

正则表达式,python正则模块之re
正则表达式,python正则模块之re
今日内容概要
- 正则表达式前戏
- 正则表达式之字符组
- 正则表达式之量词
- 正则表达式之特殊符号
- 正则表达式之课堂练习
- 正则表达式之贪婪与非贪婪匹配
- 正则表达式之实战应用
- python正则模块之re
今日内容详细
正则表达式前戏
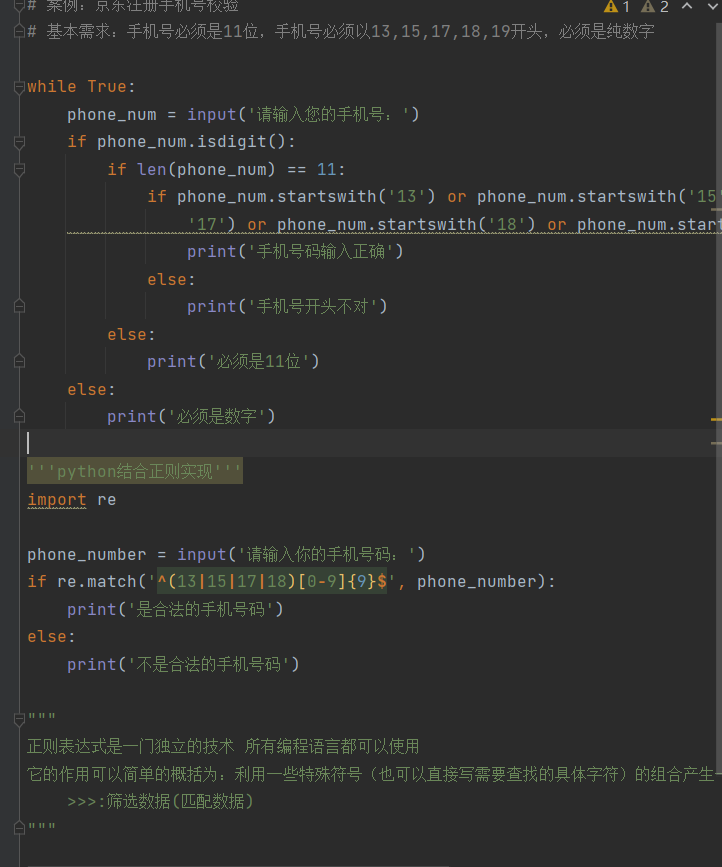
案例:京东注册手机号校验
基本需求:手机号必须是11位,手机号必须以13 15 17 18开头,必须是纯数字
'''纯python代码实现'''
while True:
phone_num = input('请输入您的手机号:')
if phone_num.isdigit():
if len(phone_num) == 11:
if phone_num.startswith('13') or phone_num.startswith('15') or phone_num.startswith(
'17') or phone_num.startswith('18') or phone_num.startswith('19'):
print('手机号码输入正确')
else:
print('手机号开头不对')
else:
print('必须是11位')
else:
print('必须是数字')
'''python结合正则实现'''
import re
phone_number = input('请输入你的手机号码:')
if re.match('^(13|15|17|18)[0-9]{9}$', phone_number):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
"""
正则表达式是一门独立的技术 所有编程语言都可以使用
它的作用可以简单的概括为:利用一些特殊符号(也可以直接写需要查找的具体字符)的组合产生一些特殊的含义然后去字符串中筛选出符合条件的数据
>>>:筛选数据(匹配数据)
"""
字符组
'''字符组默认匹配方式是挨个挨个匹配'''
[0123456789] 匹配0到9任意一个数(全写)
[0-9] 匹配0到9任意一个数(缩写)
[a-z] 匹配26个小写英文字母
[A-Z] 匹配26个大写英文字母
