

python之刷博客访问量
通过写刷访问量学习正则匹配
说明信息
说明:仅仅是为了熟悉正则表达式以及网页结构,并不赞成刷访问量操作。
1.刷访问量第一版
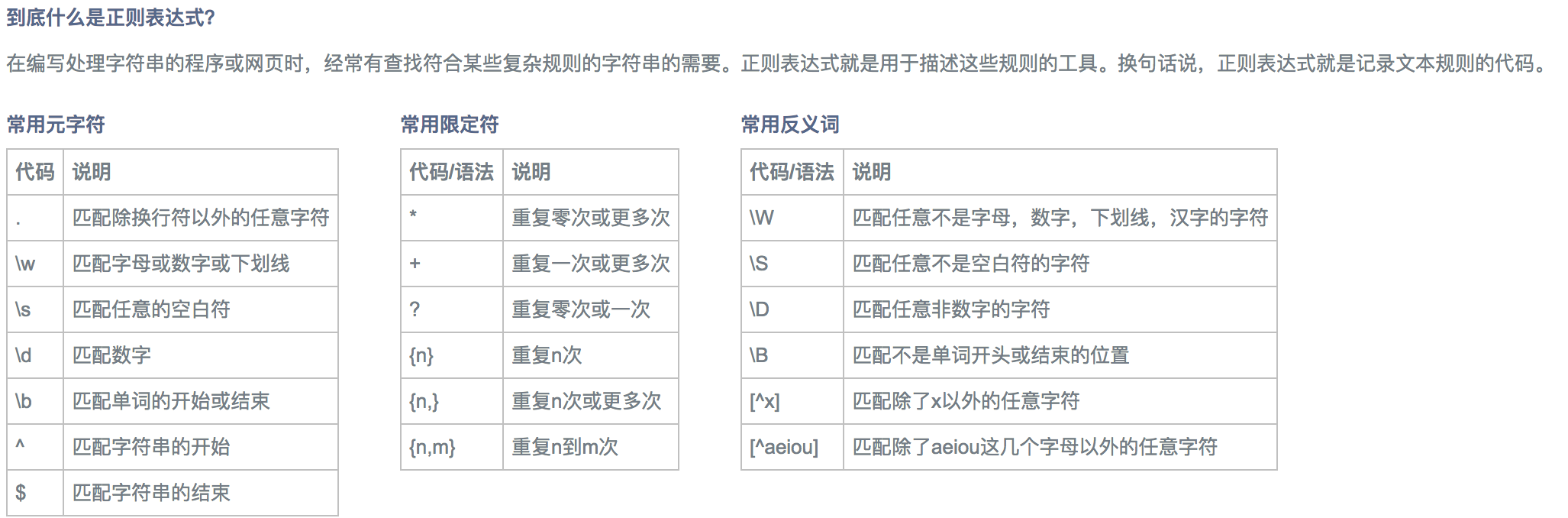
1.1 确定网页url结构,构造匹配模式串
首先是要确定刷的网页。第一版实现了爬取博客园的网页。下面为模式匹配的规则,该规则需要根据网页的url结构进行适当的调整。通过查看得到当前的博客园的结构如下图所示:
因此通过构造匹配串如下所示:pr=r'href="http://www.cnblogs.com/zpfbuaa/p/(\d+)' rr=re.compile(pr)正则表达式的规则如下图简单介绍:
另外附上正则表达式在线测试工具。快速跳转至测试工具

1.2 获取代理ip列表以及user_agent_list初始构造
获取代理ip地址以及端口号。下面推荐代理ip网页,当时最近发现好像出问题了。不过这些高匿的ip代理提供商有不少免费的ip可供使用,需要的就是将这些ip和port整理起来。
下面所给的方法需要根据不同的ip提供商的网页结构进行修改。比如有些ip提供商的网页并不是table结构的,或者结构比较复杂。因此进行正则匹配,以及分析网页结构(神奇的F12)是非常必要的。
同时为了避免多个相同用户端进行请求,则初始化构造一个user_agent_list用来之后网页访问中的头部信息构造。
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
接下来进行代理ip列表的获取。同时统计出代理ip地址的总个数。
需要注意下面的正则表达式需要根据网页结构的不同来进行相应的改变
def Get_proxy_ip():
global proxy_list
global totalnum
proxy_list = []
headers = {
'Host': 'www.xicidaili.com',
'User-Agent':'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.xicidaili.com/',
}
req = urllib2.Request(r'http://www.xicidaili.com/nn/', headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+',html)
port_list = re.findall(r'<td>\d+</td>',html)
for i in range(len(ip_list)):
totalnum+=1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' %(ip,port)
proxy_list.append(proxy)
headers = {
'Host': 'www.xicidaili.com',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.xicidaili.com/',
}
req = urllib2.Request(r'http://www.xicidaili.com/nn/5', headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+', html)
port_list = re.findall(r'<td>\d+</td>', html)
for i in range(len(ip_list)):
totalnum+=1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' % (ip, port)
proxy_list.append(proxy)
return proxy_list
1.3 构造url博文列表
对于博客园的博文url列表的构造有不同的方法,其中一个为:将当前网页上的url进行筛选,得到所有满足条件的博文,然后将博文的url存储起来,以待后续的访问使用。
下面针对我的博客进行简单举例说明:
首先确定第一级网页url:
