

hadoop 伪分布式 完全分布式 及HA部署
https://www.jianshu.com/p/6dda4f79379e
https://blog.csdn.net/qq_25542879/article/details/89554068
1、制作Hadoop伪集群镜像
下载jdk
下载hadoop并解压
配置hadoop
需要配置的文件如下:
hadoop-3.2.1/etc/hadoop/hadoop-env.sh hadoop-3.2.1/etc/hadoop/core-site.xml hadoop-3.2.1/etc/hadoop/hdfs-site.xml hadoop-3.2.1/etc/hadoop/mapred-site.xml hadoop-3.2.1/etc/hadoop/yarn-site.xml hadoop-3.2.1/etc/hadoop/workers
配置 hadoop-env.sh 添加jdk环境变量即可
export JAVA_HOME=/usr/local/jdk1.8.0_92
配置core-site.xml
(1)指定 Hadoop 所使用的文件系统以及 namenode 地址,使用 IP 地址或主机名均可
(2)指定 namenode 上本地的 hadoop 临时文件夹
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://0.0.0.0:9000</value>
</property>
<property>
<!-- 执行Hadoop运行时的数据存放目录 -->
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.2.1/data</value>
</property>
</configuration>
配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置 mapred-site.xml,指定 MapReduce 运行框架为 yarn,默认为 local
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置 yarn-site.xml
(1)指定 resourcemanager 的地址,使用主机名
(2)nodemanager 运行的附属服务,要配置成 mapreduce_shuffle,才可以运行 MapReduce 程序默认值
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置 workers 添加从节点。伪分布式模式中,只有一个 localhost 节点(注:Hadoop 3.0 以前的版本是 slaves 文件)
sh-4.2$ cat ../etc/hadoop/workers localhost sh-4.2$
利用之前的centos7-ssh:v1镜像(该博文另一篇文章)制作Hadoop伪集群镜像
FROM centos7-ssh:v1 ADD jdk-8u92-linux-x64.tar.gz /usr/local/ ADD hadoop-3.2.1 /opt/hadoop-3.2.1 ENV JAVA_HOME=/usr/local/jdk1.8.0_92 ENV CLASSPATH=.:/usr/local/jdk1.8.0_92/lib:$CLASSPATH ENV HADOOP_HOME=/opt/hadoop-3.2.1 ENV PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH RUN sudo chmod -R 755 /etc/ssh/
#USER hadoop RUN sudo chown -R hadoop:hadoop /opt/hadoop-3.2.1 RUN mkdir -p /opt/hadoop-3.2.1/{data,datanode} RUN /opt/hadoop-3.2.1/bin/hdfs namenode -format EXPOSE 22 8088 9870
docker build -t hadoop:v1 .
3、测试
启动hadoop
docker run -it -d --name hadoop hadoop:v1 docker exec -it hadoop sh
#进入容器后启动集群
cd /opt/hadoop-3.2.1/sbin && ./start-all.sh
#使用jps查看进程
sh-4.2$ jps
305 DataNode
929 NodeManager
819 ResourceManager
485 SecondaryNameNode
198 NameNode
1302 Jps
sh-4.2$ echo "123" >~/hadoop-test-file #创建个文件 sh-4.2$ sh-4.2$ cd /opt/hadoop-3.2.1/bin/ sh-4.2$ hadoop fs -put ~/hadoop-test-file / #上传文件 2020-04-01 15:38:49,487 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false sh-4.2$ hadoop fs -ls / #查看文件 Found 1 items -rw-r--r-- 1 hadoop supergroup 4 2020-04-01 15:38 /hadoop-test-file sh-4.2$
也可以登录浏览器查看上传结果
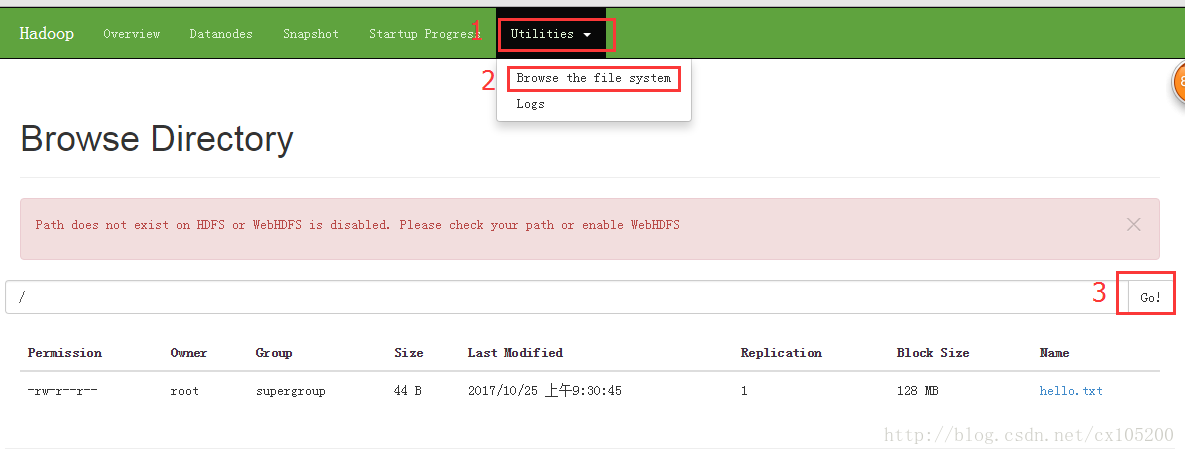
可视化界面:
-
YARN NodeManager:http://192.168.80.80:9870
