算法简介及二分法,三元表达式,各种生成式,匿名函数,常见内置函数
今日内容概要
- 算法简介及二分法
- 三元表达式
- 各种生成式
- 匿名函数
- 常见内置函数
今日内容详细
算法简介及二分法
1.什么是算法
算法就是解决问题的有效方法 不是所有的算法都很高效 也有不及格的算法
2.算法应用场景
推荐算法(抖音视频推送 淘宝商品推送)
成像算法(AI相关)......
几乎涵盖了我们日常生活中的方方面面
3.算法工程师要求
待遇非常好 但是要求也非常高
4.算法部门
不是所有互联网公司都养得起算法部门 只有大型互联网公司才有
算法部门类似于药品研发部门
5.二分法
是算法中最简单的算法 甚至都称不上是算法
"""
二分法使用要求
待查找数据集必须有序
二分法的缺陷
针对开头结尾的数据 查找效率很低
常见算法原理以及伪代码
二分法,冒泡,快拍,插入,堆排,桶排,结构数据(链表 约瑟夫问题 如何链表是否成环)
"""
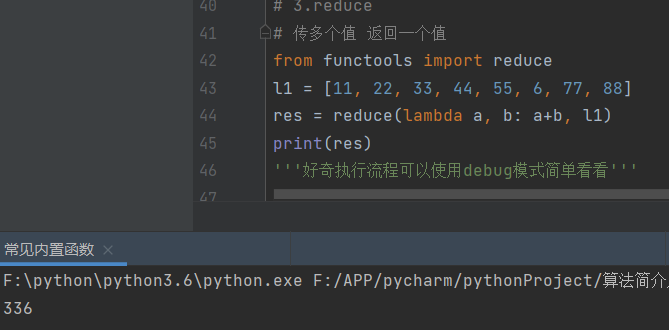
l1 = [12, 21, 32, 43, 56, 76, 87, 98, 123, 321, 453, 565, 678, 754, 812, 987, 1001, 1232]
# 查找列表中某个数据值
# 方式1:for循环 次数较多
# 方式2:二分法 不断的对数据集做二分切割
'''代码实现二分法'''
# 先定义我们需要查找的数据值
num = 453