yeurl=['http://www.cnblogs.com/zpfbuaa/p/?page=1', 'http://www.cnblogs.com/zpfbuaa/p/?page=2', 'http://www.cnblogs.com/zpfbuaa/p/?page=3']这里设置的yeurl是作为第一级网页,然后从这个列表中得到所有的博文url(也就是需要读取上述网页结构,进行匹配操作)。
接下来进行循环,针对每一个yeurl里面的网页进行读取筛选操作。如下代码块所示:
def main():
list1=[]
list2=[]
global l
global totalblog
global ip_list
pr=r'href="http://www.cnblogs.com/zpfbuaa/p/(\d+)'
rr=re.compile(pr)
yeurl=['http://www.cnblogs.com/zpfbuaa/p/?page=1','http://www.cnblogs.com/zpfbuaa/p/?page=2','http://www.cnblogs.com/zpfbuaa/p/?page=3']
for i in yeurl:
req=urllib2.Request(i)
# proxy_ip = random.choice(proxyIP.proxy_list) # 在proxy_list中随机取一个ip
# print proxy_ip
# proxy_support = urllib2.ProxyHandler(proxy_ip)
# opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
req.add_header("User-Agent","Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)")
cn=urllib2.urlopen(req)
f=cn.read()
list2=re.findall(rr,f)
list1=list1+list2
cn.close()
for o in list1:
totalblog=totalblog+1
url='http://www.cnblogs.com/zpfbuaa/p/'+o+".html"
l.append(url)
Get_proxy_ip()
print totalnum
- 上述的list1表示博文的编号,如上如中的/p/6995410, 此时的list1中存储的都是类似6995410的key
- req.add_header 添加头部信息,使用库urllib2进行网页的请求打开等操作
1.4 进行网页访问操作
前面已经构造了代理ip的列表、用户请求信息列表、下面的函数传递的参数为博文的url,这里的博文url在之前也已经构造好保存在l这个list中了。
这里使用随机选取代理ip以及用户请求信息列表,并且为了避免尝试打开网页导致过长的时间等待,设置超时时间为timeout=3,单位为秒。顺便统计出一共刷网页的次数以及打印出当前访问的网页url地址。
代码如下所示:
def su(url):
proxy_ip = random.choice(proxy_list)
user_agent = random.choice(user_agent_list)
print proxy_ip
print user_agent
proxy_support = urllib2.ProxyHandler({'http': proxy_ip})
opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
req = urllib2.Request(url)
req.add_header("User-Agent", user_agent)
try:
c = urllib2.urlopen(req, timeout=3)
except Exception as e:
print('******打开失败!******')
else:
global count
count +=1
print('OK!总计成功%s次!'%count)
print "当前刷的网址为"
print url
sem.release()
设置线程数目最大量为5,打印博客列表中的数目信息。遍历保存博文url的列表l然后针对每一个其中的url这里为变量i,将其传递至函数su,并开启线程进行博客访问操作。
if __name__ == "__main__":
main()
print "开始刷访问量!"