-
YARN ResourceManager:http://192.168.80.80:8088
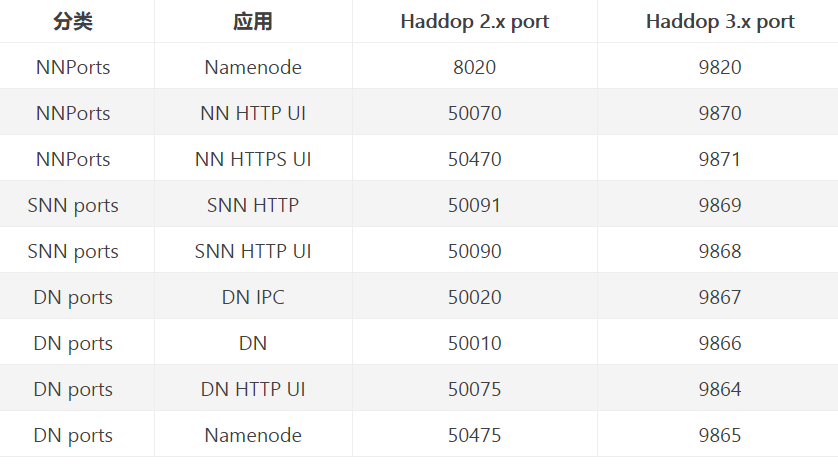
Hadoop 3.x 端口号与 2.x 的比较
hadoop dfsadmin -report #查看集群信息
完全分布式集群
192.168.92.128 master 192.168.92.130 slave-01 192.168.92.131 slave-02
2、三台服务器配置ssh免登陆,本机也要能ssh 免密到本机
start-dfs.sh、stop-dfs.sh 文件开头添加以下参数HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
在 start-yarn.sh、stop-yarn.sh 文件开头添加以下参数:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
hadoop-3.2.1/etc/hadoop/hadoop-env.sh #与伪分布式相同 hadoop-3.2.1/etc/hadoop/core-site.xml hadoop-3.2.1/etc/hadoop/hdfs-site.xml hadoop-3.2.1/etc/hadoop/mapred-site.xml #与伪分布式相同 hadoop-3.2.1/etc/hadoop/yarn-site.xml hadoop-3.2.1/etc/hadoop/workers
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-3.2.1/data</value>
</property>
</configuration>
- fs.defaultFS 配置哪个节点来启动hdfs ,它是HDFS的hadoop访问目录节点nameNode的地址和端口,
使用 fs.default.name 还是 使用 fs.defaultFS ,要首先判断是否开启了 NN 的HA (namenode 的 highavaliable),如果开启了nn ha,那么就用fs.defaultFS,在单一namenode的情况下,就用 fs.default.name , 如果在单一namenode节点的情况使用 fs.defaultFS ,系统将报错。
- hadoop.tmp.dir 配置hadoop存储数据的路径,
- 我们需要手动创建tmp.dir目录
<configuration>
<!--指文件上传到hadoop后有几个副本,一般默认为3个副本已经够用了,设置太多也没什么用。需要在每个DataNode上设置--> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.http-address</name> <value>master:50070</value> </property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-3.2.1/data/dfs/name</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave-02:50090</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-3.2.1/datanode</value>
</property>
</configuration>
dfs.replication 设置文件的备份数量
dfs.namenode.http-address 设置哪台虚拟机作为namenode节点,与core-site.xml 里 fs.defaultFS参数对应,本次实验namdnode是master主机
dfs.namenode.secondary.http-address 设置哪台虚拟机作为冷备份namenode节点,用于辅助namenode
5.3配置yarn-site.xml ,指定slave-01为yarn服务器
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave-01</value>
</property>
</configuration>
yarn.resourcemanager.hostname 配置yarn启动的主机名,也就是说配置在哪台虚拟机上就在那台虚拟机上进行启动
yarn.application.classpath 配置yarn执行任务调度的类路径,如果不配置,yarn虽然可以启动,但执行不了mapreduce。执行hadoop classpath命令,将出现的类路径放在<value>标签里
(注:其他机器启动是没有效果的)
5.4配置workds,这个是DataNode的地址,只需要把所有的datanode主机名填进去就好了
master slave-01 slave-02
workers 配置datanode工作的机器,而datanode主要是用来存放数据文件的,我这里配置了3台,可能你会疑惑,msater怎么也可以配置进去。其实,master我既配置作为namenode,它也可以充当datanode。当然你也可以选择不将namenode节点也配置进来。
6、把master上配置好的hadoop复制到slave-01 slave-02上,集群内所有主机配置完全一样的,所以复制过去后不用改什么
7、启动
7.1、登录master服务器对namenode进行格式化,格式化namenode是不会失败的,如果失败,请到各个节点的tmp路径进行删除操作,然后重新格式化namenode。
cd hadoop-3.2.1/bin/
./hdfs namenode -format

以上信息说明格式化成功~
