
go语言内存对齐
go语言内存对齐
比如:存储int32位和int64位的数据时

没有进行内存对齐,int64会紧跟着int32位进行内存分配
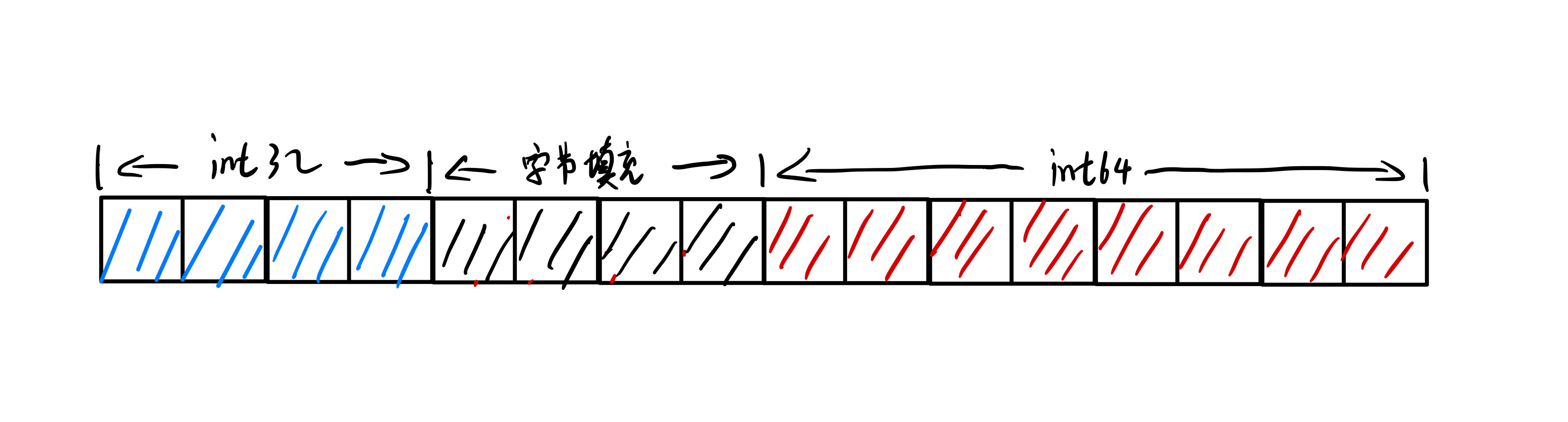
进行内存对齐,将会进行字节填充,使得int64能够从内存地址为8的倍数开始存储
为什么要进行内存对齐
-
跨平台问题:如果数据不对齐,那么在64位字长机器存储的数据可能在32位字长的机器可能就无法正常的读取。
-
性能问题:如果不对齐,那么每个数据要通过多少次总线传输是未知的,如果每次都要处理这些复杂的情况,那么数据的读/写性能将会收到很大的影响。之所以有些CPU支持访问任意地址,是因为处理器在后面多做了很多额外处理。
一看感觉字节对齐后浪费了内存, 但是当我们去读取内存中的数据给CPU时,64位的机器(一次可以原子读取8字节)在内存对齐和不对齐的情况下A变量都只需要原子读取一次就行, 但是对齐后B变量的读取只需一次, 而不对齐的情况下,B需要读取2次,且需要额外的处理牺牲性能来保证2次读取的原子性。所以本质上,内存填充是一种以空间换时间, 通过额外的内存填充来提高内存读取的效率的手段。
内存对齐规则
基本数据类型
| 数据类型 | 类型大小(32位/64位) | 最大对其边界(32位) | 最大对齐边界(64位) |
|---|---|---|---|
| int8/uint8/byte | 1字节 | 1 | 1 |
| int16/uint16 | 2字节 | 2 | 2 |
| int32/uint32/rune/float32/complex32 | 4字节 | 4 | 4 |
| int64/uint64/float64/complex64 | 8字节 | 4 | 8 |
| string | 8字节/16字节 | 4 | 8 |
| slice | 12字节/24字节 | 4 | 8 |
go语言的基本类型的内存对齐是按照基本类型的大小和机器字长中最小值进行对齐,可以看出,如果32位在读取int64��8字节长度的数据时,是无法通过内存对齐保证读取的原子性的。
结构体数据类型
go语言的结构体的对齐是先对结构体的每个字段进行对齐,然后对总体的大小按照最大对齐边界的整数倍进行对齐。空结构体理论上不占用字节,有一个特殊的情况就是,如果空结构体嵌套到一个结构体尾部,那么这个结构体也是要额外对齐的,因为如果有指针指向该字段, 返回的地址将在结构体之外,如果此指针一直存活不释放对应的内存,就会有内存泄露的问题。
原子操作问题
对于前面讲到的32位机器读取int64数据的原子操作问题,在atomic包中有下面一段描述
On 386, the 64-bit functions use instructions unavailable before the Pentium MMX.
On non-Linux ARM, the 64-bit functions use instructions unavailable before the ARMv6k core.
On ARM, 386, and 32-bit MIPS, it is the caller's responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically. The first word in a variable or in an allocated struct, array, or slice can be relied upon to be 64-bit aligned.
在ARM,386,和32位MIPS,调用者有责任安排原子访问的64位字按照8字节对齐,否则程序会panic
开辟的结构体、数组和切片值中的第一个(64位)字可以被认为是8字节对齐的。被开辟可以解读为一个声明的变量、内置函数make或new返回的引用的值, 如果一个切片是从一个开辟的数组派生出来的并且此切片和此数组共享第一个元素,则我们也可以将此切片看作是一个开辟的值。
总结
- 内存对齐可以使cpu更高效的访问内存中的数据
- 可以合理的安排结构体内的字段,来节省内存
- 空结构体不要放在结构体的最后,防止内存浪费
- 32位系统上对于64位数据的原子访问,需要保证8字节对齐


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性