字典,元组,集合相关操作,字符编码(理论)
今日内容概要
- 字典相关操作
- 元组相关操作
- 集合相关操作
- 字符编码(理论)
今日内容详细
字典相关操作
1.类型转换
dict()
字典的转换一般不使用关键字 而是自己动手转
2.字典必须要掌握的操作
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run'],
}
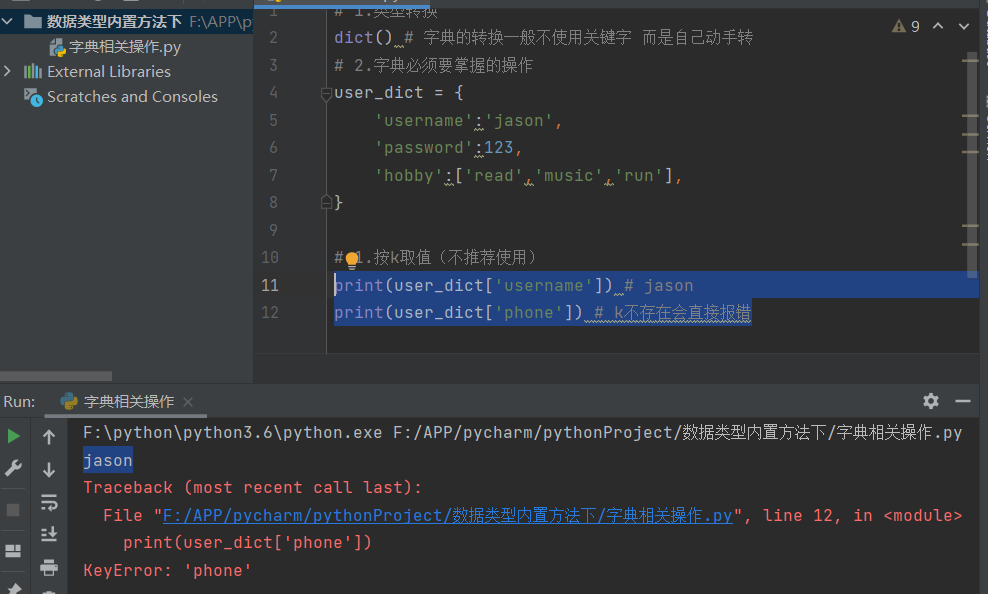
1.按k取值(不推荐使用)
print(user_dict['username']) # jason
print(user_dict['phone']) # k不存在会直接报错
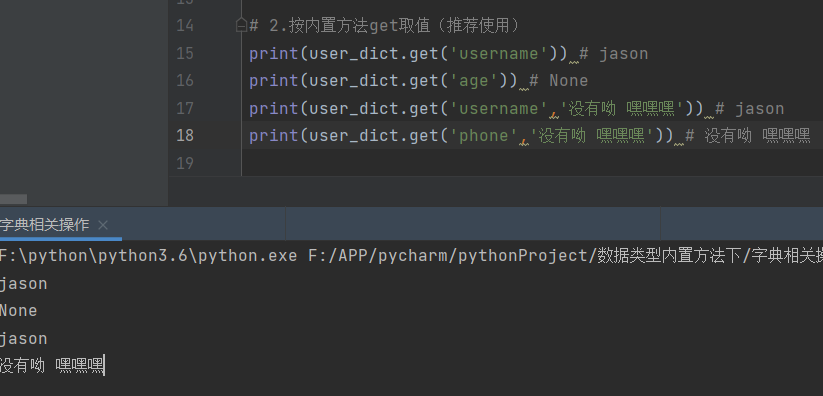
2.按内置方法get取值(推荐使用)
print(user_dict.get('username')) # jason
print(user_dict.get('age')) # None
print(user_dict.get('username','没有呦 嘿嘿嘿')) # jason
print(user_dict.get('phone','没有呦 嘿嘿嘿')) # 没有呦 嘿嘿嘿
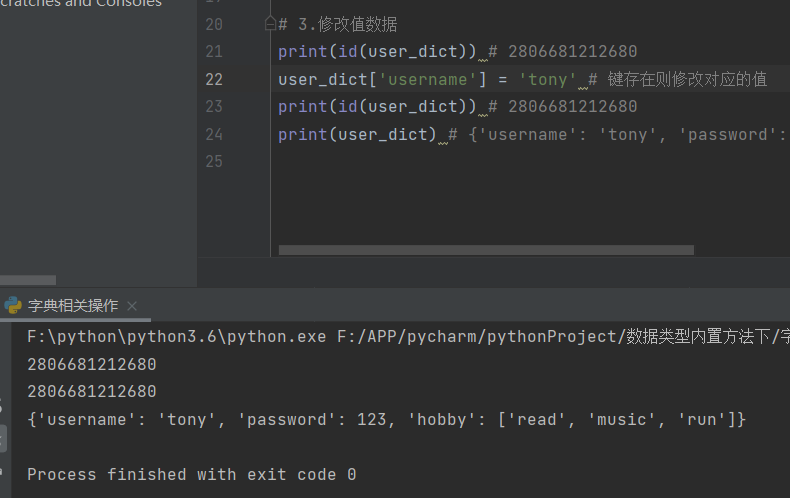
3.修改值数据
print(id(user_dict)) # 2806681212680
user_dict['username'] = 'tony' # 键存在则修改对应的值
print(id(user_dict)) # 2806681212680
print(user_dict) # {'username': 'tony', 'password': 123, 'hobby': ['read', 'music', 'run']