7.2、登录master服务器启动hdfs
cd hadoop-3.2.1/sbin/
./start-dfs.sh
此时master上进程
[root@master sbin]# jps 111908 NameNode 112062 DataNode 112398 Jps
slave-01上进程
[root@slave-01 bin]# jps 121945 Jps 121823 DataNode
slave-02 上进程
[root@slave-02 sbin]# jps 7424 DataNode 7506 SecondaryNameNode 7571 Jps
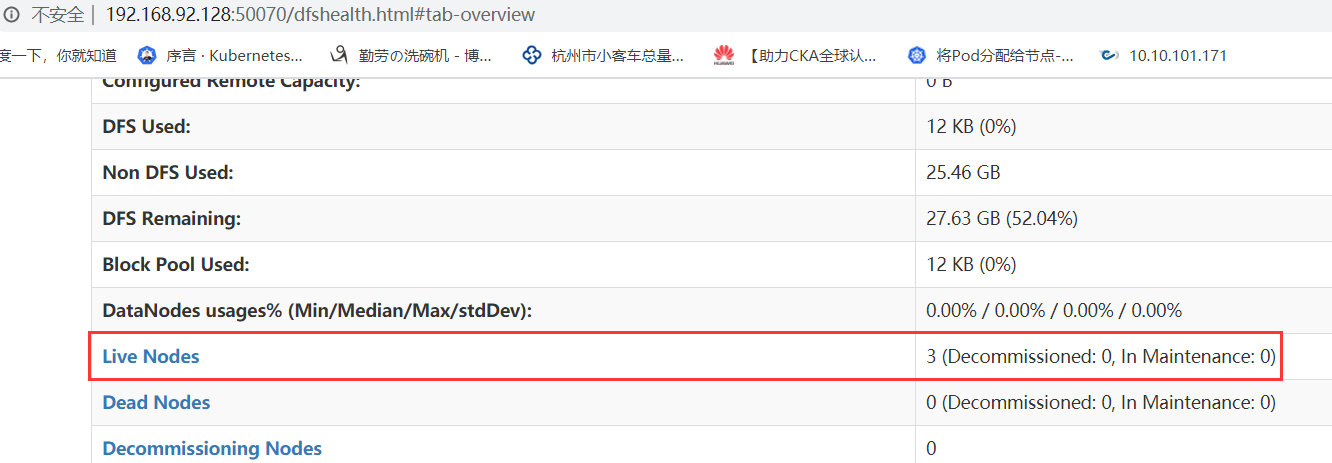
登录namenode 地址发现3台已存活
http://192.168.92.128:50070/
7.4、登录slave-01服务器 启动yarn
./start-yarn.sh
此时至于slave-01上有Nodemanager服务
[root@slave-02 sbin]# jps 123173 NodeManager 123336 Jps 121823 DataNode 123039 ResourceManager

在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。
至此 hadoop集群搭建完成了,接下来就可以进行hadoop命令进行文件操作和并行计算了。
异常解决:
1、启动后没有namennode
一般是因为格式了俩次造成的,造成了namespaceID不一致(hadoop-3.2.1/data/dfs/name/current/VERSION可以查看namespaceID),解决办法就是删除这些文件,重新格式即可。
如果id 一致,可以查看日志文件hadoop-3.2.1/logs/内查看namenode日志
Hadoop HA集群
https://my.oschina.net/u/3754001/blog/1802135
https://blog.csdn.net/u012760435/article/details/104401268
https://blog.csdn.net/u012760435/article/details/104541021
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,这就需要利用使用ZooKeeper了。首先HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。
首先需要注意一点,Yarn与HDFS属于两个不同的集群,一个负责文件存储,一个负责作业调度,二者之间没有必然关系,也不一定说Yarn的某些节点必须必须要放在datanaode上。通常会把nodemanager和datanode放在一起是因为要“计算向数据移动”,尽可能使计算作业就在存储节点上执行。hdfs集群启动后仅仅是一个分布式文件系统而已,并不具备计算的能力,因此引出yarn。
针对HDFS集群主要修改的有core-site.xml,hadoop-env.sh,hdfs-site.xml。对于hadoop集群中所有节点配置文件都是一样的,所以只在一台机器上进行修改然后分发即可
core-site.xml
<configuration>
<!--HDFS主入口,mycluster仅是作为集群的逻辑名称,可随意更改但务必与hdfs-site.xml中dfs.nameservices值保持一致-->
<property> <name>fs.defaultFS</name>
<value>hdfs://hdfs-cluster</value>
</property>
<!--默认的hadoop.tmp.dir指向的是/tmp目录,将导致namenode与datanode数据全都保存在易失目录中,此处进行修改-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-3.2.1/data</value>
<description>Abase for other temporary directories.</description>
</property>
<!--用户角色配置,不配置此项会导致web页面报错-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--zookeeper集群地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.7.1:2181,192.168.7.2:2181,192.168.7.3:2181</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!--文件副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--集群名称,此值在接下来的配置中将多次出现务必注意同步修改-->
<property>
<name>dfs.nameservices</name>
<value>hdfs-cluster</value>
</property>
<!--所有的namenode列表,此处也只是逻辑名称,非namenode所在的主机名称-->
<property>
<name>dfs.ha.namenodes.hdfs-cluster</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-3.2.1/data/namenode</value>
</property>
<!--namenode之间用于RPC通信的地址,value填写namenode所在的主机地址
