

黏包现象,UPD基本代码使用,并发编程理论之操作系统发展史,多道技术,进程理论及调度算法
目录
黏包现象,UPD基本代码使用,并发编程理论之操作系统发展史,多道技术,进程理论及调度算法
今日内容概要
- 黏包现象
- 解决黏包逻辑思路
- 代码实操
- UPD基本代码使用
- 并发编程理论之操作系统发展史
- 多道技术
- 进程理论及调度算法
今日内容详细
黏包现象
1.服务端连续执行三次recv
2.客户端连续执行三次send
问题:服务端一次性接收到了客户端三次的消息 该现象称为'黏包现象'
黏包现象产生的原因
1.不知道每次的数据到底多大
2.TCP也称为流式协议:数据像水流一样绵绵不绝没有间隔(TCP会针对数据量较小且发送间隔较短的多条数据一次性合并打包发送)
避免黏包现象的核心思路/关键点
如何明确即将接收的数据具体有多大
ps:如何将长度变化的数据全部制作成固定长度的数据
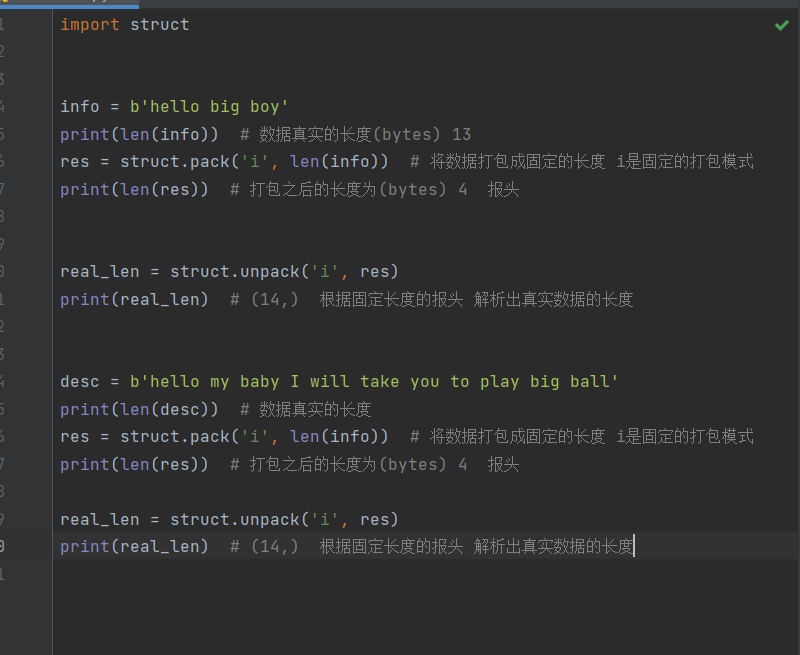
struct模块
import struct
info = b'hello big boy'
print(len(info)) # 数据真实的长度(bytes) 13
res = struct.pack('i', len(info)) # 将数据打包成固定的长度 i是固定的打包模式
print(len(res)) # 打包之后的长度为(bytes) 4 报头
real_len = struct.unpack('i', res)
print(real_len) # (14,) 根据固定长度的报头 解析出真实数据的长度
desc = b'hello my baby I will take you to play big ball'
print(len(desc)) # 数据真实的长度
res = struct.pack('i', len(info)) # 将数据打包成固定的长度 i是固定的打包模式
print(len(res)) # 打包之后的长度为(bytes) 4 报头
real_len = struct.unpack('i', res)