print "共计博客个数为 "
print totalblog
maxThread=5
sem=threading.BoundedSemaphore(maxThread)
while 1:
for i in l:
sem.acquire()
T=threading.Thread(target=su,args=(i,))
T.start()
1.5 刷访问量第一版代码
# coding=utf-8
import urllib2
import re
import sys
import time
import threading
import request
import random
l=[]
iparray=[]
global totalnum
totalnum = 0
global proxy_list
proxy_list=[]
global count
count = 0
totalblog=0
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
def Get_proxy_ip():
global proxy_list
global totalnum
proxy_list = []
headers = {
'Host': 'www.xicidaili.com',
'User-Agent':'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.xicidaili.com/',
}
req = urllib2.Request(r'http://www.xicidaili.com/nn/', headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+',html)
port_list = re.findall(r'<td>\d+</td>',html)
for i in range(len(ip_list)):
totalnum+=1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' %(ip,port)
proxy_list.append(proxy)
headers = {
'Host': 'www.xicidaili.com',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.xicidaili.com/',
}
req = urllib2.Request(r'http://www.xicidaili.com/nn/5', headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+', html)
port_list = re.findall(r'<td>\d+</td>', html)
for i in range(len(ip_list)):
totalnum+=1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' % (ip, port)
proxy_list.append(proxy)
return proxy_list
def main():
list1=[]
list2=[]
global l
global totalblog
global ip_list
pr=r'href="http://www.cnblogs.com/zpfbuaa/p/(\d+)'
rr=re.compile(pr)
yeurl=['http://www.cnblogs.com/zpfbuaa/p/?page=1','http://www.cnblogs.com/zpfbuaa/p/?page=2','http://www.cnblogs.com/zpfbuaa/p/?page=3']
for i in yeurl:
req=urllib2.Request(i)
# proxy_ip = random.choice(proxyIP.proxy_list) # 在proxy_list中随机取一个ip
# print proxy_ip
# proxy_support = urllib2.ProxyHandler(proxy_ip)
# opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
req.add_header("User-Agent","Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)")
cn=urllib2.urlopen(req)
f=cn.read()
list2=re.findall(rr,f)
list1=list1+list2
cn.close()
for o in list1:
totalblog=totalblog+1
url='http://www.cnblogs.com/zpfbuaa/p/'+o+".html"
l.append(url)
Get_proxy_ip()
print totalnum
def su(url):
proxy_ip = random.choice(proxy_list)
user_agent = random.choice(user_agent_list)
print proxy_ip
print user_agent
proxy_support = urllib2.ProxyHandler({'http': proxy_ip})
opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
req = urllib2.Request(url)
req.add_header("User-Agent", user_agent)
try:
c = urllib2.urlopen(req, timeout=3)
except Exception as e:
print('******打开失败!******')
else:
global count
count +=1
print('OK!总计成功%s次!'%count)
print "当前刷的网址为"
print url
sem.release()
if __name__ == "__main__":
main()
print "开始刷访问量!"
print "共计博客个数为 "
print totalblog
maxThread=5
sem=threading.BoundedSemaphore(maxThread)
while 1:
for i in l:
sem.acquire()
T=threading.Thread(target=su,args=(i,))
T.start()
2.刷访问量完整第二版
2.1 增加代理IP获取数量
之前的函数
def get_proxy_ip()可以从网址http://www.xicidaili.com/nn/中得到代理ip,但是这样的局限性较大。本版本添加新的代理ip地址,通过函数def get_proxy_ip2实现,以及函数def get_proxy_ip3。这样做的目的是熟悉一下python中的正则表达式,另外顺便稍微改一下版本而已。具体函数见最后的完整代码。
2.2 增加自动删除不可用代理ip
之前设置了过期时间,每当使用某个代理ip进行连接时,一旦产生超时,只是打印出产生异常而不进行处理,本次修改为将不可用的代理ip进行删除。也许这样做不是很好,尤其是在代理ip地址很少的时候,可能很快就用完了代理ip。因此这里可能作为一个改进的地方。
2.3 增加博客列表
这里的变化仅仅是提升第一级网页构造。利用网页url结构以及循环,构造出第一级网页的url列表。然后遍历每个网页进行博文url的搜索和筛选保存操作。具体实现见最后的完整代码。
2.4 改版完整代码
# coding=utf-8
import urllib2
import re
import threading
import random
proxy_list = []
total_proxy = 0
blog_list = []
total_blog = 0
total_visit = 0
total_remove = 0
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
# request_list = ['http://www.xicidaili.com/nn/','http://www.xicidaili.com/nn/4','http://www.xicidaili.com/nn/5']
def get_proxy_ip():
global proxy_list
global total_proxy
request_list = []
headers = {
'Host': 'www.xicidaili.com',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.xicidaili.com/',
}
for i in range(11, 21):
request_item = "http://www.xicidaili.com/nn/" + str(i)
request_list.append(request_item)
for req_id in request_list:
req = urllib2.Request(req_id, headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+', html)
port_list = re.findall(r'<td>\d+</td>', html)
for i in range(len(ip_list)):
total_proxy += 1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' % (ip, port)
proxy_list.append(proxy)
return proxy_list
def get_proxy_ip2():
global proxy_list
global total_proxy
request_list = []
headers = {
