CPU相关的学习
我理解的CPU
目前对cpu的了解停留在这个水平
查看CPU型号:
cat /proc/cpuinfo |grep model |tail -n 1
model name : Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz
查看有多少processor:
cat /proc/cpuinfo |grep processor|tail -n 1
processor : 23
然后对性能要求就是主频越高越好,processor越多越好,其它的知道的很少,由于需要做性能相关调优,所以对CPU这一块做一个系统的学习,如果参考网上的一些CEPH性能调优的资料,很多地方都是让关闭numa,以免影响性能,这个从来都是只有人给出答案,至于为什么,对不对,适合不适合你的环境,没有人给出来,没有数据支持的调优都是耍流氓
单核和多核
在英文里面,单核(single-core)和多核(multi-core)多称作uniprocessor和multiprocessor,这里先对这些概念做一个说明:
这里所说的core(或processor),是一个泛指,是从使用者(或消费者)的角度看计算机系统。因此,core,或者processor,或者处理器(CPU),都是逻辑概念,指的是一个可以独立运算、处理的核心。
而这个核心,可以以任何形式存在,例如:单独的一个chip(如通常意义上的单核处理器);一个chip上集成多个核心(如SMP,symmetric multiprocessing);一个核心上实现多个hardware context,以支持多线程(如SMT,Simultaneous multithreading);等等。这是从硬件实现的角度看的。
最后,从操作系统进程调度的角度,又会统一看待这些不同硬件实现的核心,例如上面开始所提及的CPU(24个CPUs,从0编号开始),因为它们都有一个共同的特点:执行进程(或线程)。
NUNA与SMP的概念
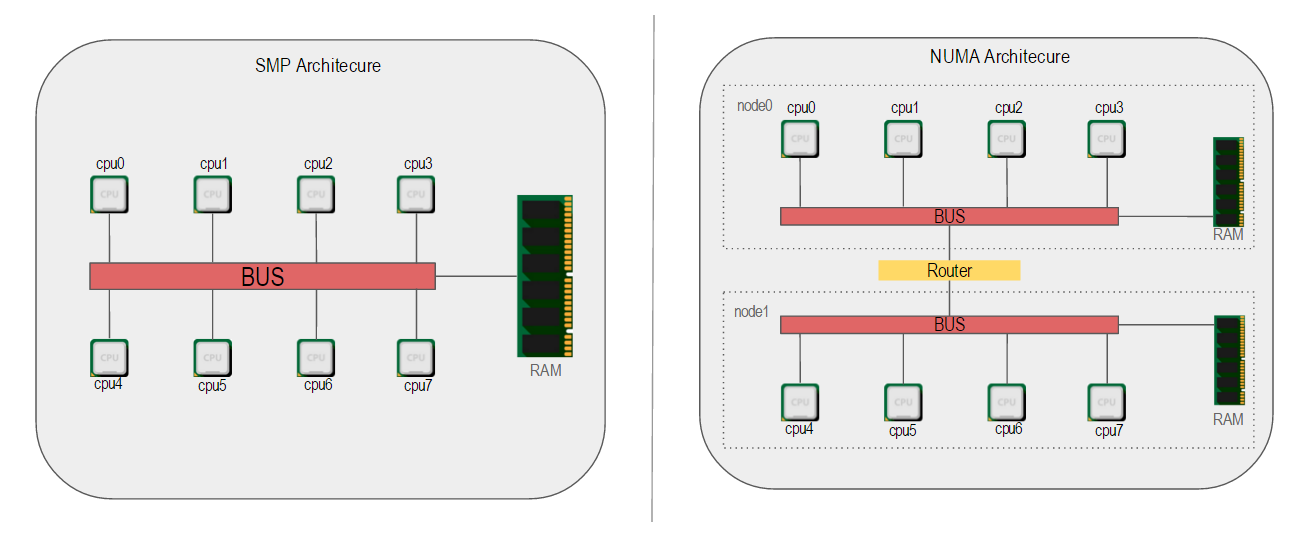
NUMA(Non-Uniform Memory Access,非一致性内存访问)和SMP(Symmetric Multi-Processor,对称多处理器系统)是两种不同的CPU硬件体系架构
SMP(Symmetric Multi-Processing)的主要特征是共享,所有的CPU共享使用全部资源,例如内存、总线和I/O,多个CPU对称工作,彼此之间没有主次之分,平等地访问共享的资源,这样势必引入资源的竞争问题,从而导致它的扩展内力非常有限。特别是在现在一台机器CPU核心比较多,内存比较大的情况
NUMA技术将CPU划分成不同的组(Node),每个Node由多个CPU组成,并且有独立的本地内存、I/O等资源。Node之间通过互联模块连接和沟通,因此除了本地内存外,每个CPU仍可以访问远端Node的内存,只不过效率会比访问本地内存差一些,我们用Node之间的距离(Distance,抽象的概念)来定义各个Node之间互访资源的开销。
本章主要是去做NUMA的相关探索,下图是一个多核系统简单的topology
Node->Socket->Core->Processor(Threads)
如果你只知道CPU这么一个概念,那么是无法理解CPU的拓扑的。事实上,在NUMA架构下,CPU的概念从大到小依次是:Node、Socket、Core、Processor
- Sockets 可以理解成主板上cpu的插槽数,物理cpu的颗数,一般同一socket上的core共享三级缓存
- Cores 而Socket中的每个核心被称为Core,常说的核,核有独立的物理资源.比如单独的一级二级缓存什么的
- Threads 为了进一步提升CPU的处理能力,Intel又引入了HT(Hyper-Threading,超线程)的技术,一个Core打开HT之后,在OS看来就是两个核,当然这个核是逻辑上的概念,所以也被称为Logical Processor,如果不开超线程,threads应该与cores相等,如果开了超线程,threads应该是cores的倍数.相互之间共享物理资源
- Nodes 上图的多核图中没有涉及, Node是NUMA体系中的概念.由于SMP体系中各个CPU访问内存只能通过单一的通道.导致内存访问成为瓶颈,cpu再多也无用.后来引入了NUMA.通过划分node,每个node有本地RAM,这样node内访问RAM速度会非常快.但跨Node的RAM访问代价会相对高一点,下面看一下两种架构的明显区别