print(real_len) # (46,) 根据固定长度的报头 解析出真实数据的长度
"""
解决黏包问题初次版本
客户端
1.将真实数据转成bytes类型并计算长度
2.利用struct模块将真实长度制作一个固定长度的报头
3.将固定长度的报头先发送给服务端 服务端只需要在recv括号内填写固定长度的报头数字即可
4.然后再发送真实数据
服务端
1.服务端先接收固定长度的报头
2.利用struct模块反向解析出真实数据长度
3.recv接收真实数据长度即可
"""
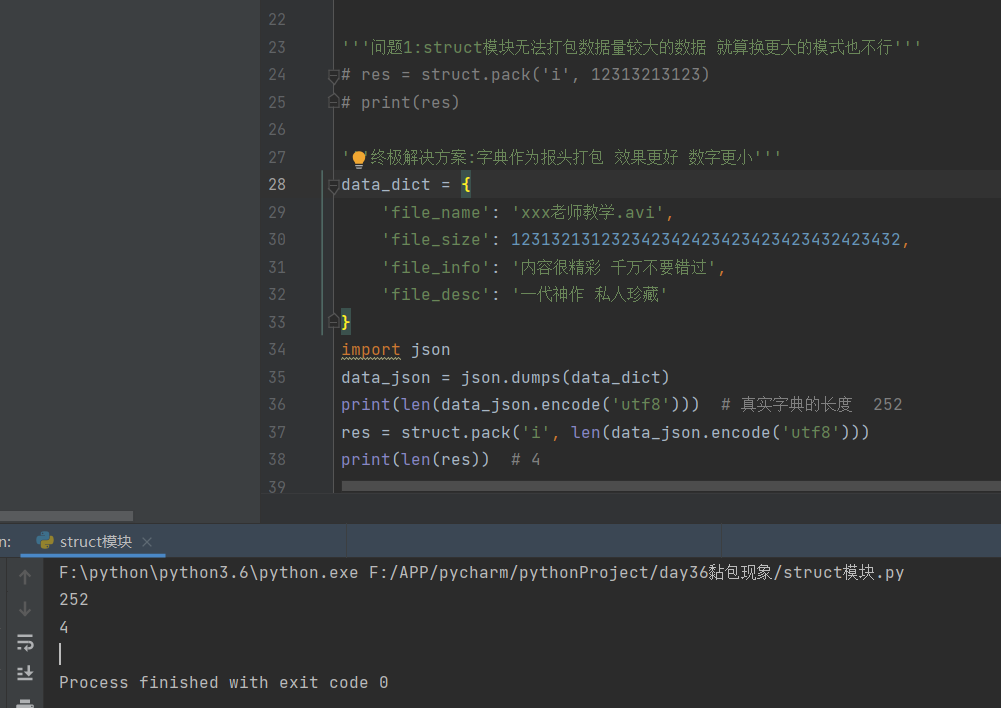
'''问题1:struct模块无法打包数据量较大的数据 就算换更大的模式也不行'''
# res = struct.pack('i', 12313213123)
# print(res)
'''终极解决方案:字典作为报头打包 效果更好 数字更小'''
data_dict = {
'file_name': 'xxx老师教学.avi',
'file_size': 123132131232342342423423423423432423432,
'file_info': '内容很精彩 千万不要错过',
'file_desc': '一代神作 私人珍藏'
}
import json
data_json = json.dumps(data_dict)
print(len(data_json.encode('utf8'))) # 真实字典的长度 252
res = struct.pack('i', len(data_json.encode('utf8')))
print(len(res)) # 4
"""
黏包问题终极方案
客户端
1.制作真实数据的信息字典(数据长度、数据简介、数据名称)
2.利用struct模块制作字典的报头
3.发送固定长度的报头(解析出来是字典的长度)
4.发送字典数据
5.发送真实数据
服务端
1.接收固定长度的字典报头
2.解析出字典的长度并接收
3.通过字典获取到真实数据的各项信息
4.接收真实数据长度
"""
黏包代码实战
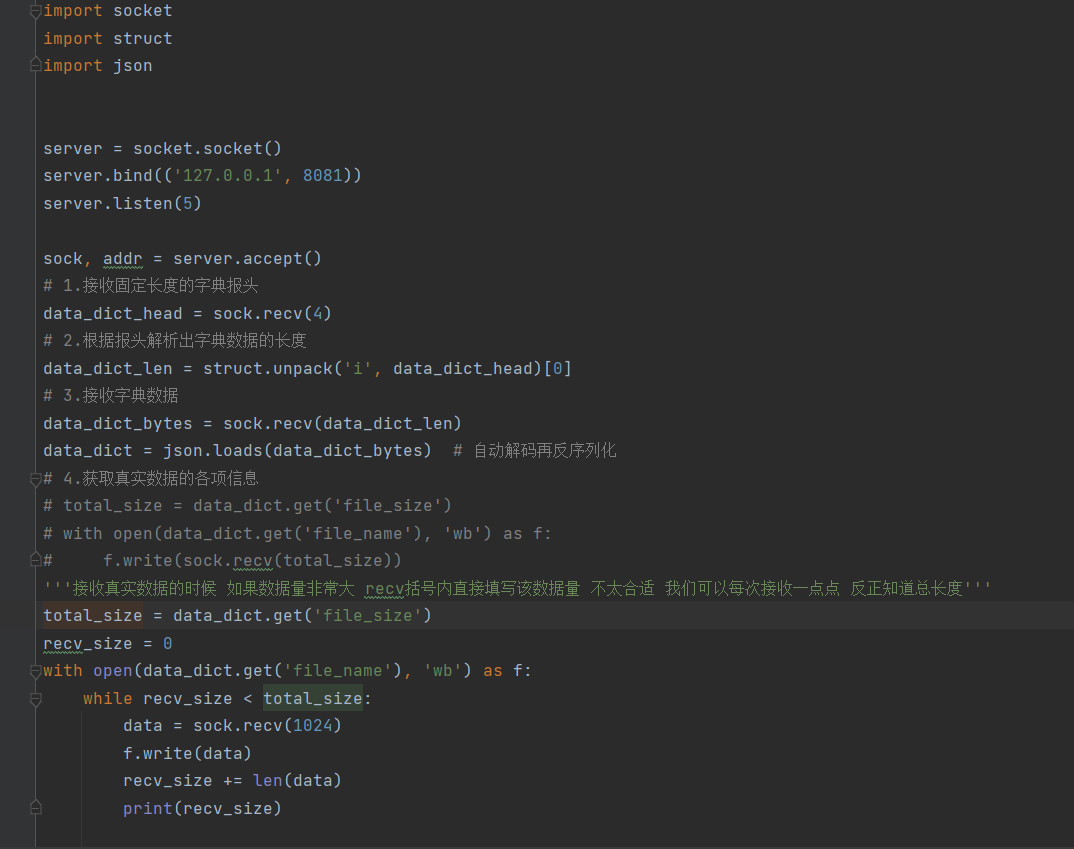
