

redis之持久化方案,主从复制,哨兵高可用,集群原理及搭建,缓存优化
目录
redis之持久化方案,主从复制,哨兵高可用,集群原理及搭建,缓存优化
昨日内容回顾
# 悲观锁乐观锁:
django中实现:
悲观锁:mysql 行锁 表锁
乐观锁:真正修改时 加入限制条件
django中事务如何开启
原生sql如何开启事务:begin; commit;
django中如何开启事务:atomic() commit()
dor_update是锁表还是锁行
如果查询条件用了索引/主键 那么select ... for update就会进行锁行
如果是普通字段(没有索引/主键) 那么select ... for update就会进行锁表
# redis geo 地理位置信息---> 存经纬度
计算两点的距离
计算方圆多少范围内的(好友)
今日内容详细
1 持久化方案
# 什么是持久化
redis的所有数据保存在内存中 把内存中的数据同步到硬盘上这个过程称之为持久化
# 持久化的实现方式
快照:某时某刻数据的一个完整备份
mysql的Dump
redis的RDB
写日志:任何操作记录日志 要恢复数据 只要把日志重新走一遍即可
mysql的Binlog
redis的AOF
1.1 RDB
# rdb 持久化配置方式
方式一:通过命令---> 同步操作
save:生成rdb持久化文件
方式二:异步持久化---> 不会阻塞住其他命令的执行
bgsave
方式三:配置文件配置---> 这个条件触发 就执行bgsave
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
dir "/root/redis-6.2.9/data"
如果60s中改变了1w条数据,自动生成rdb
如果300s中改变了10条数据,自动生成rdb
如果900s中改变了1条数据,自动生成rdb

1.2 aof方案
# 可能会数据丢失---> 可以使用aof方案
# aof是什么:客户端每写入一条命令 都记录一条日志 放到日志文件中 如果出现宕机 可以将数据完全恢复
# AOF的三种策略
日志不是直接写到硬盘上 而是先放在缓冲区 缓冲区根据一些策略 写到硬盘上
always:redis---> 写命令刷新到缓冲区---> 每条命令fsync到硬盘---> AOF文件
everysec(默认值):redis---> 写命令刷新到缓冲区---> 每秒把缓冲区fsync到硬盘---> AOF文件
no:redis---> 写命令刷新到缓冲区---> 操作系统决定 缓冲区fsync到硬盘---> AOF文件
# AOF重写
随着命令的逐步写入 并发量的变大 AOF文件会越来越大 通过AOF重写来解决该问题
本质就是把过期的 无用的 重复的 可以优化的命令 来优化 这样可以减少磁盘占有量 加速恢复速度
# AOF重写配置参数
auto-aof-rewrite-min-size:500m
auto-aof-rewrite-percentage:增长率
# aof持久化的配置
appendonly yes #将该选项设置为yes,打开
appendfilename "appendonly.aof" #文件保存的名字
appendfsync everysec #采用第二种策略
no-appendfsync-on-rewrite yes #在aof重写的时候,是否要做aof的append操作,因为aof重写消耗性能,磁盘消耗,正常aof写磁盘有一定的冲突,这段期间的数据,允许丢失
'''在写入这些配置之后 就会进行日志记录'''

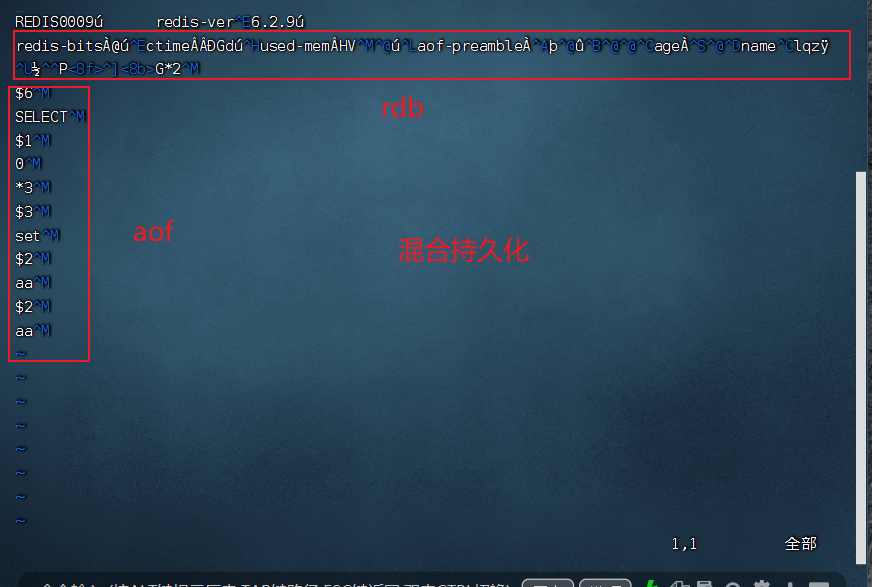
1.3 混合持久化
# 可以同时开启aof和rdb 他们是相互不影响的
# redis4.x以后 出现了混合持久化 其实就是aof+rdb 解决恢复速度问题
# 开启了混合持久化 AOF在重写时 不再是单纯将内存数据转换为RESP命令写入AOF文件 而是将重写这一刻之前的内存做RDB快照处理
# 配置参数:必须先开启AOF
# 开启 aof
appendonly yes
# 开启 aof复写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 开启 混合持久化
aof-use-rdb-preamble yes # 这正有用的是这句话
# 关闭 rdb
save ""
# aof重写可以使用配置文件触发,也可以手动触发:bgrewriteaof
2 主从复制原理和方案
# 为什么需要主从
可能会有以下问题:
1 机器故障
2 容量瓶颈
3 QPS瓶颈
# 主从解决了qps问题 机器故障问题
# 主从实现的功能
一主一从 一主多从
做读写分离
做数据副本
提供并发量
一个master可以有多个slave
一个slave只能有一个master
数据流向是单向的 从master到slave 从库只能读 不能写 主库既能读又能写
# redis主从赋值流程 原理
1 副本(从)库通过slaveof127.0.0.1 6379命令 连接主库 并发送SYNC给主库
2 主库收到SYNC 会立即触发BGSAVE 后台保存RDB 发送给副本库
3 副本库接收后会应用RDB快照 load进内存
4 主库会陆续将中间产生的新的操作 保存并发送给副本库
5 到此 我们的主复制集就正常工作了
6 再此以后 主库只要发生新的操作 都会以命令传播的形式自动发送给副本库
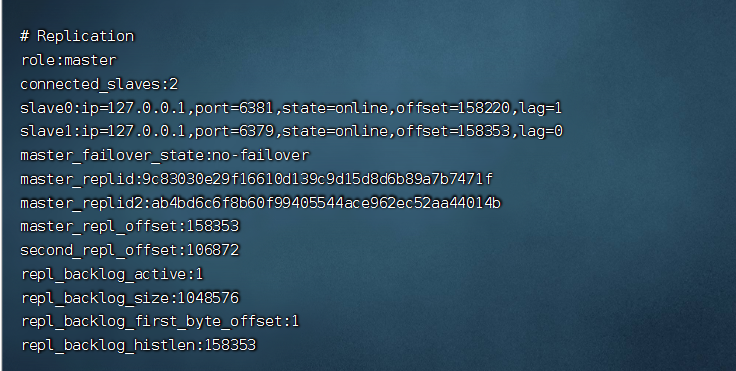
7 所有复制相关信息 从info信息中都可以查到 即使重启任何节点 他的主从关系依然都在
8 如果发生主从关系断开时 从库数据没有任何损坏 在下次重连之后 从库发送PSYNC给主库
9 主库之会将从库缺失部分的数据同步给从库应用 达到快速恢复主从的目的
# 主从同步主库是否要开启持久化?
如果不开有可能 主库重启操作 造成所有主从数据丢失
# 启动两台redis服务
# 主从复制启动两种方式
1 命令方式 在从库上执行
slaveof 127.0.0.1 6379 #异步
# 从库不能写了,以后只能用来读
slaveof no one # 从库:断开主从关系
2 配置文件方式,在从库加入
slaveof 127.0.0.1 6379 #配置从节点ip和端口
slave-read-only yes #从节点只读,因为可读可写,数据会乱
# 辅助配置(给主库用的)
min-slaves-to-write 1
min-slaves-max-lag 3
# 那么在从服务器的数量少于1个,或者三个从服务器的延迟(lag)值都大于或等于3秒时,主服务器将拒绝执行写命令
3 哨兵高可用
# 服务可用性高
# 主从复制不是高可用
# 主从存在问题
# 1 主从复制 主节点发生故障 需要做故障转移 可以手动转移:让其中一个slave变成master---> 哨兵自动做了这件事
# 2 主从复制 只能主写数据 所以写能力和存储能力有限---> 集群
# 哨兵:Sentinel 实现高可用
# 工作原理:
1 多个sentinel发现并确认master有问题
2 选举出一个sentinel作为领导
3 选取一个slave作为新的master
4 通知其余slave成为新的master的slave
5 通知客户端主从变化
6 等待老的master复活成为新的master的slave
# 高可用搭建步骤
第一步:先搭建一主两从
第二步:哨兵配置文件 启动哨兵(redis的进程 也要监听端口 启动进程有配置文件)
port 26379
daemonize yes
dir /root/redis/data
bind 0.0.0.0
logfile "redis_sentinel.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
port 26390
daemonize yes
dir /root/redis/data1
bind 0.0.0.0
logfile "redis_sentinel.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
port 26381
