文件操作
文件的概念
文件就是操作系统暴露给用户操作硬盘的快捷方式
with open(文件路径,读写模式,encodeing='utf8') as f:
with子代码块
with支持一次性打开多个文件
文件的读写模式
r 只读模式:只能读不能写
w 只写模式:只能写不能看
a 追加模式:未见末尾添加数据
文件的诸多方法
read # 一次性读取文件内容
readline # 一次只读一行内容
readlines # 一次读取文件内容 会按照函数组织成列表的一个个数据值
readable # 判断文件是否具备读取数据的能力
write # 写入数据
writeable # 判断文件是否具备写数据的能力
writelines # 结束一个列表 一次性将列表中所有的数据值写入
flush # 将内存中文件数据立刻刷到硬盘 等价于ctrl + s
文件内的光标移动
seek(位移量,模式)
文件光标移动案例
import time
with open(文件路径,'rb') as f:
f.seek(0,2)
while True:
line = f.readline()
if len(line) == 0:
# 没有内容
time.sleep(0.5)
else:
print(line.decode('utf8'),end='')
计算机硬盘修改数据的原理
计算机存储数据类似于刻字,一旦修改就需要重新刻,计算机删除数据并不是直接删除,而是改变状态,直到有新的数据写入才会覆盖掉原来的数据
文件操作模式
b模式:可以修改任意文件需要自己写b rb wb ab,不需要指定encodeing参数
t模式:pycharm默认模式,不需要手动写入,我们写的r w a 其实都是rt wt at,只能修改文本模式,需要指定encodeing参数,否则计算机使用默认编码
文件内容修改(了解)
# 修改文件内容的方式之一:覆盖写
打开一个文件,只读,再打开一个文件,只写,把读到的内容修改
# 修改文件内容的方式之二:换地写
'''先在另外一个地方写入内容 把源文件删除 将新文件命名成源文件'''
函数基础1
函数前置
函数相当于工具
不用函数
修理工需要修理器件要用锤子 原地打造 每次用完就扔掉 下次用继续原地打造
用函数
修理工提前准备好工具 什么时候想用就直接拿出来使用
函数的语法结构
def 函数名 (参数):
函数体代码
return返回值
函数的定义与调用
定义:def 函数名(形参):
函数体代码
return
函数在定义阶段只检测语法 不执行代码
函数在调用阶段才会执行函数体代码
函数必须先定义再调用
调用:函数名(实参)
函数的分类
空函数 # 函数体代码为空 主要用于项目前期的功能框架搭建
无参函数 # 定义函数的时候括号内没有参数
有参函数 # 定义函数时括号内写参数 调用时传参
函数的返回值
调用函数之后返回给调用者的结果
res=func()接收返回值
return后边写什么返回什么
没有写默认返回none
函数体代码return后有多个数据 则自动组织成元组返回
函数体代码遇到return会立即结束
函数的参数
形参:在定义阶段括号内写的参数,类似于变量名
实参:在调用阶段括号内写的参数,类似于数据值,在调用阶段与形参临时绑定 函数结束运行立刻断开
函数基础2
函数参数之位置参数
def index(a,b,c,d):
print(a,b,c,d)
index(1,2,3,4)
位置传参必须按顺序传参,不能少一个也不能多一个,多一个少一个都会报错
默认函数
默认参数是定义函数的时候传入的固定参数,默认函数也称为关键字传参
def index(a=1,name='jason',age=18):
print(f'编号:{a},姓名{name},年龄{age}')
index(a=2,name='kevin',age=19)
默认参数可以传可以不传
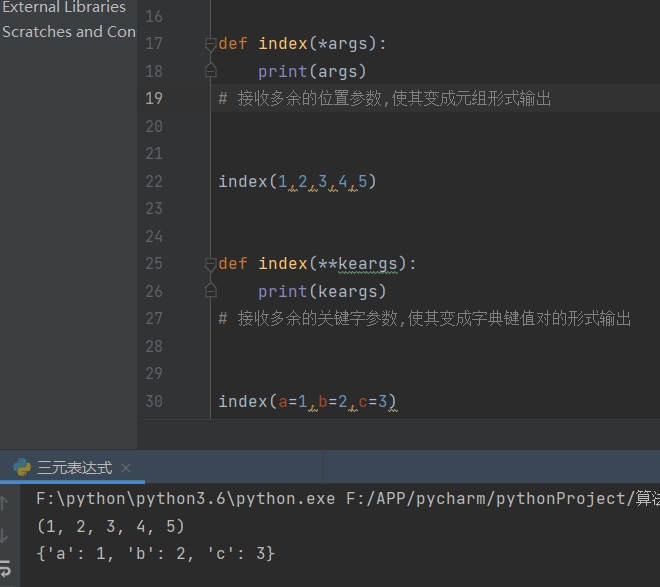
可变长形参
def index(*args):
print(args)
# 接收多余的位置参数,使其变成元组形式赋值给*号后边的变量名
index(1,2,3,4,5)
def index(**keargs):
print(keargs)
# 接收多余的关键字参数,使其变成字典键值对的形式赋值给**后边的变量名
index(a=1,b=2,c=3)
可变长实参
*在实参中
类似于for循环 将所有循环遍历出来的数据按照位置参数一次传给函数
**在实参中
字典打散成关键字参数的形式传递给函数
命名关键字参数(了解)
形参必须按照关键字参数传参>>>:命名关键字参数
名称空间
# 内置名称空间 全局名称空间 局部名称空间
内置名称空间
解释器运行自动产生 里面包含了很多名字
全局名称空间
py文件运行产生 里面存放文件级别的名字
局部名称空间
函数体代码运行\类体代码运行 产生的空间
名称空间存活周期及作用范围
1.内置名称空间:作用于解释器级别,pycharm打开则创建,关闭则销毁
2.全局名称空间:作用于py文件级别,py文件创建则创建,关闭py文件则销毁
3.局部名称空间:作用于函数内部,函数创建则创建,函数结束则销毁
名字的查找顺序
局部名称空间>>>全局名称空间>>>内置名称空间
全局名称空间>>>内置名称空间
1.当在局部名称空间找数据值时,会先在局部名称空间找,然后去全局名称空间找,找不到去内置名称空间找
2.当数据值在全局名称空间时,会在全局名称空间找,找不到然后去内置
查找顺序案例
相互独立的局部名称空间不能够互相访问
函数高级
global与nonlocal
global:全局名称空间修改内置名称空间的数据值
nonlocal:内部局部名称空间修改外部局部名称空间