4.新增键值对
user_dict['age'] = 18 # 键不存在则新增键值对
print(user_dict)

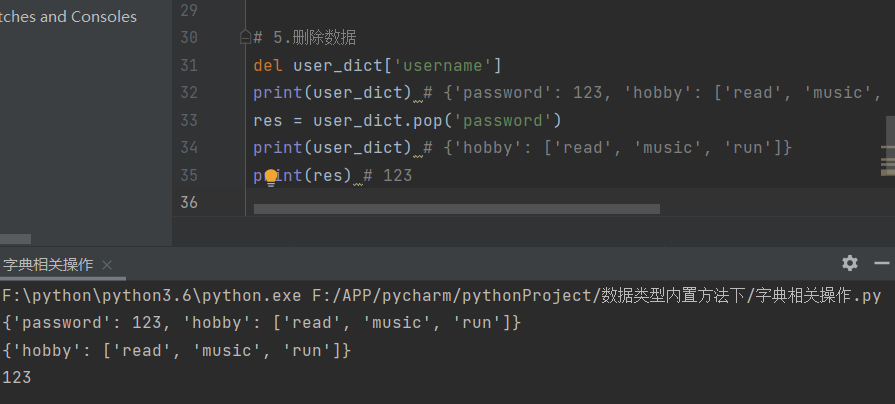
5.删除数据
del user_dict['username']
print(user_dict) # {'password': 123, 'hobby': ['read', 'music', 'run']}
res = user_dict.pop('password')
print(user_dict) # {'hobby': ['read', 'music', 'run']}
print(res) # 123
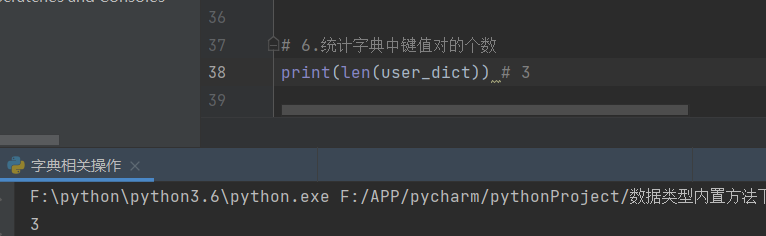
6.统计字典中键值对的个数
print(len(user_dict)) # 3
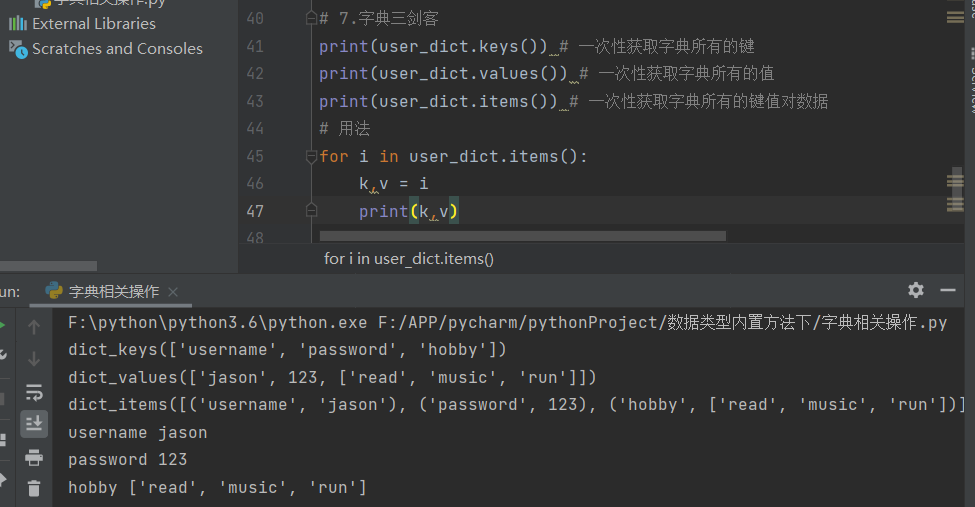
7.字典三剑客
print(user_dict.keys()) # 一次性获取字典所有的键
print(user_dict.values()) # 一次性获取字典所有的值
print(user_dict.items()) # 一次性获取字典所有的键值对数据
# 用法
for i in user_dict.items():
k,v = i
print(k,v)
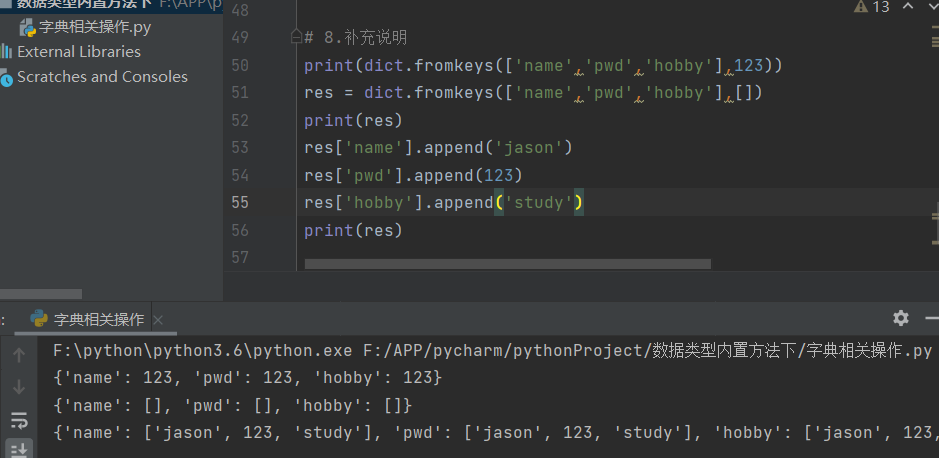
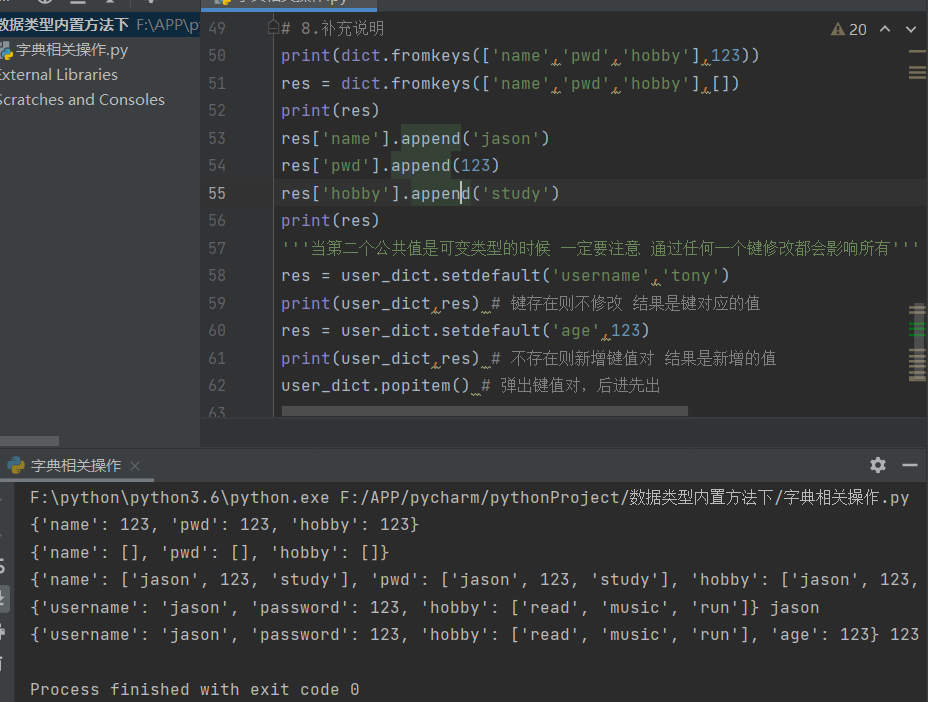
8.补充说明
print(dict.fromkeys(['name','pwd','hobby'],123))
res = dict.fromkeys(['name','pwd','hobby'],[])