'Host': 'http://www.66ip.cn/',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Accept': r'application/json, text/javascript, */*; q=0.01',
'Referer': r'http://www.66ip.cn/',
}
for i in range(1, 50):
request_item = "http://www.66ip.cn/" + str(i) + ".html"
request_list.append(request_item)
for req_id in request_list:
req = urllib2.Request(req_id, headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+', html)
port_list = re.findall(r'<td>\d+</td>', html)
for i in range(len(ip_list)):
total_proxy += 1
ip = ip_list[i]
port = re.sub(r'<td>|</td>', '', port_list[i])
proxy = '%s:%s' % (ip, port)
proxy_list.append(proxy)
return proxy_list
def get_proxy_ip3():
global proxy_list
global total_proxy
request_list = []
headers = {
# 'Host': 'http://www.youdaili.net/',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
# 'Accept': r'application/json, text/javascript, */*; q=0.01',
# 'Referer': r'http://www.youdaili.net/',
}
# for i in range(2, 6):
# request_item = "http://www.youdaili.net/Daili/QQ/36811_" + str(i) + ".html"
first = "http://www.youdaili.net/Daili/guowai/"
req = urllib2.Request(first, headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
request_id = re.findall(r'href="http://www.youdaili.net/Daili/guowai/(\d+).html', html)
print request_id
for item in request_id:
request_item = "http://www.youdaili.net/Daili/guowai/" + str(item) + ".html"
request_list.append(request_item)
print request_list
# request_item="http://www.youdaili.net/Daili/guowai/4821.html"
# request_list.append(request_item)
# for i in range(2, 6):
# request_item = "http://www.youdaili.net/Daili/QQ/36811_" + str(i) + ".html"
# request_list.append(request_item)
for req_id in request_list:
req = urllib2.Request(req_id, headers=headers)
response = urllib2.urlopen(req)
html = response.read().decode('utf-8')
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+', html)
port_list = re.findall(r':+\d*@HTTP#', html)
for i in range(len(ip_list) - 20):
total_proxy += 1
ip = ip_list[i]
print port_list[i]
tmp = re.sub(r':', '', port_list[i])
port = re.sub(r'@HTTP#', '', tmp)
proxy = '%s:%s' % (ip, port)
print port
proxy_list.append(proxy)
print proxy_list
return proxy_list
def create_blog_list():
list1 = []
list2 = []
global blog_list
global total_blog
pr = r'href="http://www.cnblogs.com/zpfbuaa/p/(\d+)'
rr = re.compile(pr)
my_blog = []
# my_blog = ['http://www.cnblogs.com/zpfbuaa/p/?page=1', 'http://www.cnblogs.com/zpfbuaa/p/?page=2',
# 'http://www.cnblogs.com/zpfbuaa/p/?page=3']
for i in range(1, 25):
blogitem = "http://www.cnblogs.com/zpfbuaa/p/?page=" + str(i)
my_blog.append(blogitem)
for item in my_blog:
req = urllib2.Request(item)
# proxy_ip = random.choice(proxyIP.proxy_list) # 在proxy_list中随机取一个ip
# print proxy_ip
# proxy_support = urllib2.ProxyHandler(proxy_ip)
# opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
req.add_header("User-Agent", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)")
cn = urllib2.urlopen(req)
f = cn.read()
list2 = re.findall(rr, f)
list1 = list1 + list2
cn.close()
for blog_key in list1:
total_blog = total_blog + 1
url = 'http://www.cnblogs.com/zpfbuaa/p/' + blog_key + ".html"
blog_list.append(url)
def main():
create_blog_list()
# get_proxy_ip()
# get_proxy_ip2()
get_proxy_ip3()
def sorry_to_visit_you(url):
global total_visit
global proxy_list
global total_proxy
global total_remove
proxy_ip = random.choice(proxy_list)
user_agent = random.choice(user_agent_list)
print proxy_ip
print user_agent
proxy_support = urllib2.ProxyHandler({'http': proxy_ip})
opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
req = urllib2.Request(url)
req.add_header("User-Agent", user_agent)
try:
c = urllib2.urlopen(req, timeout=10)
except Exception as e:
proxy_list.remove(proxy_ip)
total_proxy -= 1
total_remove += 1
print "删除ip"
print proxy_ip
print "当前移除代理ip个数为:%d" % total_remove
print('******打开失败!******')
else:
total_visit += 1
print('OK!总计成功%d次!' % total_visit)
print "当前刷的网址为%s" % url
print "当前剩余代理ip个数为:%d" % total_proxy
sem.release()
if __name__ == "__main__":
main()
print "开始刷访问量!"
print "共计代理总数为%s个!" % total_proxy
print "共计博客个数为%s个!" % total_blog
max_thread = 5
sem = threading.BoundedSemaphore(max_thread)
while 1:
for blog_url in blog_list:
sem.acquire()
T = threading.Thread(target=sorry_to_visit_you, args=(blog_url,))
T.start()
2.5 运行截图

作者: 伊甸一点
出处: http://www.cnblogs.com/zpfbuaa/
本文版权归作者伊甸一点所有,欢迎转载和商用(须保留此段声明),且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利.
原文链接 如有问题, 可邮件(zpflyfe@163.com)咨询.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
2016-06-14 数据库复习②
2016-06-14 数据库复习①