默认端口8020,注意hdfs-cluster与nn1要和上文的配置一致
-->
<property>
<name>dfs.namenode.rpc-address.hdfs-cluster.nn1</name>
<value>192.168.7.1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hdfs-cluster.nn2</name>
<value>192.168.7.2:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hdfs-cluster.nn3</name>
<value>192.168.7.3:8020</value>
</property>
<!--namenode的web访问地址,默认端口9870-->
<property>
<name>dfs.namenode.http-address.hdfs-cluster.nn1</name>
<value>192.168.7.1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.hdfs-cluster.nn2</name>
<value>192.168.7.2:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.hdfs-cluster.nn3</name>
<value>192.168.7.3:9870</value>
</property>
<!--journalnode主机地址,最少三台,默认端口8485-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.7.1:8485;192.168.7.2:8485;192.168.7.3:8485/hdfs-cluster</value>
</property>
<!--故障时自动切换的实现类-->
<property>
<name>dfs.client.failover.proxy.provider.hdfs-cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--故障时相互操作方式(namenode要切换active和standby),这里我们选ssh方式-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<!--namenode日志文件输出路径,即journalnode读取变更的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-3.2.1/journalnode</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>~/.ssh/id_rsa</value>
</property>
<!---->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-3.2.1/data/datanode</value>
</property>
<!--启用自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>false</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--yarn集群id-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<!--启用HA-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>192.168.7.11</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>192.168.7.12</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>192.168.7.13</value>
</property>
<!--webapp的地址务必要配置,不然yarn可以启动但是无法执行map任务 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>192.168.7.11:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>192.168.7.12:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>192.168.7.13:8088</value>
</property>
<property>
<name>hadoop.zk.address</name>
<value>192.168.7.1:2181,192.168.7.2:2181,192.168.7.3:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--持久化方式,既然启用了ZK那就把信息存储到ZK里面-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- Bind to all interfaces -->
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.nodemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.timeline-service.bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- /Bind to all interfaces -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