由此可以总结这样的逻辑关系(包含):Node > Socket > Core > Thread 区分这几个概念为了了解cache的分布,因为cpu绑定的目的就是提高cache的命中率,降低cpu颠簸.所以了解cache与cpu之间的mapping关系是非常重要的.通常来讲:
- 同Socket内的cpu共享三级级缓存
- 每个Core有自己独立的二级缓存
- 一个Core上超线程出来的Threads,避免绑定,看似可能会提高L2 cache命中率,但也可能有严重的cpu争抢,导致性能非常差.
查看CPU信息
[root@server9 ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 62
Model name: Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz
Stepping: 4
CPU MHz: 1607.894
BogoMIPS: 4205.65
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 15360K
NUMA node0 CPU(s): 0-5,12-17
NUMA node1 CPU(s): 6-11,18-23
2颗6核双线程,一共是24 processors,也可以看到是NUMA体系,可以使用以下命令详细查看numa信息.非NUMA体系时,所有cpu都划分为一个Node
[root@server9 ~]# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17
node 0 size: 31880 MB
node 0 free: 19634 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23
node 1 size: 32253 MB
node 1 free: 29315 MB
node distances:
node 0 1
0: 10 21
1: 21 10
cpu的id不连续的原因是开启了超线程,超线程的cpuid是从新的ID开始计数的,也就是从12开始计数的
两个node,每个node32G内存左右,这台机器我的物理内存是64G
通过命令行查看cpu信息
# 获取cpu名称与主频
cat /proc/cpuinfo | grep 'model name' | cut -f2 -d: | head -n1 | sed 's/^ //'
# 获取逻辑核数
cat /proc/cpuinfo | grep 'model name' | wc -l
# 获取物理核数
cat /proc/cpuinfo | grep 'physical id' | sort | uniq | wc -l
# 查看cpu的flags
cat /proc/cpuinfo | grep flags | uniq | cut -f2 -d : | sed 's/^ //'
# 是否打开超线程(检查 physical id * cpu cores 与 processor的比例 1:1为未开启)
cat /proc/cpuinfo
# 查看cache大小,X自省替换
sudo cat /sys/devices/system/cpu/cpuX/cache/indexX/size
# 查看各个cpu之间与cache的mapping
cat /sys/devices/system/cpu/cpuX/cache/indexX/shared_cpu_list
# 获取CPU分布的信息(id-> core信息)(这一个可以看出来CPU0和CPU12在同一个core)
egrep 'processor|core id|physical id' /proc/cpuinfo | cut -d : -f 2 | paste - - - | awk '{print "CPU"$1"\tsocket "$2" core "$3}'
CPU0 socket 0 core 0
CPU1 socket 0 core 1
CPU2 socket 0 core 2
CPU3 socket 0 core 3
CPU4 socket 0 core 4
CPU5 socket 0 core 5
