链表(二)—循环链表、双向链表
1 循环链表
1.1 循环链表的定义
循环链表是一种特殊的单链表,将单链表中尾结点的指针域由空指针改为指向链表的头结点。
1.2 循环链表的实现及关键点
1.2.1 关键点
单链表和循环链表的唯一区别就是尾结点的指针值,所以循环判断时,由原来的是否为空,现在则是是否为头结点,则循环结束。
1.2.2 实现
与单链表实现类似,修改循环判断条件即可。可参考:https://www.cnblogs.com/zpchya/p/10672180.html。
1.3 循环链表的适用场景
当要处理的数据具有环型结构特点时,就特别适合采用循环链表。
2 双向链表
2.1 双向链表的出现背景
在单链表中,有了next指针使得我们查找下一个结点的时间复杂度为O(n)。但是如果我们想查找上一个结点就得重新开始遍历,最坏情况时间复杂度就为O(n)。为了克服单链表单向性这个缺点,所以有了双向链表。
2.2 双向链表的定义
双向链表就是每个结点不止有后继指针next指向后面的结点,还有一个前驱指针prev指向前面的结点,它支持两个方向。
2.3 双向链表的特点
1)存储同样的多的数据,双向链表需要额外的两个空间来存储后继结点和前驱结点地址,带来灵活性的同时,也消耗了内存空间;
2)因为有前驱结点指针,所以可以时间复杂度为O(1)的找到前驱结点,可以提高某些情况下插入和删除操作的效率。
2.4 双向链表的实现及关键点
2.4.1 关键点
1)双向链表的实现很多地方都和单链表类似,所以对于“哨兵”节点、指针赋值、内存释放和边界条件检查双向链表都要注意;
2)因为双向链表多了前驱指针,所以插入和删除操作时指针赋值顺序要特别注意,对于插入操作可以记住以下顺序:先搞定待插入结点的前驱和后继指针,在搞定后结点的前驱指针,最后解决前结点的后继指针;
3)前驱指针使得最后一个结点具有特殊性,插入删除时不能统一操作,实现时应特殊考虑。
2.4.2 实现
有“哨兵”节点:
1 #ifndef DOUBLELINKLIST_H 2 #define DOUBLELINKLIST_H 3 4 typedef int ElemType; 5 typedef struct Node 6 { 7 ElemType m_data; 8 Node* m_prior; //前驱结点指针 9 Node* m_next; //后继结点指针 10 }* dLinkList; 11 12 class DoubleLinkList 13 { 14 private: 15 dLinkList m_head; 16 17 public: 18 DoubleLinkList(); 19 ~DoubleLinkList(); 20 void ClearList(); //清空链表 21 bool InsertNode(int i, ElemType elem); //往第i个结点前插入新结点 22 bool DeleteNode(int i, ElemType* pElem); //删除第i个结点 23 void VisitList() const; //遍历链表 24 }; 25 26 #endif
1 #include "pch.h" 2 #include "DoubleLinkList.h" 3 #include <iostream> 4 5 DoubleLinkList::DoubleLinkList() 6 { 7 m_head = new Node; 8 m_head->m_next = nullptr; 9 m_head->m_prior = nullptr; 10 } 11 12 DoubleLinkList::~DoubleLinkList() 13 { 14 ClearList(); 15 delete m_head; 16 } 17 18 void DoubleLinkList::ClearList() //清空链表 19 { 20 Node* pWorkNode = m_head->m_next, *pDeleteNode = nullptr; 21 22 while (pWorkNode) 23 { 24 pDeleteNode = pWorkNode; 25 pWorkNode = pWorkNode->m_next; 26 delete pDeleteNode; 27 } 28 m_head->m_next = nullptr; 29 } 30 31 bool DoubleLinkList::InsertNode(int i, ElemType elem) //往第i个结点前插入新结点 32 { 33 Node* pWorkNode = m_head; 34 int j = 1; 35 Node* pNewNode = new Node; 36 pNewNode->m_data = elem; 37 38 while (j < i && pWorkNode->m_next) 39 { 40 pWorkNode = pWorkNode->m_next; 41 ++j; 42 } 43 if (j > i) 44 return false; 45 pNewNode->m_next = pWorkNode->m_next; 46 pNewNode->m_prior = pWorkNode; 47 if (pWorkNode->m_next) //如果不是最后一个结点 48 pNewNode->m_next->m_prior = pNewNode; 49 pWorkNode->m_next = pNewNode; 50 51 return true; 52 } 53 54 bool DoubleLinkList::DeleteNode(int i, ElemType* pElem) //删除第i个结点 55 { 56 Node *pDeleteNode = nullptr, *pWorkNode = m_head; 57 int j = 0; 58 59 while (j < i && pWorkNode->m_next) //遍历到待删除结点 60 { 61 pWorkNode = pWorkNode->m_next; 62 ++j; 63 } 64 if (j > i) 65 return false; 66 pWorkNode->m_prior->m_next = pWorkNode->m_next; 67 if (pWorkNode->m_next) //如果不是最后一个结点 68 pWorkNode->m_next->m_prior = pWorkNode->m_prior; 69 70 return true; 71 } 72 73 void DoubleLinkList::VisitList() const //遍历链表 74 { 75 Node* pWorkNode = m_head->m_next; 76 77 std::cout << "the element of list: "; 78 while (pWorkNode) 79 { 80 std::cout << pWorkNode->m_data << ' '; 81 pWorkNode = pWorkNode->m_next; 82 } 83 std::cout << std::endl; 84 }
测试代码(Visual Studio 2017):
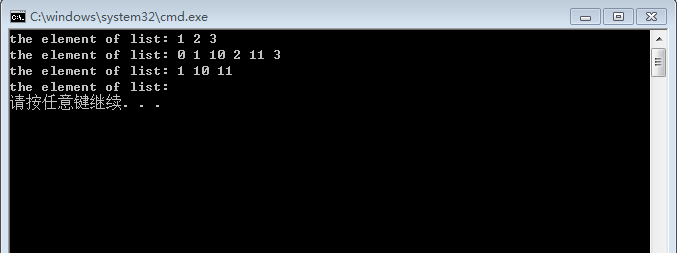
1 #include "pch.h" 2 #include "DoubleLinkList.h" 3 #include <iostream> 4 5 using namespace std; 6 7 int main() 8 { 9 DoubleLinkList list; 10 //尾结点后插入 11 list.InsertNode(1, 1); 12 list.InsertNode(2, 2); 13 list.InsertNode(3, 3); 14 list.VisitList(); 15 //第一结点前插入 16 list.InsertNode(1, 0); 17 //中间结点插入 18 list.InsertNode(3,10); 19 //尾结点前插入 20 list.InsertNode(5, 11); 21 list.VisitList(); 22 ElemType elem; 23 //删除尾结点 24 list.DeleteNode(6, &elem); 25 //删除第一个结点 26 list.DeleteNode(1, &elem); 27 //删除中间结点 28 list.DeleteNode(3, &elem); 29 list.VisitList(); 30 list.ClearList(); 31 list.VisitList(); 32 33 return 0; 34 }
测试结果:
2.5 双向循环链表
双向循环链表与双向链表的区别就在于头结点的前驱指针指向最后一个结点、尾结点的后继指针指向头结点。实现时注意循环条件改变即可。
该篇博客是自己的学习博客,水平有限,如果有哪里理解不对的地方,希望大家可以指正!