启动集群
注:--daemon 是仅在本机启动某个服务,--daemons是所以namenode服务器启动某服务,不要搞错了
1、三台服务器上启动zk jps可以看到有QuorumPeerMain 进程,监听2181 3881 8080 端口 2、hadoop-3.2.1/bin/hdfs --daemon start journalnode (所以服务器上启动JN) jps 多个JournalNode进程,监听8480 8485俩个端口 3、bin/hdfs namenode -format -force -nonInteractive (随便一台namenode上启动即可) 4、bin/hdfs --daemon start namenode (刚刚格式化的服务器上启动namenode) jps多个NameNode进程,监听9870 8020端口 5、bin/hdfs namenode -bootstrapStandby(其他俩台namenode服务器同步namenode数据) 没有新建进程 监听端口 6、/opt/hadoop-3.2.1/bin/hdfs --daemon start namenode (其他俩台同步信息后,再都启动namenode) jps多个NameNode进程,监听9870 8020端口 7、bin/hdfs zkfc -formatZK (任一namenode上格式化zk) 没有新建进程 监听端口,但zk里会多个hadoop-ha目录 -------------------- 在各个NameNode节点上启动DFSZK Failover Controller,先在哪台机器启动,哪个机器的NameNode就是Active NameNode bin/hdfs --daemon start zkfc 注:如果使用start-dfs.sh启动集群,则不需要单独启动zkfc --------------------- 8、sbin/start-dfs.sh (任一namenode启动hdfs 集群)
所有namenode服务器多个DFSZKFailoverController进程,监听8019端口
至此hdfs 集群全部启动完毕
启动yarn集群
所有yarn服务器上直接sbin/start-yarn.sh 即可
一些异常解决:
没有配置/etc/hosts造成的,
2020-04-12 17:02:21,040 WARN org.apache.hadoop.ha.ActiveStandbyElector: Exception handling the winning of election java.lang.RuntimeException: Mismatched address stored in ZK for NameNode at /172.16.210.126:8020: Stored protobuf was nameserviceId: "hdfs-cluster" namenodeId: "nn2" hostname: "hadoop-1" port: 8020 zkfcPort: 8019 , address from our own configuration for this NameNode was /172.16.210.126:8020
有多个网卡造成的,我是修改了/etc/hosts文件把localhost指向了内网地址解决的
192.168.7.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
2020-04-13 16:18:03,668 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode. java.lang.IllegalArgumentException: The value of property bind.address must not be null
权限造成的
ERROR: Attempting to operate on hdfs zkfc as root
ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation.
ERROR: Attempting to operate on hdfs journalnode as root
ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation.
解决:
start-dfs.sh stop-dfs.sh添加如下:
HDFS_ZKFC_USER=root
HDFS_JOURNALNODE_USER=root
zk无法启动,显示UnknownHostException: hadoop-ha-hdfs-zk-3.hadoop-ha-hdfs-zk
原因如报错,网上有解决方案是在zoo.cfg添加 quorumListenOnAllIPs=true,这是个大坑,这样虽然
zk启动成功,用zkServer.sh status 显示follower 或leader,但用zkCli.sh 连接后 使用 ls / 会显示如下错误,hdfs ha格式化zk时也会提示连不上zk集群
Unable to read additional data from server sessionid 0x0
我的解决方法是
测试
#检查namenode状态 hdfs haadmin -getServiceState nn1 standby #在namenode查看集群情况
hdfs dfsadmin -report
#检查yarn状态
yarn rmadmin -getServiceState rm1
yarn node -list

