selenium登录cnblogs-抽屉半自动点赞-xpath的使用-selenium动作链-自动登录12306-打码平台使用-使用打码平台自动登录-使用selenium爬取jd商品信息-scrapy介绍
目录
selenium登录cnblogs-抽屉半自动点赞-xpath的使用-selenium动作链-自动登录12306-打码平台使用-使用打码平台自动登录-使用selenium爬取jd商品信息-scrapy介绍
昨日回顾
# 1 beautifulsoup4 使用
xml解析库 用它来解析爬回来的html内容 从中找出我们需要的内容
# 2 遍历文档树
. 的使用 soup.html.body.p.a
获取属性 对象.attrs.get('href')
获取文本 对象.text string strings
子节点 父节点 兄弟节点获取
# 3 搜索文档树
find find_all
5种过滤器:字符串 正则表达式 列表 布尔 方法
find(name='a',calss_='sister',href='sss',text='sss',attrs={'class':'xxx'}) # 字符串形式
find(name=re.combine('^b'),class_=re.combine('^sister')) # 正则形式
find(name=[b,body]) # 列表
find(id=True) # 布尔
# 4 find 其他参数
limit 限制查找的条数
recursive:默认递归 子子孙孙都会找 设为False只会找下一层 找不到为空
# 5 css选择器
#
.
div
div a
div>a
终极大招
soup.select('#xx')
# 6 selenium 快速使用
自动化测试 用来做爬虫 解决requests模块无法直接执行js的问题
安装:pip install selenium
下载驱动:建议使用谷歌浏览器---> 下载驱动要跟谷歌浏览器版本对应
使用python代码 操作浏览器
# 7 查找标签
find_element
find_elements
by参数 有很多
按id查找
按a标签文字内容
按a标签文字内容模糊匹配
按标签 tag_name
按类名
按css选择器
按xpath
# 8 操作标签
写文字
清除文字
点击
窗口放到最大
截图
# 9 执行js
excute_srcipt
# 10 打开标签 切换到某个打开的标签 滑动屏幕
# 11 等待元素加载
# 12 模拟浏览器的前进后退
# 13 获取cookie(重要)
# 14 异常捕获
今日内容详细
0 selenium登录cnblogs
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
try:
# 1 获取cookie
# bro.get('https://www.cnblogs.com/')
# bro.implicitly_wait(10)
# login_btn = bro.find_element(by=By.LINK_TEXT, value='登录')
# login_btn.click()
# username = bro.find_element(By.ID, 'mat-input-0')
# password = bro.find_element(By.ID, 'mat-input-1')
# submit_btn = bro.find_element(By.CSS_SELECTOR, 'body > app-root > app-sign-in-layout > div > div > app-sign-in > app-content-container > div > div > div > form > div > button')
# username.send_keys('账号')
# password.send_keys('密码')
# 点击登录
# submit_btn.click()
# time.sleep(3)
# cookie = bro.get_cookies()
# print(cookie)
# # 保存到本地文件
# with open('cnblogs.json', 'w', encoding='utf-8') as f:
# json.dump(cookie, f)
# 2 利用获取到的cookie打开首页
bro.get('https://www.cnblogs.com/') # 没有登录状态
bro.implicitly_wait(20)
time.sleep(2)
# 打开本地的cookie的json文件
with open('cnblogs.json', 'r', encoding='utf-8') as f:
cookies = json.load(f)
for cookie in cookies:
bro.add_cookie(cookie)
bro.refresh() # 刷新页面
time.sleep(5)
except Exception as e:
print(e)
finally:
bro.close()

1 抽屉半自动点赞
# 1 使用selenium 半自动登录---> 取到cookie
# 2 使用requests模块 解析出点赞的请求地址---> 模拟发送请求---> 携带cookie
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
try:
# 1 获取cookie
# bro.get('https://www.cnblogs.com/')
# bro.implicitly_wait(10)
# login_btn = bro.find_element(by=By.LINK_TEXT, value='登录')
# login_btn.click()
# username = bro.find_element(By.ID, 'mat-input-0')
# password = bro.find_element(By.ID, 'mat-input-1')
# submit_btn = bro.find_element(By.CSS_SELECTOR, 'body > app-root > app-sign-in-layout > div > div > app-sign-in > app-content-container > div > div > div > form > div > button')
# username.send_keys('账号')
# password.send_keys('密码')
# submit_btn.click()
# time.sleep(3)
# cookie = bro.get_cookies()
# print(cookie)
# # 保存到本地文件
# with open('cnblogs.json', 'w', encoding='utf-8') as f:
# json.dump(cookie, f)
# 2 利用获取到的cookie打开首页
bro.get('https://www.cnblogs.com/') # 没有登录状态
bro.implicitly_wait(20)
time.sleep(2)
# 打开本地的cookie的json文件
with open('cnblogs.json', 'r', encoding='utf-8') as f:
cookies = json.load(f)
for cookie in cookies:
bro.add_cookie(cookie)
bro.refresh() # 刷新页面
time.sleep(5)
except Exception as e:
print(e)
finally:
bro.close()