# 服务端
import socket
import struct
import json
server = socket.socket()
server.bind(('127.0.0.1', 8081))
server.listen(5)
sock, addr = server.accept()
# 1.接收固定长度的字典报头
data_dict_head = sock.recv(4)
# 2.根据报头解析出字典数据的长度
data_dict_len = struct.unpack('i', data_dict_head)[0]
# 3.接收字典数据
data_dict_bytes = sock.recv(data_dict_len)
data_dict = json.loads(data_dict_bytes) # 自动解码再反序列化
# 4.获取真实数据的各项信息
# total_size = data_dict.get('file_size')
# with open(data_dict.get('file_name'), 'wb') as f:
# f.write(sock.recv(total_size))
'''接收真实数据的时候 如果数据量非常大 recv括号内直接填写该数据量 不太合适 我们可以每次接收一点点 反正知道总长度'''
total_size = data_dict.get('file_size')
recv_size = 0
with open(data_dict.get('file_name'), 'wb') as f:
while recv_size < total_size:
data = sock.recv(1024)
f.write(data)
recv_size += len(data)
print(recv_size)
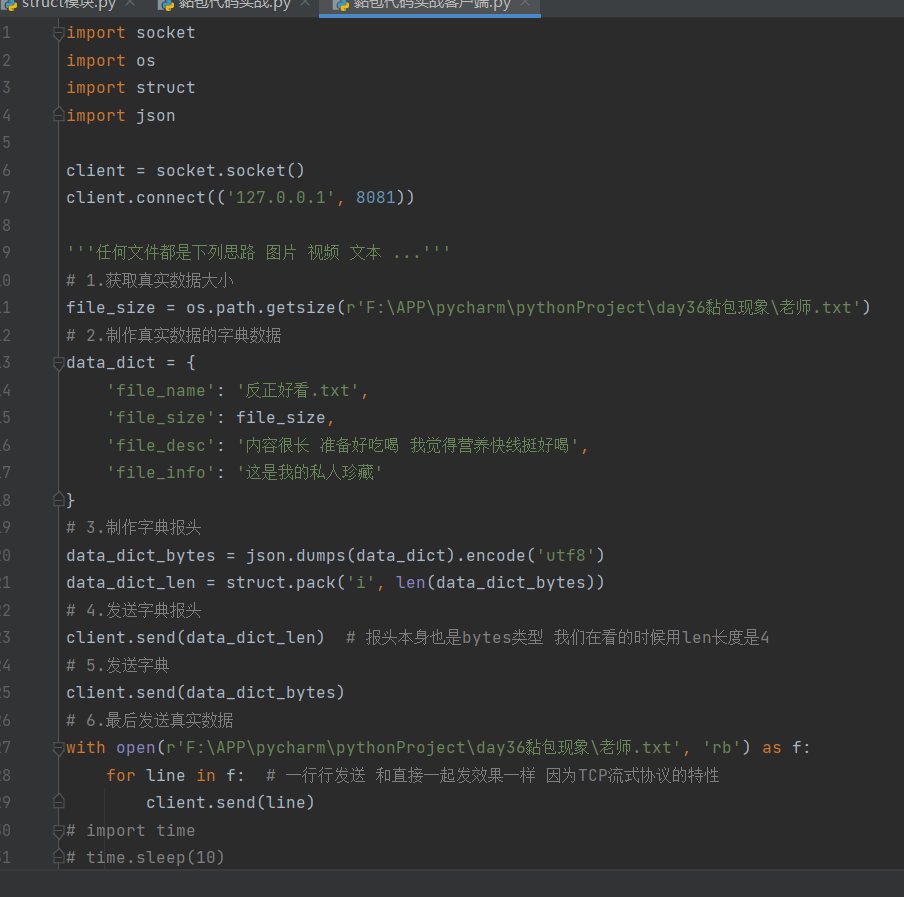
# 客户端
client.connect(('127.0.0.1', 8081))
'''任何文件都是下列思路 图片 视频 文本 ...'''
