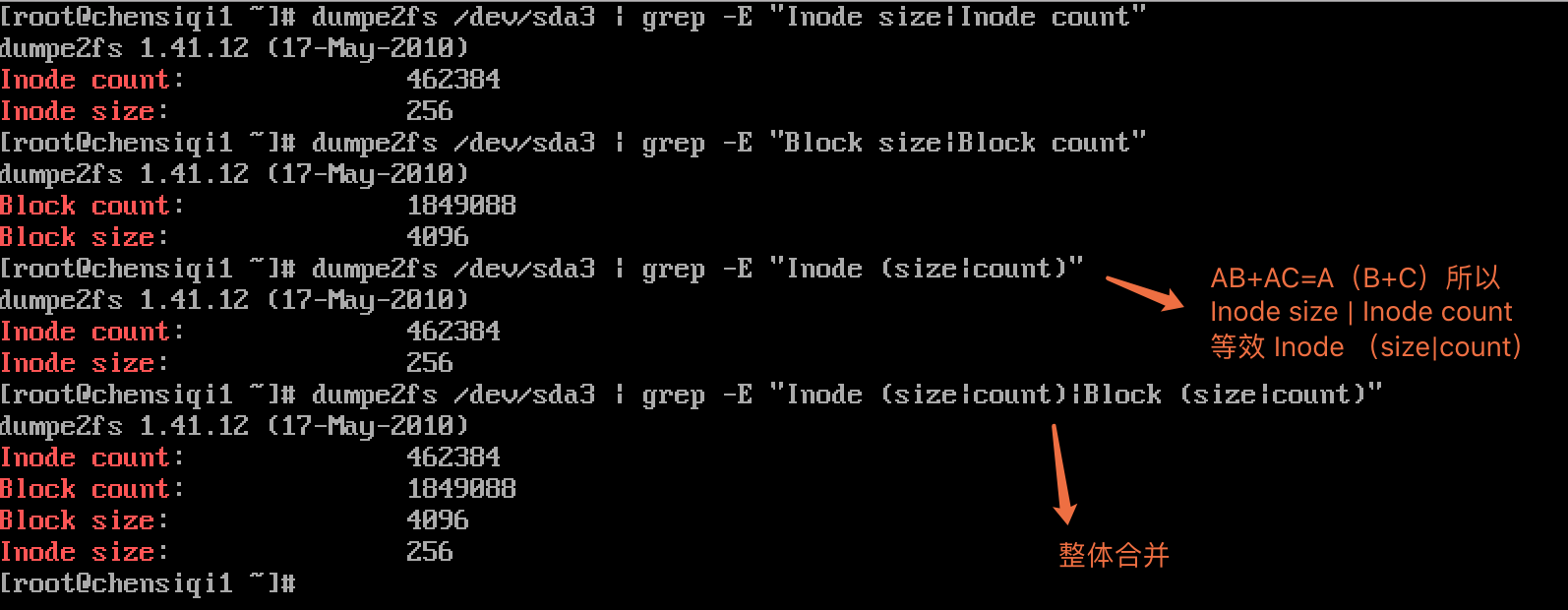
第9章 正则小结
-
基础正则:BRE
|^|$|.||.|[abc]|[^abc]|
|---|---| -
扩展正则:ERE
|+|||?|()|{}|a{n,m}|a{n,}|a{n}|
|---|---| -
转义字符\:将字符的意思改变(不支持正则符号的,转变字符含义为正则,支持正则的转变为普通字符含义)
注意:
- grep默认不支持正则,因此正则表达式的符号对于grep来说就等同于普通字符含义,因此,想让grep直接处理正则符号必须通过转义字符\{\}来处理。
- grep -E 强制让grep直接认识正则符号,不需要再进行转义
- egrep 等效grep -E 天生就能认识正则符号
- 我们平时备份可以通过cp 文件名{,.bak}的形式进行,避免再打一次文件名
sed -r :让sed支持正则
第10章 基本正则和扩展正则区别
| 基础正则BRE | 扩展正则ERE |
|---|---|
| \? | ? |
| \+ | + |
| \{\} | {} |
| \( \ ) | () |
| \ |
所谓基础正则实际上就是得需要转义字符配合表达的正则,而扩展正则就是让命令扩展它的权限让他直接就认识正则表达符号(egrep,sed -r,awk直接支持)
第11章 补充说明
11.1 一些预定义的:
| 正则表达式 | 描述 | 示例 |
|---|---|---|
| [:alnum:] | [a-zA-Z0-9]匹配任意一个字母或数字字符 | [[:alnum:]]+ |
| [:alpha:] | 匹配任意一个字母字符(包括大小写字母) | [[:alpha:]]{4} |
| [:blank:] | 空格与制表符(横向纵向) | [[:blank:]]* |
| [:digit:] | 匹配任意一个数字字符 | [[:digit:]]? |
| [:lower:] | 匹配小写字母 | [[:lower:]]{5,} |
| [:upper:] | 匹配大写字母 | ([[:upper:]]+)? |
| [:punct:] | 匹配标点符号 | [[:punct:]] |
| [:space:] | 匹配一个包括换行符,回车等在内的所有空白符 | [[:space:]]+ |
| [:graph:] | 匹配任何一个可以看得见的且可以打印的字符 | [[:graph:]] |
| [:xdigit:] | 任何一个十六进制数 | [[:xdigit:]]+ |
| [:cntrl:] | 任何一个控制字符(ASCII字符集中的前32个字符) | [[:cntrl:]] |
| [:print:] | 任何一个可以打印的字符 | [[:print:]] |
11.2 元字符
元字符是一种Perl风格的正则表达式,只有一部分文本处理工具支持它,并不是所有的文本处理工具都支持
| 正则表达式 | 描述 | 示例 |
|---|---|---|
| \b | 单词边界 | \bcool\b匹配cool,不匹配coolant |
| \B | 非单词边界 | cool\B匹配coolant不匹配cool |
| \d | 单个数字字符 | b\db匹配b2b,不匹配bcb |
| \D | 单个非数字字符 | b\Db匹配bcb不匹配b2b |
| \w | 单个单词字符(字母,数字与_) | \w匹配1或a,不匹配& |
| \W | 单个非单词字符 | \W匹配&,不匹配1或a |
| \n | 换行符 | \n匹配一个新行 |
| \s | 单个空白字符 | x\sx匹配xx,不匹配xx |
| \S | 单个非空白字符 | x\S\x匹配xkx,不匹配xx |
| \r | 回车 | \r匹配回车 |
| \t | 横向制表符 | \t匹配一个横向制表符 |
| \v | 垂直制表符 | \v匹配一个垂直制表符 |
| \f | 换页符 | \f匹配一个换页符 |
第12章 正则表达式总结
- egrep/grep 了解一下正则,简单看看效果,结果
- egrep/grep -o 参数看正则到底匹配了什么
- 多练就好,配合grep,egrep,sed -r,awk更为强大