daemonize yes
dir /root/redis/data2
bind 0.0.0.0
logfile "redis_sentinel.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
第三步:启动三个哨兵
./src/redis-sentinel ./sentinal_26379.conf
./src/redis-sentinel ./sentinal_26380.conf
./src/redis-sentinel ./sentinal_26381.conf
第四步:停止主库,发现80变成了主库,以后79启动,变成了从库
4 集群原理及搭建
# 做了读写分离 做了高可用 还存在问题
1 并发量:单机redis qps为10w/s 但是我们可能需要百万级别的并发量
2 数据量:机器内存16g--256g 如果存500g数据呢?
# 使用集群解决这个问题
# 解决:加机器 分布式 redis cluster 在2015年的3.0版本加入了 满足分布式的需求
# 数据库的多机数据分步方案
存在问题:
假设全量的数据非常大 500G 单机已经无法满足 我们需要进行分区 分到若干个子集中
# 主流分区方式(数据分片方式)
哈希分布
顺序分步
# 顺序分步
原理:100个数据分到3个节点上 1--33第一个节点;34--66第二个节点;67--100第三个节点(很多关系型数据库使用此种方式)
# 哈希分区
原理:hash分区;节点取余 假设3台机器 hash(key)%3 落到不同节点上
# 节点取余分区:扩容缩容麻烦---需要移动数据---> 建议翻倍扩容---只需要移动一半的数据
# 总结:
客户端分片 通过hash+取余
节点伸缩 数据节点关系发生变化 导致影响数据迁移过大
迁移数量和添加节点数量有关:建议翻倍扩容
# 一致性哈希分区
每个节点负责一部分数据 对key进行hash 得到结果在node1和node2之间 就放到node2中 顺时针查找
# 总结:
客户端分片:哈希+顺时针(优化取余)
节点伸缩:只影响临近节点 但是还有数据迁移的情况
伸缩:保证最小迁移数据和无法保证负载均衡(这样总共5个节点 数据就不均匀了) 翻倍扩容可以实现负载均衡
# 虚拟槽(redis)
预设虚拟槽:每个槽映射一个数据子集 一般比节点数大
良好的哈希函数:如CRC16
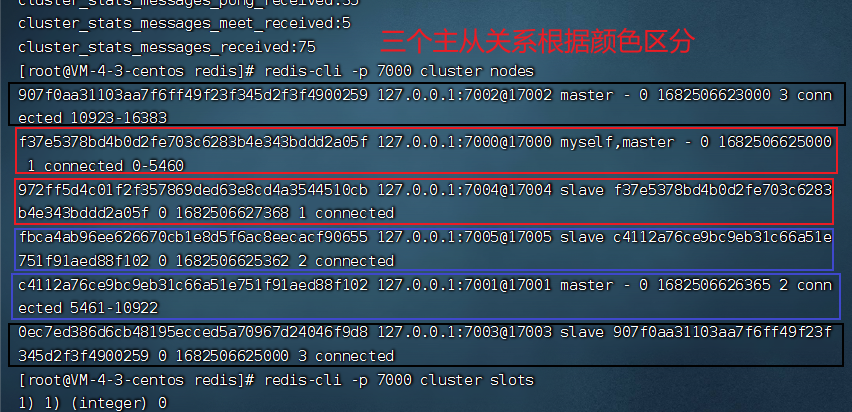
服务端管理节点,槽,数据:如redis cluster(槽的范围0-16383)
# redis使用了虚拟槽
对key进行hash得到数字对16383取余---> 就知道这个数据是归哪个槽管理的---> 节点管理哪些槽是知道的---> 数据存到哪个节点就知道了
4.1 集群搭建
# 名词解释
节点(某一台机器) meet(节点跟节点之间通过meet通信) 指派槽(16383个槽分给几个节点) 复制(主从复制) 高可用(主节点挂掉 从节点顶上)
# 搭建步骤:准备6台机器(6个redis-server进程)
# 第一步:准备6台机器 写6个配置文件---> 如果之前配置过先把文件删除
port 7000
daemonize yes
dir "/root/redis/data/"
logfile "7000.log"
cluster-enabled yes
cluster-node-timeout 15000
cluster-config-file nodes-7000.conf
cluster-require-full-coverage yes