CPU6 socket 1 core 0
CPU7 socket 1 core 1
CPU8 socket 1 core 2
CPU9 socket 1 core 3
CPU10 socket 1 core 4
CPU11 socket 1 core 5
CPU12 socket 0 core 0
CPU13 socket 0 core 1
CPU14 socket 0 core 2
CPU15 socket 0 core 3
CPU16 socket 0 core 4
CPU17 socket 0 core 5
CPU18 socket 1 core 0
CPU19 socket 1 core 1
CPU20 socket 1 core 2
CPU21 socket 1 core 3
CPU22 socket 1 core 4
CPU23 socket 1 core 5
lscpu,numactl都是读取proc,sys文件系统信息并进行格式化,输出人性化的内容.当没有网络,而lscpu,numactl都没有安装时,只能使用这种命令行方式了
能用工具还是用工具,工具就是解放双手的
Cpu Topology可视化
lstopo 指令由 hwloc 数据包提供,创建了用户的系统示意图。lstopo-no-graphics 指令提供详尽的文本输出
通过lscpu与numactl获取的信息,必要的时候查询了/sys/devices/system/cpu/cpuX/*的数据将正在使用的 Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz的topology进行可视化
详细的cache信息可以通过sysfs查看
ls /sys/devices/system/cpu/cpu0/cache/
index0 index1 index2 index3
包含以下4个目录:
- index0:1级数据cache
- index1:1级指令cache
- index2:2级cache
- index3:3级cache,对应cpuinfo里的cache
目录里的文件是cache信息描述,以本机的cpu0/index0为例简单解释一下:
| 文件 | 内容 | 说明 |
|---|---|---|
| type | Data | 数据cache,如果查看index1就是Instruction |
| Level | 1 | L1 |
| Size | 32K | 大小为32K |
| coherency_line_size | 64 | 644128=32K |
| physical_line_partition | 1 | |
| ways_of_associativity | 4 | |
| number_of_sets | 128 | |
| shared_cpu_map | 00000101 | 表示这个cache被CPU0和CPU8 share |
解释一下shared_cpu_map内容的格式:
表面上看是2进制,其实是16进制表示,每个bit表示一个cpu,1个数字可以表示4个cpu 截取00000101的后4位,转换为2进制表示
|CPU id|15|14|13|12|11|10|9|8|7|6|5|4|3|2|1|0|
| :---: | :---: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
|0×0101的2进制表示|0|0|0|0|0|0|0|1|0|0|0|0|0|0|0|1|
0101表示cpu8和cpu0,即cpu0的L1 data cache是和cpu8共享的。
也可以使用上面提到的lstopo-no-graphics命令进行查询
[root@server9 ~]# lstopo-no-graphics
Machine (63GB)
NUMANode L#0 (P#0 31GB)
Socket L#0 + L3 L#0 (15MB)
L2 L#0 (256KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0
PU L#0 (P#0)
PU L#1 (P#12)
L2 L#1 (256KB) + L1d L#1 (32KB) + L1i L#1 (32KB) + Core L#1
PU L#2 (P#1)
PU L#3 (P#13)