def get_num(list, func_num):
# 定义一个结束条件
if len(list) == 0:
print('很抱歉,没有你想要的值')
return
# 1.获取列表中间的索引值
half_num = len(list) // 2
# 2.判断比较目标数据值与中间索引值的大小
if func_num < list[half_num]:
# 3.切片保留左边一半
left_list = list[:half_num]
print(left_list)
# 针对左边一半列表继续使用二分并判断>>>:用递归函数
return get_num(left_list, func_num)
elif func_num > list[half_num]:
right_list = list[half_num+1:]
print(right_list)
return get_num(right_list, func_num)
else:
print('恭喜你找到了')
# get_num(l1, num)
# get_num(l1, 76)
三元表达式
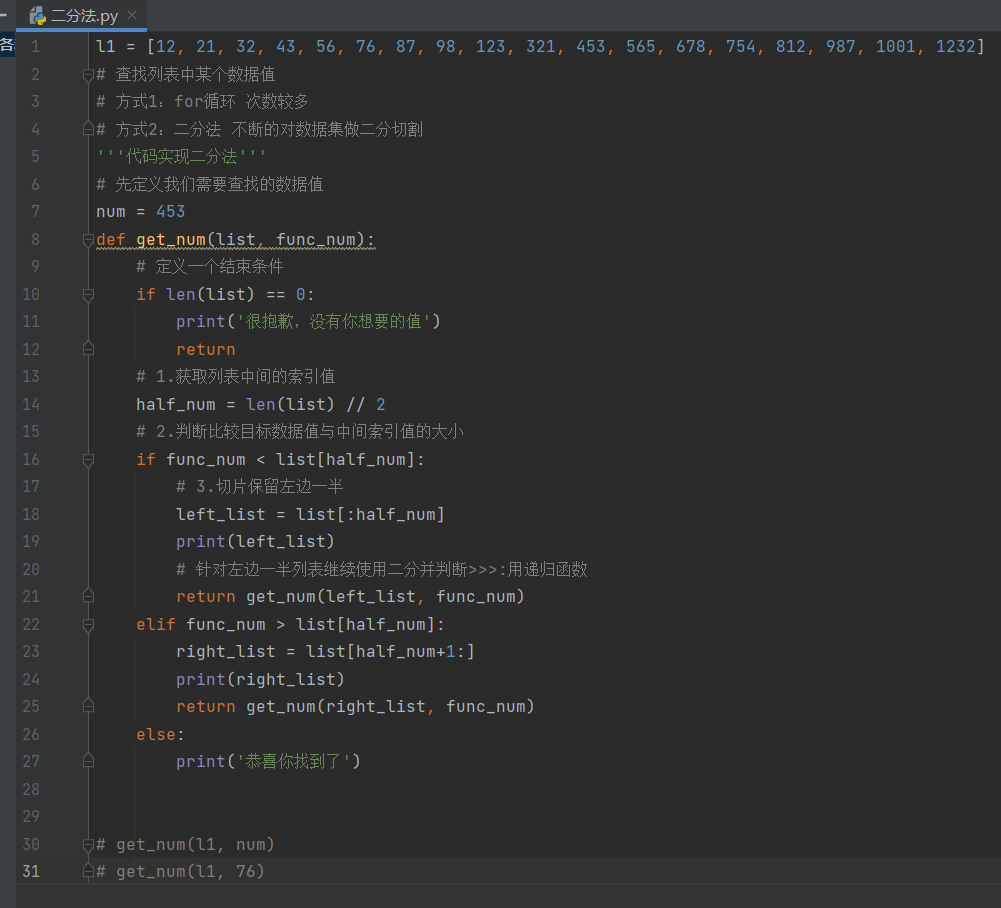
# 简化步骤1:代码简单并且只有一行 那么可以直接在冒号后面编写
name = 'jason'
if name == 'jason':print('老师')
else:print('学生')
# 三元表达式
res = '老师' if name == 'jason' else '学生'