#第二步:快速复制6个配置问题,并修改配置
快速生成其他配置
sed 's/7000/7001/g' redis-7000.conf > redis-7001.conf
sed 's/7000/7002/g' redis-7000.conf > redis-7002.conf
sed 's/7000/7003/g' redis-7000.conf > redis-7003.conf
sed 's/7000/7004/g' redis-7000.conf > redis-7004.conf
sed 's/7000/7005/g' redis-7000.conf > redis-7005.conf
#第三步:启动6个redis服务
./src/redis-server ./redis-7000.conf
./src/redis-server ./redis-7001.conf
./src/redis-server ./redis-7002.conf
./src/redis-server ./redis-7003.conf
./src/redis-server ./redis-7004.conf
./src/redis-server ./redis-7005.conf
ps -ef |grep redis
# 第四步:
./src/redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
# 第五步:
redis-cli -p 7000 cluster info
redis-cli -p 7000 cluster nodes
redis-cli -p 7000 cluster slots # 查看槽的信息
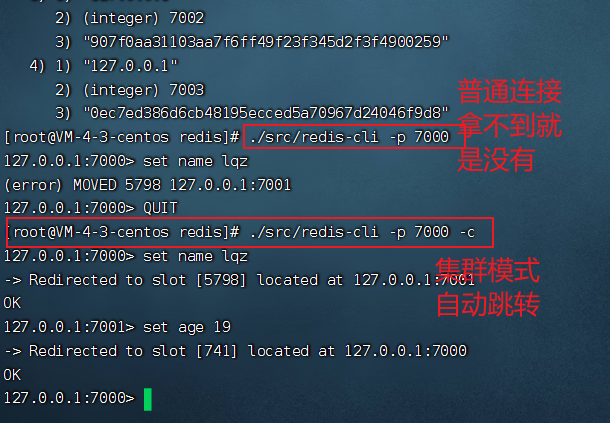
# 第六步:测试存储数据
./src/redis-cli -p 7000 -c # -c集群模式
4.2 集群扩容
# 1 准备两台机器
sed 's/7000/7006/g' redis-7000.conf > redis-7006.conf
sed 's/7000/7007/g' redis-7000.conf > redis-7007.conf
# 2 启动两台机器
./src/redis-server ./redis-7006.conf
./src/redis-server ./redis-7007.conf
# 3 两台机器加入到集群中去
./src/redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000
./src/redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7000
# 4 让7007复制7006
./src/redis-cli -p 7007 cluster replicate baf261f2e6cb2b0359d25420b3ddc3d1b8d3bb5a
# 5 迁移槽
./src/redis-cli --cluster reshard 127.0.0.1:7000
迁移4096个槽
7006的机器接收槽
all
yes
4.3 集群缩容
# 第一步:下线迁槽(把7006的1366个槽迁移到7000上)
redis-cli --cluster reshard --cluster-from baf261f2e6cb2b0359d25420b3ddc3d1b8d3bb5a --cluster-to 050bfd3608514d4db5d2ce5411ef5989bbe50867 --cluster-slots 1365 127.0.0.1:7000