L2 L#2 (256KB) + L1d L#2 (32KB) + L1i L#2 (32KB) + Core L#2
PU L#4 (P#2)
PU L#5 (P#14)
L2 L#3 (256KB) + L1d L#3 (32KB) + L1i L#3 (32KB) + Core L#3
PU L#6 (P#3)
PU L#7 (P#15)
L2 L#4 (256KB) + L1d L#4 (32KB) + L1i L#4 (32KB) + Core L#4
PU L#8 (P#4)
PU L#9 (P#16)
L2 L#5 (256KB) + L1d L#5 (32KB) + L1i L#5 (32KB) + Core L#5
PU L#10 (P#5)
PU L#11 (P#17)
HostBridge L#0
PCIBridge
PCI 1000:0086
PCIBridge
PCI 8086:1521
Net L#0 "enp4s0f0"
PCI 8086:1521
Net L#1 "enp4s0f1"
PCI 8086:1521
Net L#2 "enp4s0f2"
PCI 8086:1521
Net L#3 "enp4s0f3"
PCIBridge
PCI 8086:10fb
Net L#4 "enp6s0f0"
PCI 8086:10fb
Net L#5 "enp6s0f1"
PCIBridge
PCI 8086:1d6b
PCIBridge
PCI 102b:0532
GPU L#6 "card0"
GPU L#7 "controlD64"
PCI 8086:1d02
Block L#8 "sda"
NUMANode L#1 (P#1 31GB) + Socket L#1 + L3 L#1 (15MB)
L2 L#6 (256KB) + L1d L#6 (32KB) + L1i L#6 (32KB) + Core L#6
PU L#12 (P#6)
PU L#13 (P#18)
L2 L#7 (256KB) + L1d L#7 (32KB) + L1i L#7 (32KB) + Core L#7
PU L#14 (P#7)
PU L#15 (P#19)
L2 L#8 (256KB) + L1d L#8 (32KB) + L1i L#8 (32KB) + Core L#8
PU L#16 (P#8)
PU L#17 (P#20)
L2 L#9 (256KB) + L1d L#9 (32KB) + L1i L#9 (32KB) + Core L#9
PU L#18 (P#9)
PU L#19 (P#21)
L2 L#10 (256KB) + L1d L#10 (32KB) + L1i L#10 (32KB) + Core L#10
PU L#20 (P#10)
PU L#21 (P#22)
L2 L#11 (256KB) + L1d L#11 (32KB) + L1i L#11 (32KB) + Core L#11
PU L#22 (P#11)
PU L#23 (P#23)
这个得到的是文本的拓扑,这个转换成一个图看的要清楚一些
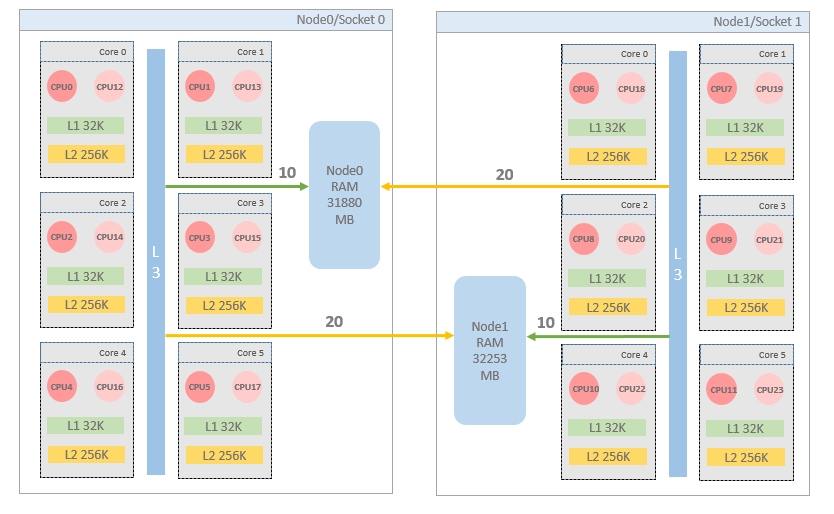
NUMA分组信息
- 通过图可以看到cpu为numa架构,且有两个node
- 将同一socket内的cpu(threads)都划分在一个node中.通过上图也解释了node中cpu序列不连续的问题.因为同一个Core上的两个Threads是超线程出来的.超线程Thread的cpu id在原有的core id基础上增长的
- 每个node中有32G左右的本地RAM可用
cache信息
- 每个core都有独立的二级缓存,而不是socket中所有的core共享二级缓存
- 同node中的cpu共享三级缓存
- 跨node的内存访问的花费要大些
cpu绑定注意的几点
- Numa体系中,如果夸node绑定,性能会下降.因为L3 cache命中率低,跨node内存访问代价高.
- 绑定同Node,同一个Core中的两个超线程出来的cpu,性能会急剧下降.cpu密集型的线程硬件争用严重.”玩转CPU Topology”中也提到了.
- Numa架构可能引起swap insanity.需要注意
测试CPU绑定性能
这个部分就不在这里赘述了,上面是把cpu比较清晰的剥离出来,至于效果,需要在实际环境当中去验证了,有可能变坏,也有可能变好
本篇参考了很多网络上的很多其他资料