2 xpath的使用
# 每个解析器 都会有自己的查找方法
bs4 find和find_all
selenium find_element和find_elements
lxml 也是个解析器 支持xpath和css
# 这些解析器 基本上都会支持两种统一的 css 和 xpath
css前面学过
xpath学习中
# xpath是什么?
XPath几位XML路径语言(XML Path Language) 它是一种用来确定XML文档中 某部分位置的语言
# 有终极大招 只需要记住鸡哥用法即可
/ 从当前路径下开始找
/div 从当前路径下开始找div
// 递归查找 子子孙孙
//div 递归查找div
@ 取属性
. 当层
.. 上一层
# 练习参考
doc = '''
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg'/></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html' class='li li-item' name='items'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
<a href='image6.html' name='items'><span><h5>test</h5></span>Name: My image 6 <br /><img src='image6_thumb.jpg' /></a>
</div>
</body>
</html>
'''
from lxml import etree
# html = etree.HTML(doc)
# html=etree.parse('search.html',etree.HTMLParser())
# 1 所有节点
# a=html.xpath('//*')
# 2 指定节点(结果为列表)
# a=html.xpath('//head')
# 3 子节点,子孙节点
# a=html.xpath('//div/a')
# a=html.xpath('//body/a') #无数据
# a = html.xpath('//body//a')
# 4 父节点
# a=html.xpath('/html/body')
# a=html.xpath('//body//a[@href="image1.html"]/..') # 属性a[@href="image1.html"] .. 表示上一层
# a=html.xpath('//body//a[1]/..') # 从1 开始的
# 也可以这样
# a=html.xpath('//body//a[1]/parent::*')
# a=html.xpath('//body//a[1]/parent::p')
# a=html.xpath('//body//a[1]/parent::div')
# 5 属性匹配
# a=html.xpath('//body//a[@href="image1.html"]')
# 6 文本获取 /text()
# a=html.xpath('//body//a[@href="image1.html"]/text()')
# 7 属性获取
# a=html.xpath('//body//a/@href')
# # 注意从1 开始取(不是从0)
# a=html.xpath('//body//a[1]/@href')
# 8 属性多值匹配
# a 标签有多个class类,直接匹配就不可以了,需要用contains
# a=html.xpath('//body//a[@class="li"]') # 这个取不到
# a=html.xpath('//body//a[contains(@class,"li")]')
# a=html.xpath('//body//a[contains(@class,"li")]/text()')
# 9 多属性匹配
# a=html.xpath('//body//a[contains(@class,"li") or @name="items"]')
# a=html.xpath('//body//a[contains(@class,"li") and @name="items"]/text()')
# 10 按序选择
# a=html.xpath('//a[2]/text()')
# a=html.xpath('//a[2]/@href')
# 取最后一个
# a=html.xpath('//a[last()]/@href')
# 位置小于3的
# a=html.xpath('//a[position()<3]/@href')
# 倒数第二个
# a=html.xpath('//a[last()-2]/@href')
# 11 节点轴选择
# ancestor:祖先节点
# 使用了* 获取所有祖先节点
# a=html.xpath('//a/ancestor::*')
# # 获取祖先节点中的div
# a=html.xpath('//a/ancestor::div')
# attribute:属性值
# a=html.xpath('//a[1]/attribute::*')
# child:直接子节点