yes
redis-cli --cluster reshard --cluster-from baf261f2e6cb2b0359d25420b3ddc3d1b8d3bb5a --cluster-to 9cb2a9b8c2e7b63347a9787896803c0954e65b40 --cluster-slots 1366 127.0.0.1:7001
yes
redis-cli --cluster reshard --cluster-from baf261f2e6cb2b0359d25420b3ddc3d1b8d3bb5a --cluster-to d3aea3d0b4cf90f58252cf3bcd89530943f52d36 --cluster-slots 1366 127.0.0.1:7002
yes
#第二步:下线节点 忘记节点,关闭节点
./src/redis-cli --cluster del-node 127.0.0.1:7000 9c2abbfaa4d1fb94b74df04ce2b481512e6edbf3 # 先下从,再下主,因为先下主会触发故障转移
./src/redis-cli --cluster del-node 127.0.0.1:7000 baf261f2e6cb2b0359d25420b3ddc3d1b8d3bb5a
# 第三步:关掉其中一个主,另一个从立马变成主顶上, 重启停止的主,发现变成了从
'''例如7是从 先下线7 再下线6'''
5 缓存优化
5.1 redis缓存更新策略
# redis本身 内存存储 会出现内存不够用 放数据放不进去 有些策略 删除一部分数据 再放新的
# LRU/LFU/FIFO算法剔除:例如maxmemory-policy(到了最大内存 对应的应对策略)
LRU -Least Recently Used 没有被使用时间最长的
LFU -Least Frequenty Used 一定时间段内使用次数最少的
FIFO -First In First Out 先进先出
5.2 缓存穿透 击穿 雪崩
### 缓存穿透
# 描述:
缓存穿透是指缓存和数据库中都没有的数据 而用户不断发起请求 如发起id为'-1'的数据或id为特别大不存在的数据。这时的用户很可能是攻击者 攻击会导致数据库压力过大。
# 解决方案:
1 接口层增加校验 如用户校验权限 id基础校验(id不符合规范的直接拦截) 频率校验
2 从缓存取不到的数据 在数据库中也没有取到 这时也可以将key-value对写为key-null然后写入缓存 缓存有效时间可以设置短点(设置太长会导致正常情况也没法使用)。这样就可以防止攻击用户反复使用同一个id暴力攻击
3 通过布隆过滤器实现
### 缓存击穿
# 描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期) 这时由于并发用户特别多 同时读缓存没读到数据 又同时去数据库中取数据 引起数据库压力瞬间增大 造成过大压力
# 解决方案:
设置热点数据永不过期
### 缓存雪崩
# 描述:
缓存雪崩是指缓存中大批量到期时间 而查询数据量巨大 引起数据库压力过大甚至down机。和缓存击穿不同的是---> 缓存击穿指并发查同一条数据 缓存雪崩是不同数据都过期了 很多数据都查不到从而查数据库
# 解决方案:
1 缓存数据的过期时间设置随机 防止同一时间大量数据过期现象发生
2 如果缓存数据库是分布式部署 将热点数据均匀分布在不同的缓存数据库中
3 设置热点数据永不过期