# 1.获取真实数据大小
file_size = os.path.getsize(r'F:\APP\pycharm\pythonProject\day36黏包现象\老师.txt')
# 2.制作真实数据的字典数据
data_dict = {
'file_name': '反正好看.txt',
'file_size': file_size,
'file_desc': '内容很长 准备好吃喝 我觉得营养快线挺好喝',
'file_info': '这是我的私人珍藏'
}
# 3.制作字典报头
data_dict_bytes = json.dumps(data_dict).encode('utf8')
data_dict_len = struct.pack('i', len(data_dict_bytes))
# 4.发送字典报头
client.send(data_dict_len) # 报头本身也是bytes类型 我们在看的时候用len长度是4
# 5.发送字典
client.send(data_dict_bytes)
# 6.最后发送真实数据
with open(r'F:\APP\pycharm\pythonProject\day36黏包现象\老师.txt', 'rb') as f:
for line in f: # 一行行发送 和直接一起发效果一样 因为TCP流式协议的特性
client.send(line)
# import time
# time.sleep(10)
UDP协议
1.UDP服务端和客户端'各自玩各自的'
2.UDP不会出现多个消息发送合并
并发编程理论
理论非常多 实战很少 但是一定要好好听
研究网络编程其实就是在研究计算机的底层原理及发展史
"""
计算机中真正干活的是CPU
"""
操作系统发展史
1.穿孔卡片阶段
计算机很庞大 使用很麻烦 一次只能给一个人使用 期间很多时候计算机都不工作
好处:程序员独占计算机 为所欲为
坏处:计算机利用率太低 浪费资源
2.联机批处理系统
提前使用磁带一次性录入多个程序员编写的程序 然后交给计算机执行
CPU工作效率有所提升 不用反复等待程序录入
3.脱机批处理系统
极大地提升了CPU的利用率
总结:CPU提升利用率的过程
多道技术
"""
在学习并发编程的过程中 不做刻意提醒的情况下 默认一台计算机就一个CPU(只有一个干活的人)
"""
单道技术
所有的程序排队执行 过程中不能重合
多道技术
利用空闲时间提前准备其他数据 最大化提升CPU利用率
多道技术详细
1.切换
计算机的CPU在两种情况下会切换(不让你用 给别人用)
1.程序有IO操作
输入\输出操作
input、time.sleep、read、write
2.程序长时间占用CPU
我们得雨露均沾 让多个程序都能被CPU运行一下
2.保存状态
CPU每次切换走之前都需要保存当前操作的状态 下次切换回来基于上次的进度继续执行
"""
开了一家饭店 只有一个服务员 但是同时来了五桌客人
请问:如何让五桌客人都感觉到服务员在服务他们
让服务员化身为闪电侠 只要客人有停顿 就立刻切换到其他桌 如此往复
"""
进程理论
进程与程序的区别
程序:一堆死代码(还没有被运行起来)
进程:正在运行的程序(被运行起来了)
进程的调度算法(重要)
1.FCFS(先来先服务)
对短作业不友好
2.短作业优先调度
对长作业不友好
3.时间片轮转法+多级反馈队列(目前还在用)
将时间均分 然后根据进程时间长短再分多个等级
等级越靠下表示耗时越长 每次分到的时间越多 但是优先级越低
进程的并行与并发
并行
多个进程同时执行 必须要有多个CPU参与 单个CPU无法实现并行
并发
多个进程看上去像同时执行 单个CPU可以实现 多个CPU肯定也可以
判断下列两句话孰对孰错
我写的程序很牛逼,运行起来之后可以实现14个亿的并行量
并行量必须要有对等的CPU才可以实现
我写的程序很牛逼,运行起来之后可以实现14个亿的并发量
合情合理 完全可以实现 以后我们的项目一般都会追求高并发
ps:目前国内可以说是最牛逼的>>>:12306
```
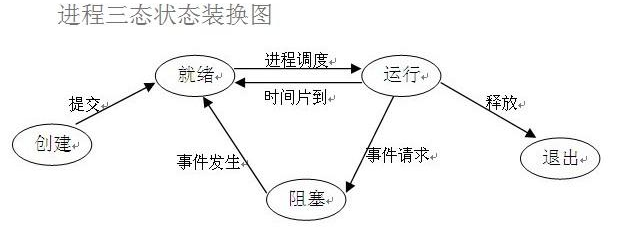
### 进程的三状态
```python
就绪态
所有的进程在被CPU执行之前都必须先进入就绪态等待
运行态
CPU正在执行
阻塞态
进程运行过程中出现了IO操作 阻塞态无法直接进入运行态 需要先进入就绪态
分类:
python学习路漫漫


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人