[0-9a-zA-Z] 匹配数字或者小写字母或者大写字母
ps:字符串内所有的数据默认都是或的关系
特殊符号
'''特殊符号默认匹配方式是挨个匹配'''
. 匹配除换行符以外的任意字符
\w 匹配数字字母下划线
\W 匹配非数字,非字母,非下划线
\d 匹配数字
^ 匹配字符串的开头
$ 匹配字符串的结尾
两者组合使用可以非常精确的限制匹配的内容
a|b 匹配a或者b(管道符的意思是或)
() 给正则表达式分组 不影响表达式的匹配功能
[] 字符组 内部填写的内容默认都是或的关系
[^] 取反操作 匹配除了字符组里面的其他所有字符
注意上尖号在中括号内和中括号外意思完全不同
量词
'''正则表达式默认情况下都是贪婪匹配>>>:尽可能多的匹'''
* 匹配零次或多次 默认是多次(无穷次)
+ 匹配一次或多次 默认是多次(无穷次)
? 匹配零次或一次 作为量词意义不大主要用于非贪婪匹配
{n} 重复n次
{n,} 重复n次或更多次 默认是多次(无穷次)
{n,m} 重复n到m次 默认是m次
ps:量词必须结合表达式一起使用 不能单独出现 并且只影响左边第一个表达式
jason\d{3} 只影响\d
课堂练习
参考博客即可
贪婪匹配与非贪婪匹配
"""所有的量词都是贪婪匹配如果想要变为非贪婪匹配只需要在量词后面加问号"""
待匹配的文本
<scrip>alert(123)</script>
待使用的正则(贪婪匹配)
<.*>
请问匹配的内容
<script>alert(123)</script> 一条
# .*属于典型的贪婪匹配 使用它 结束条件一般在左右明确指定
待使用的正则(非贪婪匹配)
<.*?>
转义符
"""斜杠与字母的组合有时候有特殊含义"""
\n 匹配的是换行符
\\n 匹配的是文本\n
\\\n 匹配的是文本\\n
ps:如果是在python中使用 还可以在字符串前面加r取消转义
正则表达式实战建议
1.编写校验用户身份证号的正则
^[1-9]\d{13,16}[0-9x]$
^[1-9]\d{14}(\d{2}[0-9x])?$
^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
2.编写校验邮箱的正则
3.编写校验用户手机号的正则(座机,移动)
4.编写校验用户QQ号的正则
'''很多时候 很多问题 前人已经弄好了 你只需要花点时间找一找就可以'''
