利用SQL Profiler处理开销较大的查询
当SQL Server的性能变差时,最可能发生的是以下两件事:
- 首先,某些查询产生了系统资源上很大的压力。这些查询影响整个系统的性能,因为服务器无法足够快速地服务其他SQL查询。
- 另外,开销较大的查询阻塞了其他请求相同数据库资源的查询,进一步降低了这些查询的性能。优化开销较大的查询不仅改进它们本身的性能,而且减少数据库阻塞和SQL Server资源压力从而提高了其他查询的性能。
识别开销较大的查询
SQL Server的目标是在最短时间内将结果集返回给用户。为此,SQL Server查询优化器生成一个成本效益高的查询执行计划。查询优化器计算许多因素的权重,包括执行查询所需要的CPU、内存以及磁盘I/O的使用情况-这些均来自于由索引维护或过程中生成的统计。通常开销最低的计划有最少的I/O,因为I/O操作代价昂贵。
逻辑读提供指出了查询产生的内存压力。它还提供了磁盘压力指标,因为内存页面必须在操作查询中被备份,在第一次数据访问期间写入,并且在内存瓶颈时被移到磁盘上。查询的逻辑读数量越大,磁盘压力的可能性就越大。过多的逻辑页面也增加了CPU用于管理这些页面的负载。
导致大量逻辑读的查询通常在相应的大数据集上得到锁。即使读也需要在所有数据上的共享锁。这些查询阻塞了其他请求修改这些数据的查询,但是不阻塞读取数据的查询。因为这些查询固有的开销并且需要长时间执行,他们持续地阻塞其他查询。被阻塞的查询进一步阻塞查询,引入了数据中的阻塞链。
识别开销较大的查询并优化它们有如下意义:
- 增进开销较大的查询本身的性能;
- 降低系统资源上的总体压力;
- 较少数据库阻塞;
其中开销较大的查询可以被分为如下两类:
- 单词执行:查询的一次单独执行开销较大;
- 多次执行:查询本身开销并不大,但是该查询的重复执行导致系统资源上的压力;
1、单次执行开销较大的查询
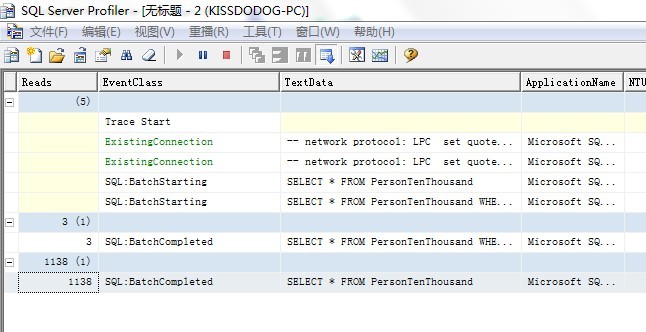
可以分析SQL Profiler跟踪输出文件来识别开销较大的查询。比如,如果对识别执行大量的逻辑读的查询感兴趣,应该在跟踪输出的Reads数据列上排序。
- 捕捉表示典型工作负载的Profiler跟踪;
- 将跟踪输出保存到一个跟踪文件;
- 打开跟踪文件进行分析;
- 通过事件选择选项卡,单击组织列按钮,在Reads列上分组跟踪输出。
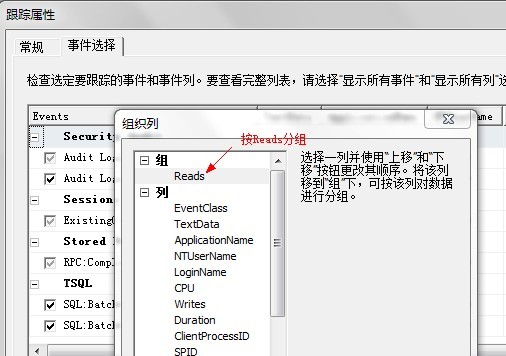
跟踪输出如下:
在某些情况下,可能从系统监视器输出中识别CPU上的大压力。CPU上的压力可能是因为大量CPU密集型操作,如存储过程重编译、总计函数、数据排序、哈希连接等。在这种情况下,应该在CPU列上排序Profiler跟踪输出以识别使用大量处理器周期的查询。
2、多次执行开销较大的查询
有时候一个查询可能本身开销并不大,但是同一查询多次执行的累积效应可能造成系统资源的压力。在Reads列上排序对识别这种类型的查询没有帮助。如果希望知道查询的多次执行进行的总读取数,不幸的是Profiler在这里不能直接提供帮助,但是仍然可以用以下方法得到这一信息。
- 在Profiler中跟踪输出的以下列上分组:EventClass、TextData和Reads。对于相同EventClass和TextData的分组,手工计算所有对应的Reads的总和。
- 在Profiler中选择文件=》另存为=》跟踪表将输出到一个跟踪表。也可以使用内建函数fn_trace_gettable和Profiler的跟踪文件输出导入到一个跟踪表。
- 访问sys.dm_exec_query_stats DMV从生产服务器上检索信息。这假设打算处理一个即时的问题并且不关注历史问题。
在将跟踪输入保存到文件以后,先将跟踪数据导入到一张表:
SELECT * INTO TraceTable
FROM ::fn_trace_gettable('D:\123.trc',default)
然后执行以下语句:

SELECT COUNT(*) AS TotalExecutions,EventClass, CAST(TextData AS NVARCHAR(MAX)) TextData, SUM(Duration) AS Duration_Total, SUM(CPU) AS CPU_Total, SUM(Reads) AS Reads_Total, SUM(Writes) AS Writes_Total FROM TraceTable GROUP BY EventClass,CAST(TextData AS NVARCHAR(MAX)) ORDER BY Reads_Total DESC
脚本中的TotalExecutions列指出了查询被执行的次数,Reads_Total列指出了该查询多次执行所进行的读操作的总数。注意NTEXT不支持GROUP BY,因此要转换一下类型。
这个方法识别出来的开销较大的查询比Profiler识别出的单次执行的开销较大查询更好地指出了负载。例如,一个需要50个读操作的查询可能执行1000次。这个查询本身被认为足够经济了,但是执行的读操作总是是5万,这不能被认为是经济的。优化这个查询降低读操作数,即使每次执行减少10次,读操作数也将降低1万次。这比优化一个5千次读操作的查询更有利。
从sys.dm_exec_query_stats视图中得到相同的信息只需要一个查询:
SELECT ss.sum_execution_count ,t.TEXT ,ss.sum_total_elapsed_time ,ss.sum_total_worker_time ,ss.sum_total_logical_reads ,ss.sum_total_logical_writes FROM (SELECT s.plan_handle ,SUM(s.execution_count) sum_execution_count ,SUM(s.total_elapsed_time) sum_total_elapsed_time ,SUM(s.total_worker_time) sum_total_worker_time ,SUM(s.total_logical_reads) sum_total_logical_reads ,SUM(s.total_logical_writes) sum_total_logical_writes FROM sys.dm_exec_query_stats s GROUP BY s.plan_handle )AS ss CROSS APPLY sys.dm_exec_sql_text(ss.plan_handle) t ORDER BY sum_total_logical_reads DESC
这比所有收集跟踪数据所需要的工作要容易得多,那么为什么还要使用跟踪数据?使用跟踪的主要原因是精确性。sys.dm_exec_query_stats视图是给定计划已经存在于内存中时的流动总计,时间点并不精确。另一方面,跟踪是运行的任何时间段的历史记录。甚至可以在数据库中加入跟踪,并且拥有一系列可以比依靠给定的瞬间更精确地生成总计的数据。但是对定位性能问题的理解关注是查询运行缓慢的时点,这是sys.dm_exec_query_stats不可替代的场合。
3、识别运行缓慢的查询
如果运行缓慢的查询的响应时间变得不可接受,那么应该分析性能下降的原因。但是不是所有运行缓慢的查询都是由于资源问题造成的,其他需要关心的因素如阻塞也可能导致缓慢的查询。
为了发现运行缓慢的查询,在Duration列上分组跟踪输出。
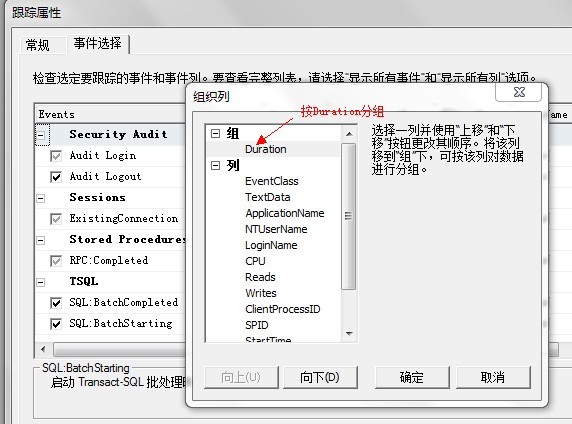
跟踪输出如下:
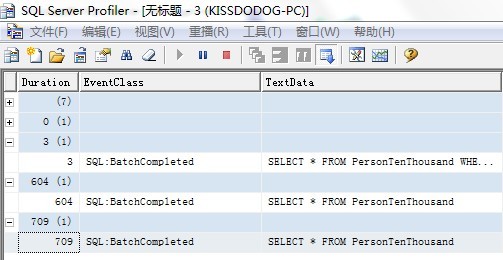
对于运行缓慢的系统,应该注意优化过程前后运行缓慢的持续查询时间。应用优化技术之后,应该计算在系统上的总体性能。优化步骤可能负面地影响其他查询,使其变慢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号