SQL Server 2005 分页研究和优化(1)
SQL Server 2005 分页比 2000的确提高不少,可以使用 row_number()函数来处理。
先看看这个分页函数的效率。新建一个表[[zping.com]]
 CREATE TABLE [dbo].[[[zping.com]]]]]( [id] [varchar](32) NOT NULL, [wwid] [varchar](32) NULL, [laid] [varchar](32) NULL, [cupid] [varchar](32) NULL, [isreceived] [int] NULL, [issited] [int] NULL, [ised] [int] NULL, [isfhed] [int] NULL)
CREATE TABLE [dbo].[[[zping.com]]]]]( [id] [varchar](32) NOT NULL, [wwid] [varchar](32) NULL, [laid] [varchar](32) NULL, [cupid] [varchar](32) NULL, [isreceived] [int] NULL, [issited] [int] NULL, [ised] [int] NULL, [isfhed] [int] NULL) 导入该表数据有70万,取60-80条间的20条数据,在id建立唯一索引
select * from (select *, row_number() over (order by id) scn from [dbo].[[[zping.com]]]]] ) twhere scn<=80 and scn>60
sql server统计信息:
表 '[[zping.com]]'。扫描计数 1,逻辑读取 83 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里看到其逻辑读才83次,数据效率很高
我们把取100000到100000-20条之间的数据
select * from (select *, row_number() over (order by id) scn from [dbo].[[[zping.com]]]]] ) twhere scn<100000 and scn>100000-20
sql server统计信息:
(19 行受影响) 表 '[[zping.com]]'。扫描计数 1,逻辑读取 100740 次,物理读取 259 次,预读 2026 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里发现取100000到100000-20条之间的数据,花费了逻辑读取 100740 次,是上一个几千倍。同样是取20条数据,差距为何
这么大啊:我们对比一下执行计划:
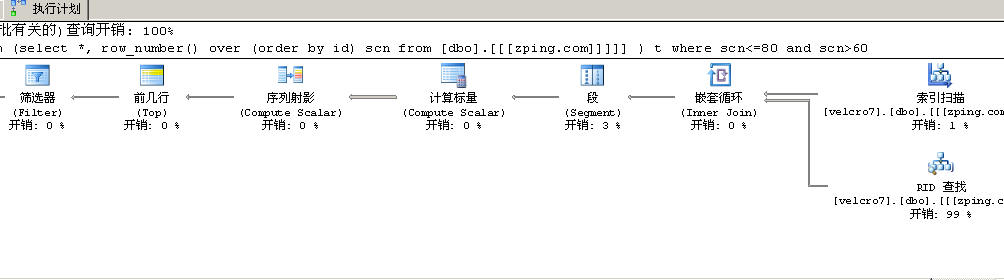
查看一下取60-80行的执行计划:
1,在开始取数据时的索引扫描同样是取的“id索引”的“实际行数”是80行,在通过嵌套循环取出这个80行数据的全部字段。
2,”序列射影“是“[Expr1004] = 标量运算符(row_number)”,说明,在选出来的list中增加虚拟列序号如(1,2,3......)
3,第“筛选器”这个谓词操作时他的运作是“[Expr1004]>(60) AND [Expr1004]<=(80)”,取出20行数据
实际上:这时过程中只去了80行数据,再去取20行数据
看看100000到100000-20条之间的数据执行计划
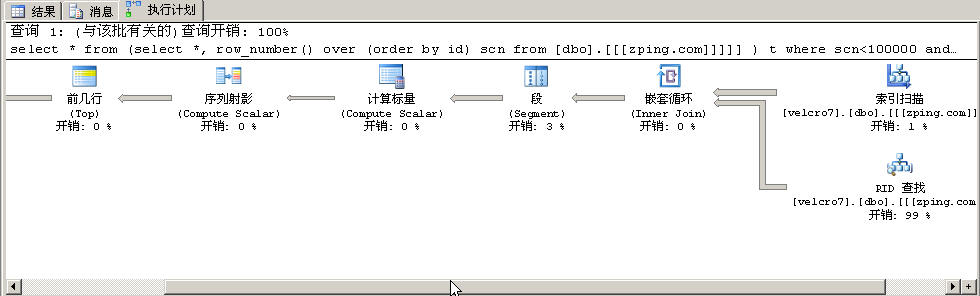
执行计划和上面的一样:
细微差别:
1,在开始取数据“id索引”的“实际行数”是10万行
2,在筛选器中谓词为“[Expr1004]>(99980) AND [Expr1004]<(100000)”
分页技术总结:
1, row_number()函数,只有在数据选择出来以后再加上的虚拟列,选择的时候是不知道编号的。
2, 要取出非索引的数据,数据库要到表里把预先要的数据全部取出来,行越多逻辑读也也越多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号