print(res)
res['name'].append('jason')
res['pwd'].append(123)
res['hobby'].append('study')
print(res)
'''当第二个公共值是可变类型的时候 一定要注意 通过任何一个键修改都会影响所有'''
res = user_dict.setdefault('username','tony')
print(user_dict,res) # 键存在则不修改 结果是键对应的值
res = user_dict.setdefault('age',123)
print(user_dict,res) # 不存在则新增键值对 结果是新增的值
user_dict.popitem() # 弹出键值对,后进先出
元组相关操作
1.类型转换
tuple()
ps:支持for循环的数据类型都可以转成元组
2.元组必须掌握的方法
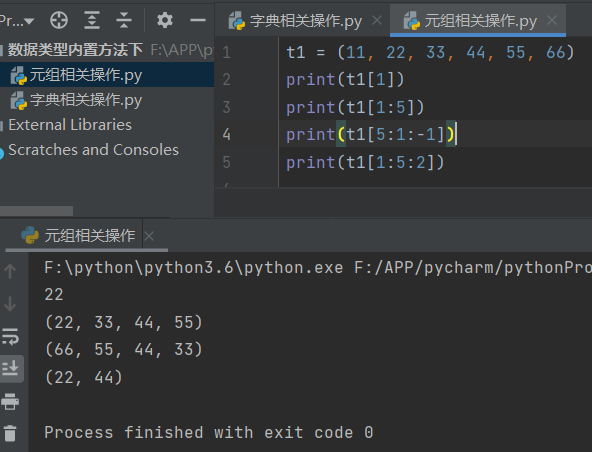
t1 = (11, 22, 33, 44, 55, 66)
1.索引取值
2.切片操作
3.间隔方向
4.统计元组内数据值的个数
print(len(t1)) # 6
5.统计元组内某个数据值出现的次数
print(t1.count(11))
6.统计元组内指定数据值的索引值
print(t1.index(22))
7.元组内如果只有一个数据值那么逗号不能少
8.元组内索引绑定的内存地址不能被修改(注意区分 可变与不可变)
9.元组不能新增或删除数据
集合相关操作
1.类型转换
set()
集合内数据必须是不可变类型(整型 浮点型 字符串 元组)
集合内数据也是无序的 没有索引的概念
2.集合需要掌握的方法
去重
关系运算
ps:只有遇到上述两种需求的时候菜应该考虑使用集合