print(res)
"""
数据值1 if 条件 else 数据值2
条件成立则使用条件1 条件不成立则使用数据值2
当结果是二选一的情况下 使用三元表达式较为简便
并且不推荐多个三元表达式嵌套
"""
各种生成式/表达式/推导式
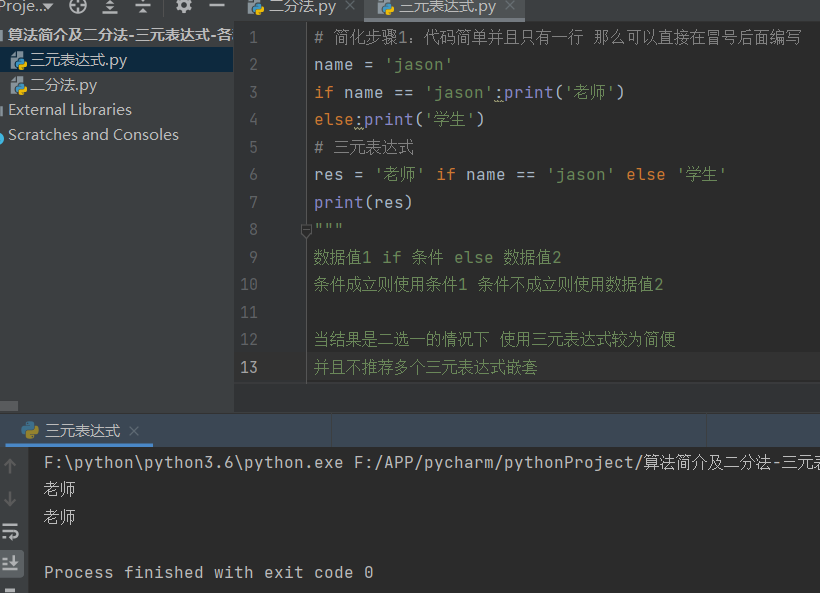
name_list = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
# 给列表中所有人名的后面加上_NB的后缀
# for循环
new_list = []
for i in name_list:
new_list.append(f'{i}_NB')
print(new_list)
# 列表生成式
# 先看for循环 每次for循环之后再看for关键字前面的操作
new_list1 = [name + '_NB' for name in name_list]
print(new_list1)
# 复杂情况
new_list2 = [name + '_NB' for name in name_list if name == 'jason']
print(new_list2)
new_list3 = ['大佬' if name == 'jason' else '小赤佬' for name in name_list if name != 'tony']