ps:能够写出简单的正则 能够大致看懂复杂的正则
re模块
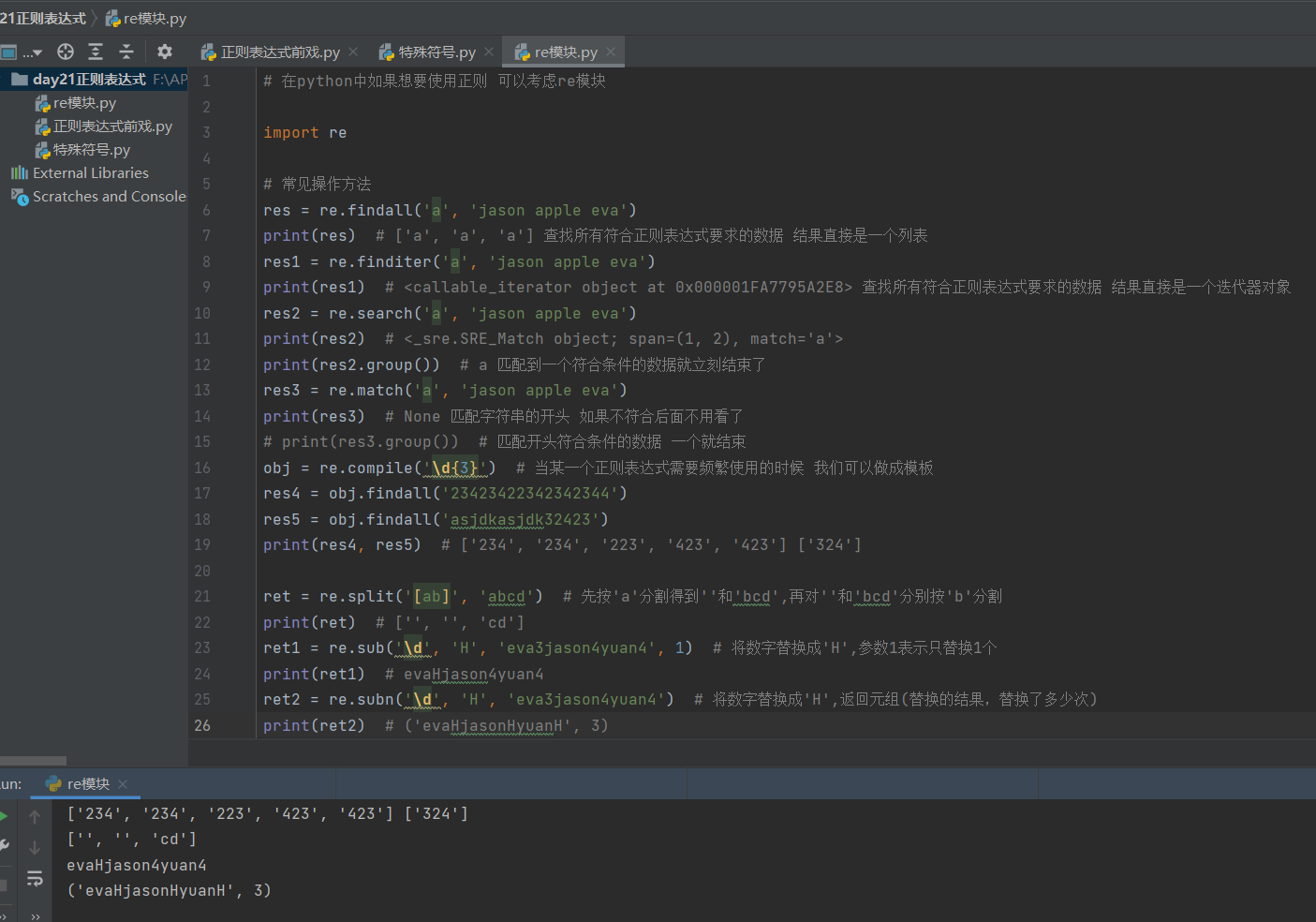
# 在python中如果想要使用正则 可以考虑re模块
import re
# 常见操作方法
res = re.findall('a', 'jason apple eva')
print(res) # ['a', 'a', 'a'] 查找所有符合正则表达式要求的数据 结果直接是一个列表
res1 = re.finditer('a', 'jason apple eva')
print(res1) # <callable_iterator object at 0x000001FA7795A2E8> 查找所有符合正则表达式要求的数据 结果直接是一个迭代器对象
res2 = re.search('a', 'jason apple eva')
print(res2) # <_sre.SRE_Match object; span=(1, 2), match='a'>
print(res2.group()) # a 匹配到一个符合条件的数据就立刻结束了
res3 = re.match('a', 'jason apple eva')
print(res3) # None 匹配字符串的开头 如果不符合后面不用看了
# print(res3.group()) # 匹配开头符合条件的数据 一个就结束
obj = re.compile('\d{3}') # 当某一个正则表达式需要频繁使用的时候 我们可以做成模板
res4 = obj.findall('23423422342342344')
res5 = obj.findall('asjdkasjdk32423')
print(res4, res5) # ['234', '234', '223', '423', '423'] ['324']
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
ret1 = re.sub('\d', 'H', 'eva3jason4yuan4', 1) # 将数字替换成'H',参数1表示只替换1个
print(ret1) # evaHjason4yuan4