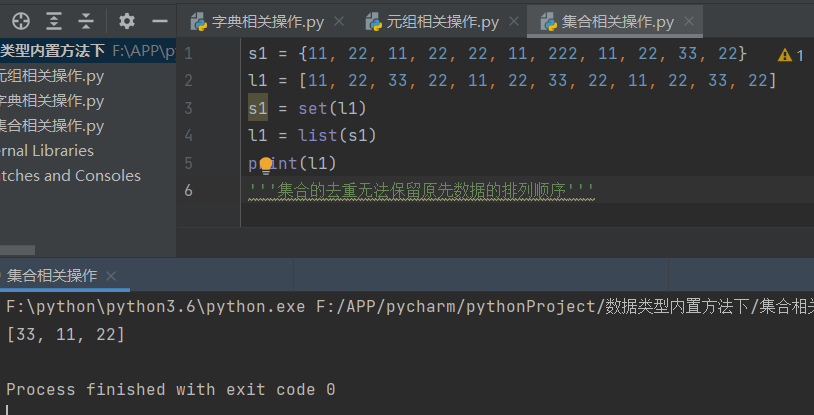
3.去重
s1 = {11, 22, 11, 22, 22, 11, 222, 11, 22, 33, 22}
l1 = [11, 22, 33, 22, 11, 22, 33, 22, 11, 22, 33, 22]
s1 = set(l1)
l1 = list(s1)
print(l1)
'''集合的去重无法保留原先数据的排列顺序'''
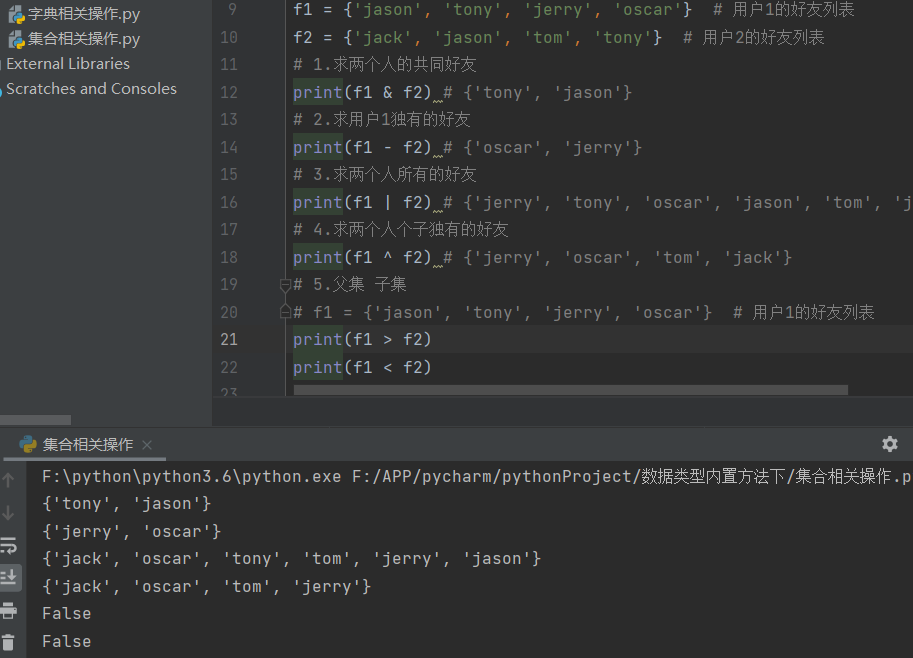
4.关系运算
群体直接做差异化校验
eg:两个微信账户之间 有不同的好友 有相同的好友
f1 = {'jason', 'tony', 'jerry', 'oscar'} # 用户1的好友列表
f2 = {'jack', 'jason', 'tom', 'tony'} # 用户2的好友列表
# 1.求两个人的共同好友
print(f1 & f2) # {'tony', 'jason'}
# 2.求用户1独有的好友
print(f1 - f2) # {'oscar', 'jerry'}
# 3.求两个人所有的好友
print(f1 | f2) # {'jerry', 'tony', 'oscar', 'jason', 'tom', 'jack'}
# 4.求两个人个子独有的好友
print(f1 ^ f2) # {'jerry', 'oscar', 'tom', 'jack'}
# 5.父集 子集
# f1 = {'jason', 'tony', 'jerry', 'oscar'} # 用户1的好友列表
print(f1 > f2)
print(f1 < f2)
字符编码理论
该知识点理论特别多 但是结论很少 代码使用也很短
1.字符编码只针对文本数据
2.会议计算机内部存储数据的本质