print(new_list3)
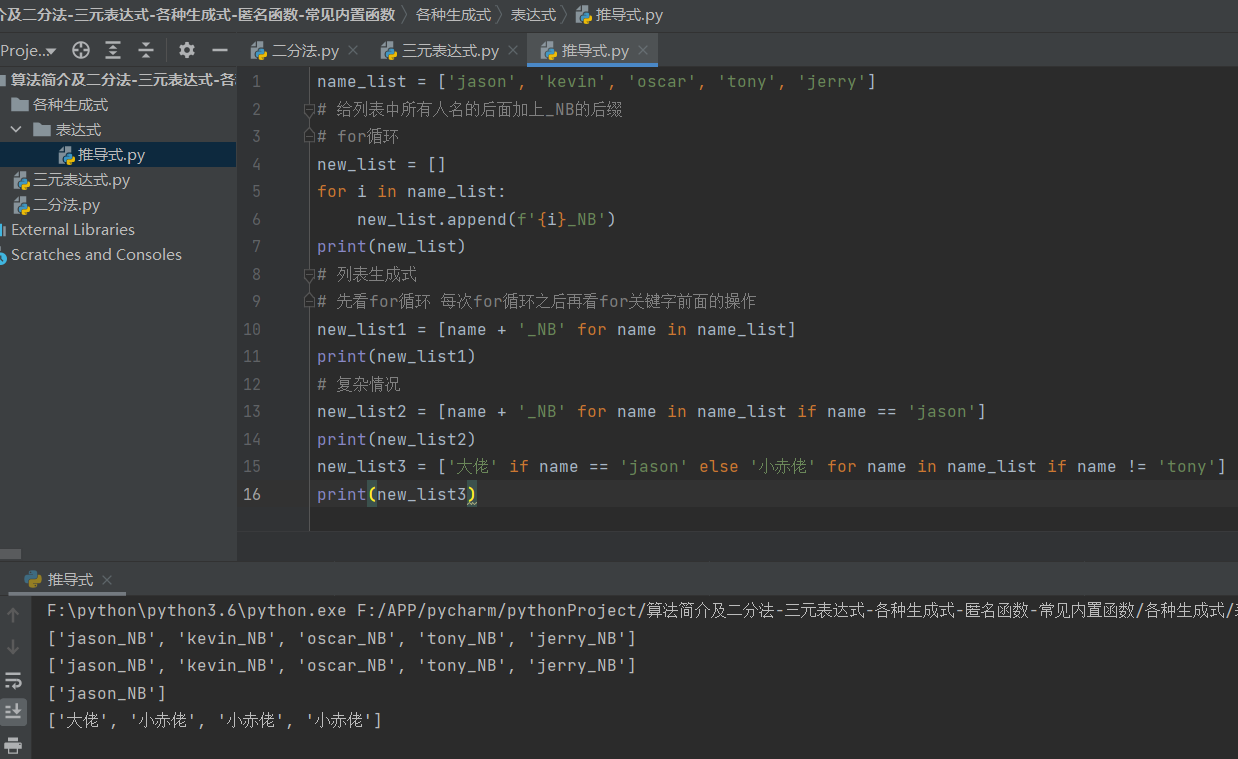
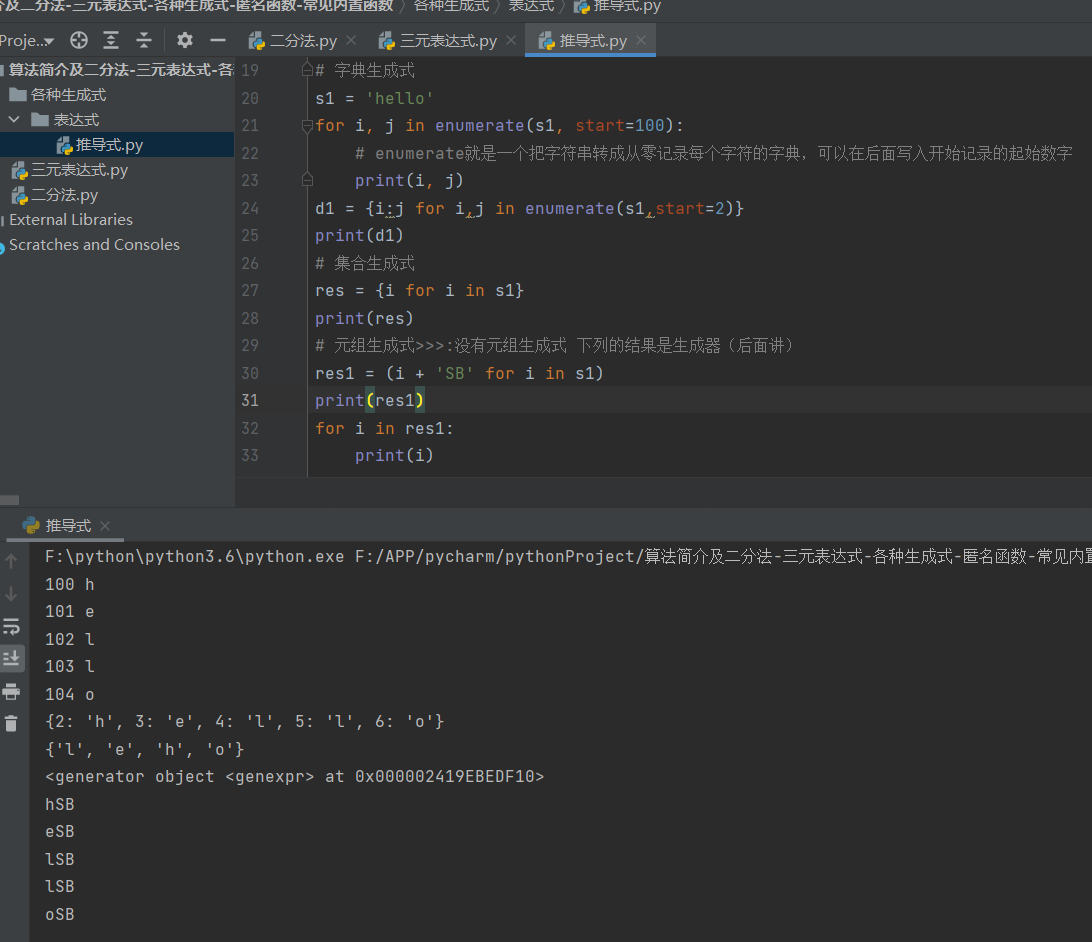
# 字典生成式
s1 = 'hello'
for i, j in enumerate(s1, start=100):
# enumerate就是一个把字符串转成从零记录每个字符的字典,可以在后面写入开始记录的起始数字
print(i, j)
d1 = {i:j for i,j in enumerate(s1,start=2)}
print(d1)
# 集合生成式
res = {i for i in s1}
print(res)
# 元组生成式>>>:没有元组生成式 下列的结果是生成器(后面讲)
res1 = (i + 'SB' for i in s1)
print(res1)
for i in res1:
print(i)
匿名函数
没有名字的函数 需要使用关键字lambda
语法结构
lambda 形参:返回值
使用场景
lambda a,b:a+b
匿名函数一般不单独使用 需要配合其他函数一起用
常见内置函数
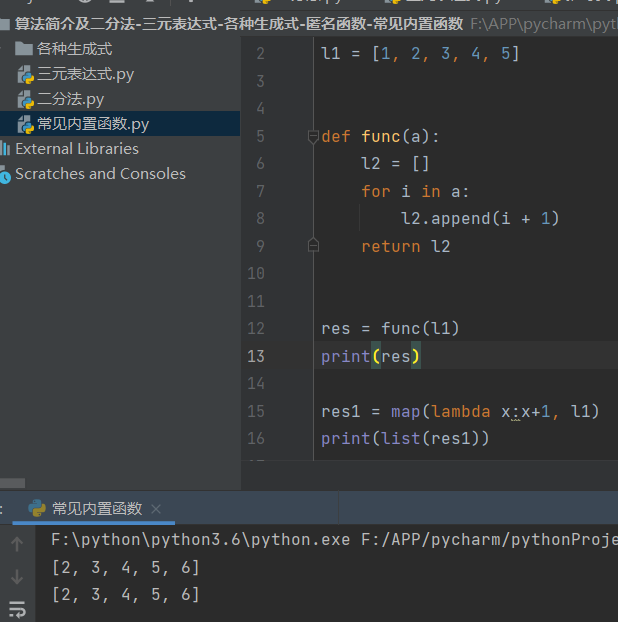
# 1.map() 映射
l1 = [1, 2, 3, 4, 5]
# 1.用函数的情况
def func(a):
l2 = []
for i in a:
l2.append(i + 1)