# a=html.xpath('//a[1]/child::*')
# descendant:所有子孙节点
# a=html.xpath('//a[6]/descendant::*')
# following:当前节点之后所有节点
# a=html.xpath('//a[1]/following::*')
# a=html.xpath('//a[1]/following::*[1]/@href')
# following-sibling:当前节点之后同级节点
# a=html.xpath('//a[1]/following-sibling::*')
# a=html.xpath('//a[1]/following-sibling::a')
# a=html.xpath('//a[1]/following-sibling::*[2]')
# a=html.xpath('//a[1]/following-sibling::*[2]/@href')
# print(a)
import requests
res=requests.get('https://www.runoob.com/xpath/xpath-syntax.html')
# print(res.text)
html = etree.HTML(res.text)
a=html.xpath('//*[@id="content"]/h2[2]/text()')
print(a)
3 selenium动作链
# 人可以滑动某些标签
# 网站有些按住鼠标 滑动的效果
滑动验证码
# 两种形式
方式一: # 直接一步到位 需要知道目标位置
actions=ActionChains(bro) # 拿到动作链对象
actions.drag_and_arop(sourse, target) # 把动作链放到动作链中 准备串行执行
actions.perform()
方式二: # 一点一点的位移 直到到达目标位置
ActionChains(bro).click_and_hold(sourse).perform()
distance=target.location['x']-sourse.location['x']
traack=0
while tarck < distance:
ActionChains(bro).move_by_offset(xoffset=2, yoffset=0).perform()
track+=2
3.1 动作链案例
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By # 按什么方式查找 By.ID By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
import time
browser = webdriver.Chrome(executable_path='./chromedriver.exe')
try:
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframeResult') # 切换到id为iframeResult的frame
target = browser.find_element(By.ID, 'droppable') # 目标
sourse = browser.find_element(By.ID, 'draggable') # 源
# 方案一
# actions = ActionChains(browser) # 拿到动作链对象
# actions.drag_and_drop(sourse, target) # 把动作放到动作链中,准备串行执行
# actions.perform()
# time.sleep(2)
# 方案二
ActionChains(browser).click_and_hold(sourse).perform()
distance=target.location['x']-sourse.location['x']
track=0
while track < distance:
ActionChains(browser).move_by_offset(xoffset=2,yoffset=0).perform()
track+=2
except Exception as e:
print(e)
finally:
browser.close()
4 自动登录12306
# selenium自动登录12306
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled") # 去掉自动化控制
browser = webdriver.Chrome(executable_path='./chromedriver.exe', chrome_options=options)
try:
browser.get('https://kyfw.12306.cn/otn/resources/login.html')
browser.maximize_window()
username = browser.find_element(By.ID, 'J-userName')
password = browser.find_element(By.ID, 'J-password')