ret2 = re.subn('\d', 'H', 'eva3jason4yuan4') # 将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret2) # ('evaHjasonHyuanH', 3)
re模块补充说明
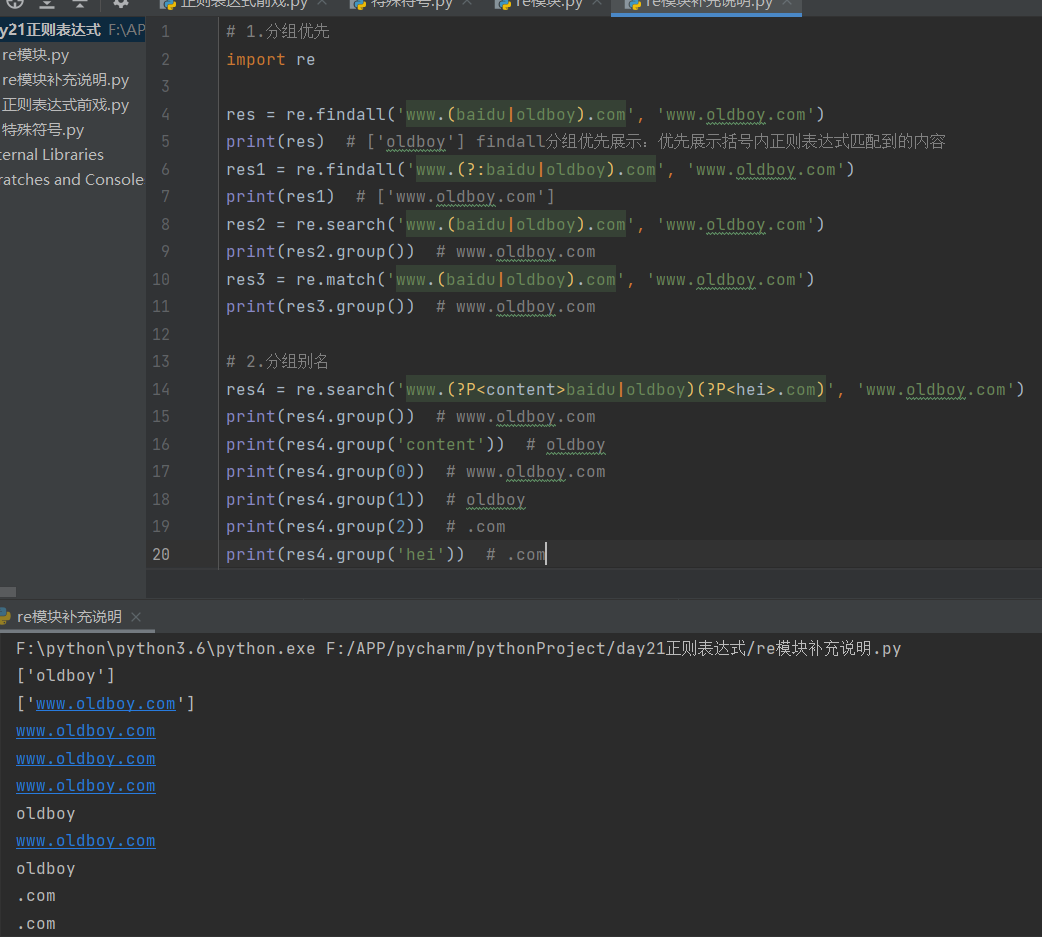
# 1.分组优先
import re
res = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(res) # ['oldboy'] findall分组优先展示:优先展示括号内正则表达式匹配到的内容
res1 = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(res1) # ['www.oldboy.com']
res2 = re.search('www.(baidu|oldboy).com', 'www.oldboy.com')
print(res2.group()) # www.oldboy.com
res3 = re.match('www.(baidu|oldboy).com', 'www.oldboy.com')
print(res3.group()) # www.oldboy.com
# 2.分组别名
res4 = re.search('www.(?P<content>baidu|oldboy)(?P<hei>.com)', 'www.oldboy.com')
print(res4.group()) # www.oldboy.com
print(res4.group('content')) # oldboy
print(res4.group(0)) # www.oldboy.com
print(res4.group(1)) # oldboy
print(res4.group(2)) # .com
print(res4.group('hei')) # .com
网络爬虫简介
网络爬虫:通过编写代码模拟浏览器发送请求获取数据并按照自己指定的要求筛选出想要的数据
小练习:利用正则表达式筛选出红牛所有的分公司数据并打印或保存
公司名称:
公司地址:
公司邮编:
公司电话:
分类:
python学习路漫漫


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App