函数名的多种用法
1.可以作为函数的参数
2.可以作为返回值
3.可以作为变量名赋值
4.可以当做容器类型的数据
闭包函数
1.定义在函数内部
2.用到外部函数名称空间中的名字
# 给函数体代码传参的方式1:代码里面缺什么变量名形参里面就补什么变量名
# 给函数体代码传参的方式2:闭包函数
装饰器简介
在不改变装饰对象的内容和调用情况的情况下,给装饰器对象增加新的功能
装饰器模板
def outer(func_name):
def inner(*args, **kwargs):
'''被装饰对象执行前可进行的操作'''
res = func_name(*args, **kwargs)
return res
return inner
outer = outer()
装饰器语法糖
def outer(func_name):
def inner(*args, **kwargs):
'''被装饰对象执行前可进行的操作'''
res = func_name(*args, **kwargs)
return res
return inner
@outer # outer = outer()
def index():
print('from index')
函数高级总结补充
多层语法糖问题
由下而上,如果上边还有语法糖,则把返回的函数名当做参数传给上边的语法糖调用
如果没有语法糖,则变形index = outer1(wrapper2)
有参装饰器
当装饰器需要传入额外的参数时,用到有参装饰器
def outer_plus(a):
def outer(func_name):
def inner(*args, **kwargs):
'''被装饰对象执行前可进行的操作'''
res = func_name(*args, **kwargs)
return res
return inner
return outer
函数名加括号执行优先级最高
有装饰器的情况
先看函数名加括号的执行
在是语法糖的操作
装饰器修复技术
就是让装饰器看起来更逼真,用到一个函数
from functools import wraps
在函数下
@wraps(参数)
递归函数
直接或间接调用函数本身
要有一个明确的结束条件
每次递归都要比上一次简单
def get_age(num):
if num = 1:
return 18
return index(num - 1) + 2
res = get_age(5)
print(res)
算法,表达式,内置函数
算法简介及二分法
算法就是解决问题的方法,不是所有的算法都很高效也有不及格的算法
三元表达式
res = '1' if 条件1 else '2'
print(res)
各种生成式
字典生成式
res={i:j for i,j in enumarter(s1,start=)} # enumerate就是一个把字符串转成从零记录每个字符的字典,可以在后面写入开始记录的起始数字
列表生成式
res=[i(此处可进行操作) for i in l1]
集合生成式
res={i for i in 数据值}
元组生成式 # 元组生成式>>>:没有元组生成式 下列的结果是生成器(后面讲)
res = (i(此处可进行操作) for i in s1)
for i in res1:
print(i)
匿名函数
res = (lambda 形参:返回值)
res = (lambda a,b:a+b)
常见内置函数
map # 映射
reduce # 传多个值 返回一个值
zip
max,min
bin,oct,hex,int
bytes,print,input
filter # 取所有比传入参数大的值
sorted # 默认升序
abs # 绝对值
all # 所有数据值对应的布尔值为True结果才是True否则返回False
any # 所有数据值对应的布尔值有一个为True结果就是True 否则返回
callable # 判断名字是否可以加括号调用
chr,ord
dir # 返回括号内对象能够调用的名字
divmod # 元组 第一个数据为整除数 第二个是余数
enumerate # 枚举
eval,exec # 能够识别字符串中的python并执行,eval只能识别简单的python代码 具有逻辑性的都不行,exec可以识别具有一定逻辑性的python代码
hash # 哈希加密
id,isinstance
open
pow # 幂指数
range
round # 四舍五入
sun # 求和
重要内置函数,可迭代对象,迭代器对象,for循环内部原理,异常处理
可迭代对象
能使用.之后__iter__都称为可迭代对象
不是可迭代对象
int float bool 函数对象
是可迭代对象
str list dict tuple set 文件对象
迭代:更新换代(每次更新都必须依赖上一次的结果)
可迭代在python中可以理解为是否支持for循环
迭代器对象
在使用__iter__之后能用__iter__和__next__
提供了一种不依赖于索引值的方式
取不到值会报错
注意
可迭代对象调用__iter__会成为迭代器对象 迭代器对象如果还调用__iter__不会有任何变化 还是迭代器对象本身
for循环的本质
1.先对可迭代对象使用__iter__
2.然后再使用__next__并接收返回的值
3.循环完毕报错会自动被for循环捕获并处理
异常捕获|处理
俗称:bug
代码运行中一旦遇到异常会直接结束整个程序的运行 我们在编写代码的过程中要尽可能避免
有两种bug:
语法错误:不允许出现,不然代码和你至少要能跑一个
逻辑错误:犯了及时修改bug,代码运行之后才会出现
报错结构:
错误位置
错误类型:错误具体内容