return l2
res = func(l1)
print(res)
# 2.用内置函数的情况
res1 = map(lambda x:x+1, l1)
print(list(res1))
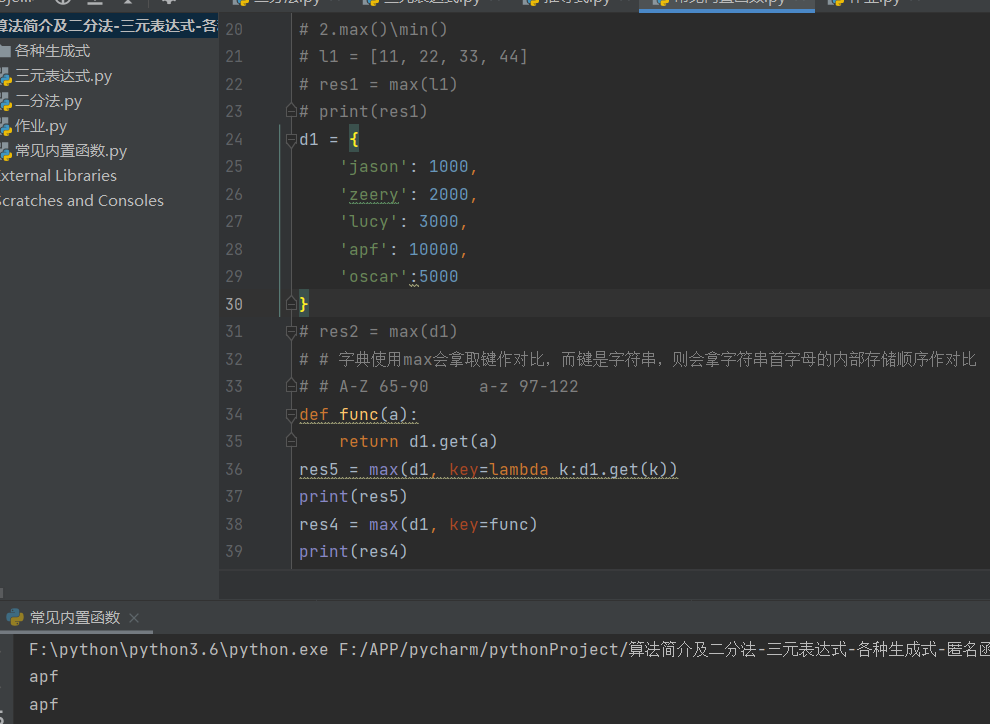
# 2.max()\min()
l1 = [11, 22, 33, 44]
res1 = max(l1)
print(res1)
d1 = {
'jason': 1000,
'zeery': 2000,
'lucy': 3000,
'apf': 10000,
'oscar':5000
}
res2 = max(d1)
# 字典使用max会拿取键作对比,而键是字符串,则会拿字符串首字母的内部存储顺序作对比
# A-Z 65-90 a-z 97-122
def func(a):
return d1.get(a)
res5 = max(d1, key=lambda k:d1.get(k))
print(res5)
res4 = max(d1, key=func)
print(res4)
# 3.reduce
# 传多个值 返回一个值
from functools import reduce
l1 = [11, 22, 33, 44, 55, 6, 77, 88]
res = reduce(lambda a, b: a+b, l1)
print(res)
'''好奇执行流程可以使用debug模式简单看看'''