3.既然计算机内部只认识01 为什么我们却可以翘楚人类各式各样的字符
肯定存在一个数字跟字符的对应关系 存储该关系的地方称为>>>:字符编码本
4.字符编码发展史
4.1.一家独大
计算机是由美国人发明的 为了能够让计算机识别英文
需要发明一个数字跟英文字母的对应关系
ASCII码:记录了英文字母跟数字的对应关系
用8bit(1字节)来表示一个英文字符
4.2.群雄割据
中国人
GBK码:记录了英文 中文与数字的对应关系
用至少16bit(2字节)来表示一个中文字符
很多生僻字还需要使用更多的字节
英文还是用8bit(1字节)来表示
日本人
shift_JIS码:记录了英文 日文与数字的对应关系
韩国人
Euc_kr码:记录了英文 韩文与数字的对应关系
'''
每个国家的计算机使用的都是自己定制的编码本
不同国家的文本数据无法直接交互 会出现“乱码”
'''
4.3.天下一统
Unicode万国码
兼容所有国家语言字符
起步就是两个字节来表示字符
utf系列:utf8 utf16...
专门用于优化unicode存储问题
英文还是采用字节 中文三个字节
字符编码实操
1.针对乱码不要慌 切换编码慢慢试即可
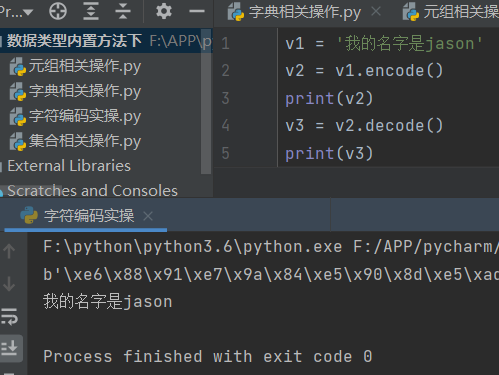
2.编码与解码
编码:将人类的字符按照指定的编码 编码成计算机能够读懂的数据
字符串.encode()
解码:将计算机能够读懂的数据按照指定的编码解码成人能够读懂
bytes类型数据.decode()
3.pyehon2与python3差异
python2默认的编码是ASCII
1.文件头
# encoding:utf8
2.字符串前面加u
u'你好啊'
python3默认的编码是utf系列(Unicode)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号