username.send_keys('账号')
password.send_keys('密码')
login_btn = browser.find_element(By.ID, 'J-login')
time.sleep(2)
login_btn.click()
time.sleep(3)
# 拿到滑动验证码的span 完成验证
span = browser.find_element(By.ID, 'nc_1_n1z')
ActionChains(browser).click_and_hold(span).perform()
ActionChains(browser).move_by_offset(xoffset=300, yoffset=0).perform()
# 滑动完成了 但是进不去 原因是检测到使用selenium 去掉自动化控制即可
time.sleep(3)
finally:
browser.close()
5 打码平台使用
# 登录网站 会有些验证码 可以借助于第三方的打码平台 破解验证码 只需要花钱解决
# 有免费的:可以破解纯数字 纯字母的---> python有免费模块破解 失败率有
# 第三方平台:云打码 超级鹰
# 云打码:https://zhuce.jfbym.com/price/
# 价格体系:破解什么验证码 需要多少钱
http://www.chaojiying.com/price.html
6 使用打码平台自动登录
# 使用步骤 先去下载python需要的文件---> http://www.chaojiying.com/api-14.html
# 解压后导入文件路径
# 使用selenium打开页面---> 截取整个屏幕---> 使用pillow---> 根据验证码图片位置 截取出验证码图片---> 使用第三方打码平台破解---> 写入到验证码框中 点击登录
# 使用selenium打开页面---》截取整个屏幕----》使用pillow---》根据验证码图片位置,截取出验证码图片---》使用第三方打码平台破解---》写入到验证码框中,点击登录
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from chaojiying import Chaojiying_Client
from PIL import Image
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
bro.get('http://www.chaojiying.com/apiuser/login/')
bro.implicitly_wait(10)
bro.maximize_window()
try:
username = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input')
password = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input')
code = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input')
btn = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input')
username.send_keys('306334678')
password.send_keys('lqz123')
# 获取验证码:
#1 整个页面截图
bro.save_screenshot('main.png')
# 2 使用pillow,从整个页面中截取出验证码图片 code.png
img = bro.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/div/img')
location = img.location
size = img.size
print(location)
print(size)
# 使用pillow扣除大图中的验证码
img_tu = (int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height']))
# # 抠出验证码
# #打开
img = Image.open('./main.png')
# 抠图
fram = img.crop(img_tu)
# 截出来的小图
fram.save('code.png')
# 3 使用超级鹰破解
chaojiying = Chaojiying_Client('账号', '密码', '软件ID') # 用户中心>>软件ID 生成一个替换 96001
im = open('code.png', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
res_code=chaojiying.PostPic(im, 1902)['pic_str']
code.send_keys(res_code)
time.sleep(5)
btn.click()
time.sleep(10)
except Exception as e:
print(e)
finally:
bro.close()
'''
使用不成功 没有题分
'''
7 使用selenium爬取jd商品信息
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 键盘按键操作
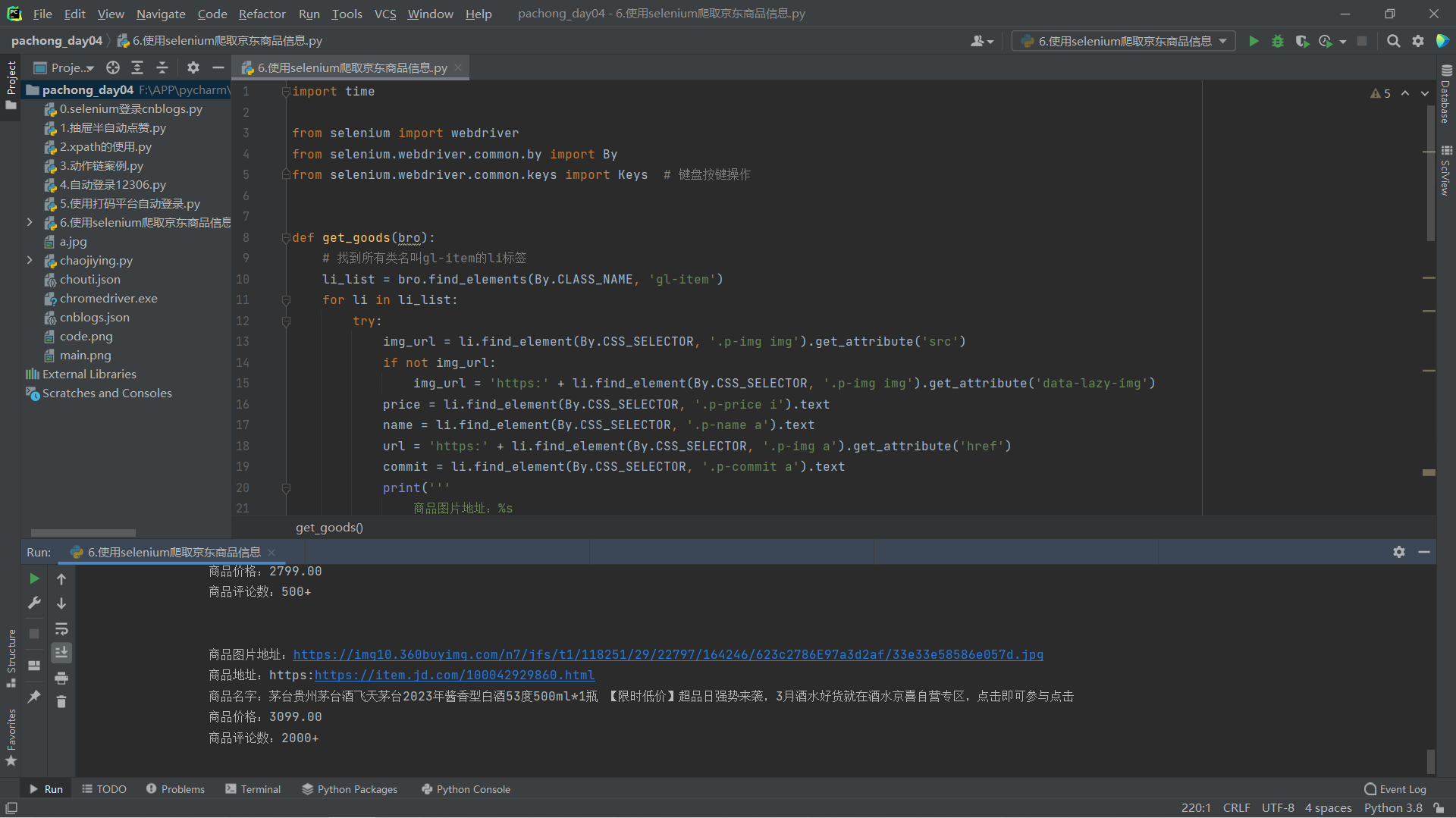
def get_goods(bro):
# 找到所有类名叫gl-item 的li标签
li_list = bro.find_elements(By.CLASS_NAME, 'gl-item')
for li in li_list:
try:
img_url = li.find_element(By.CSS_SELECTOR, '.p-img img').get_attribute('src')
if not img_url:
img_url = 'https:' + li.find_element(By.CSS_SELECTOR, '.p-img img').get_attribute('data-lazy-img')
price = li.find_element(By.CSS_SELECTOR, '.p-price i').text
name = li.find_element(By.CSS_SELECTOR, '.p-name a').text
url = 'https:' + li.find_element(By.CSS_SELECTOR, '.p-img a').get_attribute('href')
commit = li.find_element(By.CSS_SELECTOR, '.p-commit a').text
print('''
商品图片地址:%s
商品地址:%s
商品名字:%s
商品价格:%s
商品评论数:%s
''' % (img_url, url, name, price, commit))
except Exception as e:
print(e)
continue
# 查找下一页,点击,在执行get_goods
next = bro.find_element(By.PARTIAL_LINK_TEXT, '下一页')
time.sleep(1)
next.click()
get_goods(bro)
try:
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
bro.get('http://www.jd.com')
bro.implicitly_wait(10)
input_key = bro.find_element(By.ID, 'key')
input_key.send_keys('茅台')
input_key.send_keys(Keys.ENTER) # 敲回车
# 滑动屏幕到最底部
bro.execute_script('scrollTo(0,5000)')
get_goods(bro)
except Exception as e:
print('sasdfsadfasdfa',e)
finally:
bro.close()
8 scrapy介绍
# requests bs4 selenium 模块
# 框架:django scrapy ---> 专门做爬虫的框架 爬虫界的django 大而全 爬虫有的东西 他都自带
# 安装 (win看人品 linux mac一点问题都没有)
pip3.8 install scrapy
装不上 基本上是因为twisted装不了 单独装
1.pip3 install wheel # 安装后 便支持通过wheel文件安装软件 wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
2.pip3 install lxml
3.pip3 install pyopenssl
4.下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
5.下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
6.执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
7.pip3 install scrapy
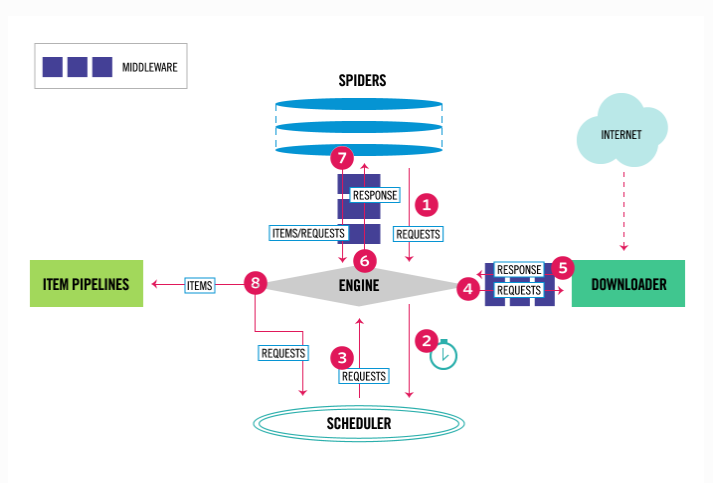
# 架构分析
爬虫:spiders(自己定义的 可以有很多) 定义爬取的地址 解析规则
引擎:engine---> 控制整个框架数据的流动 大总管
调度器:scheduler---> 要爬取的requests对象 放在里面 排队
下载中间件:DownloadMiddleware---> 处理请求对象 处理响应对象
下载器:Downloader---> 负责真正的下载 效率很高 基于twisted的高并发的模型之上
爬虫中间件:spiderMiddleware---> 处于engine和爬虫之间的(用得少)
管道:piplines---> 负责存储数据
# 创建出scrapy项目
scrapy startproject firstscrapy # 创建项目
scrapy genspider 名字 网址 # 创建爬虫 等同于创建app
# pycharm打开