扫描器在探测存活中对于JavaScript重定向情况的注意点
前言:记录一下扫描器在探测存活中对于重定向情况的注意点
meta标签重定向情况
请求如下图所示,这种域名的资产搜集的话就需要匹配meta标签来获取url进行重定向操作
第一种情况
<meta http-equiv=refresh content=0;url=index.jsp>
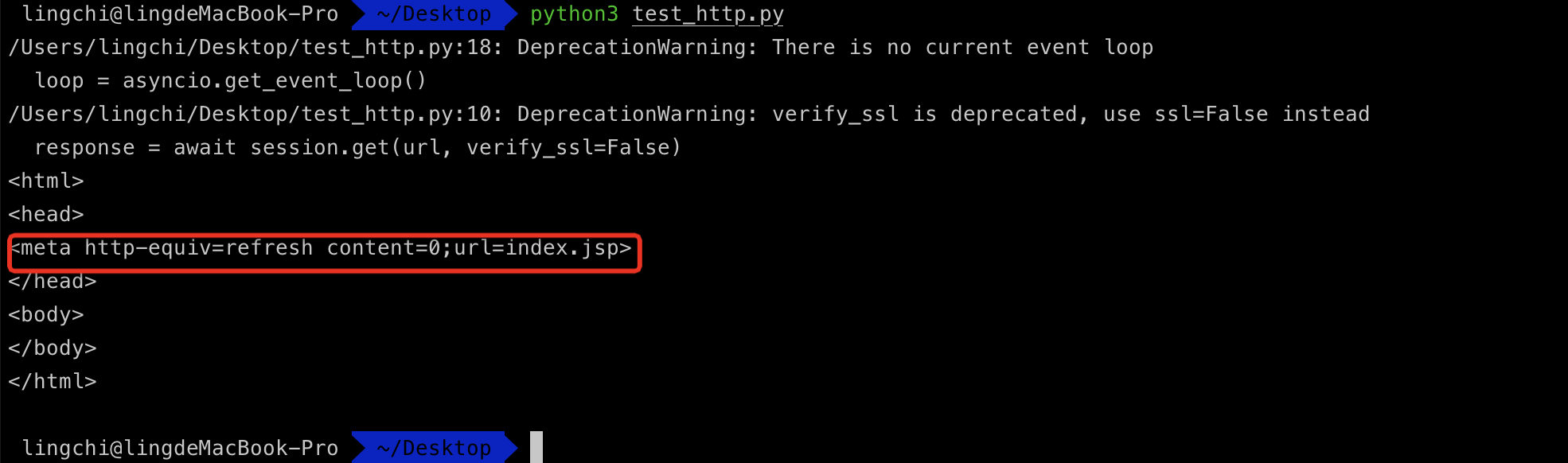
正确处理应该就是原url拼接index.jsp,如下图所示
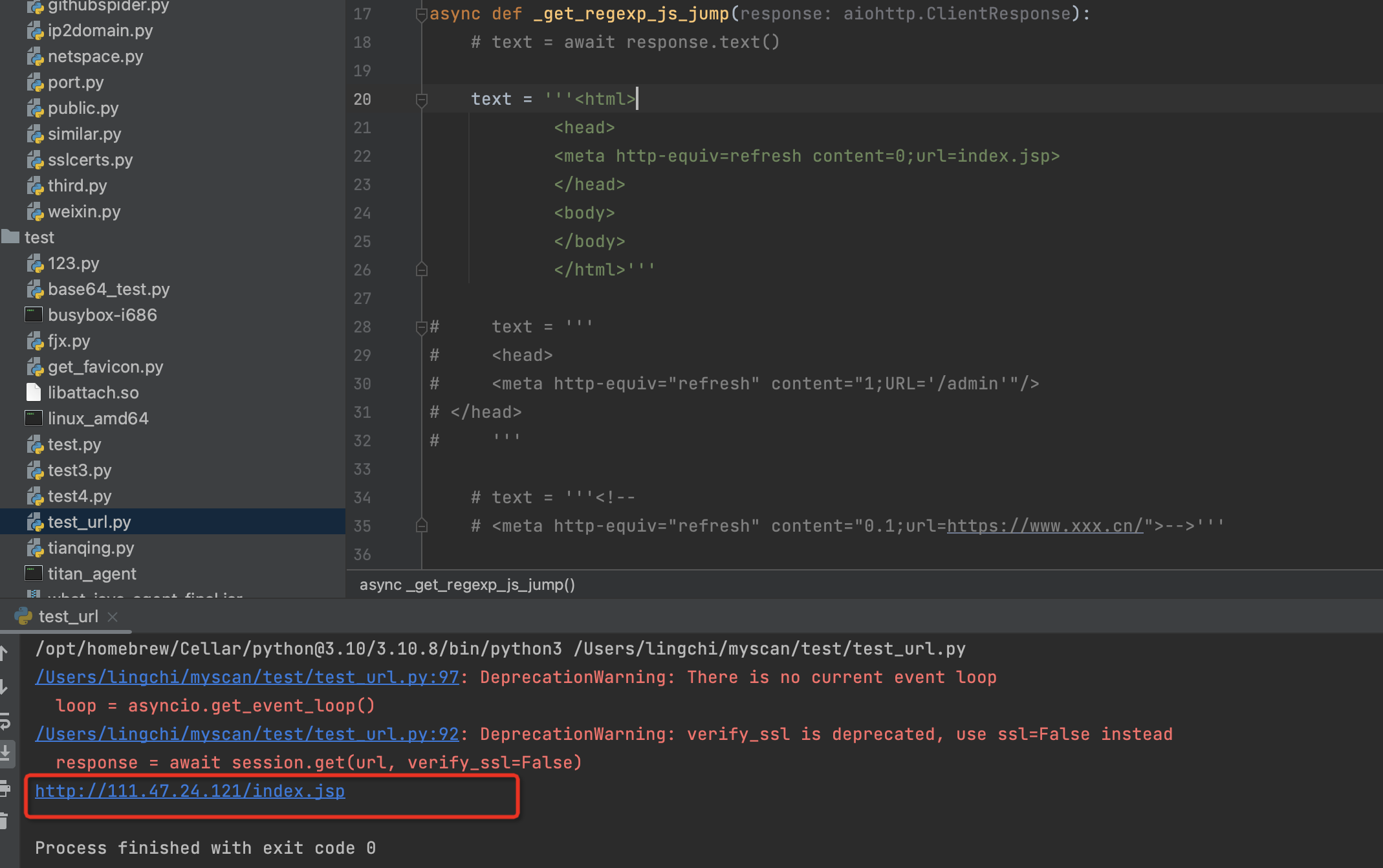
第二种情况
<head>
<meta http-equiv="refresh" content="1;URL='/admin'"/>
</head>
正确处理应该就是原url拼接上/admin
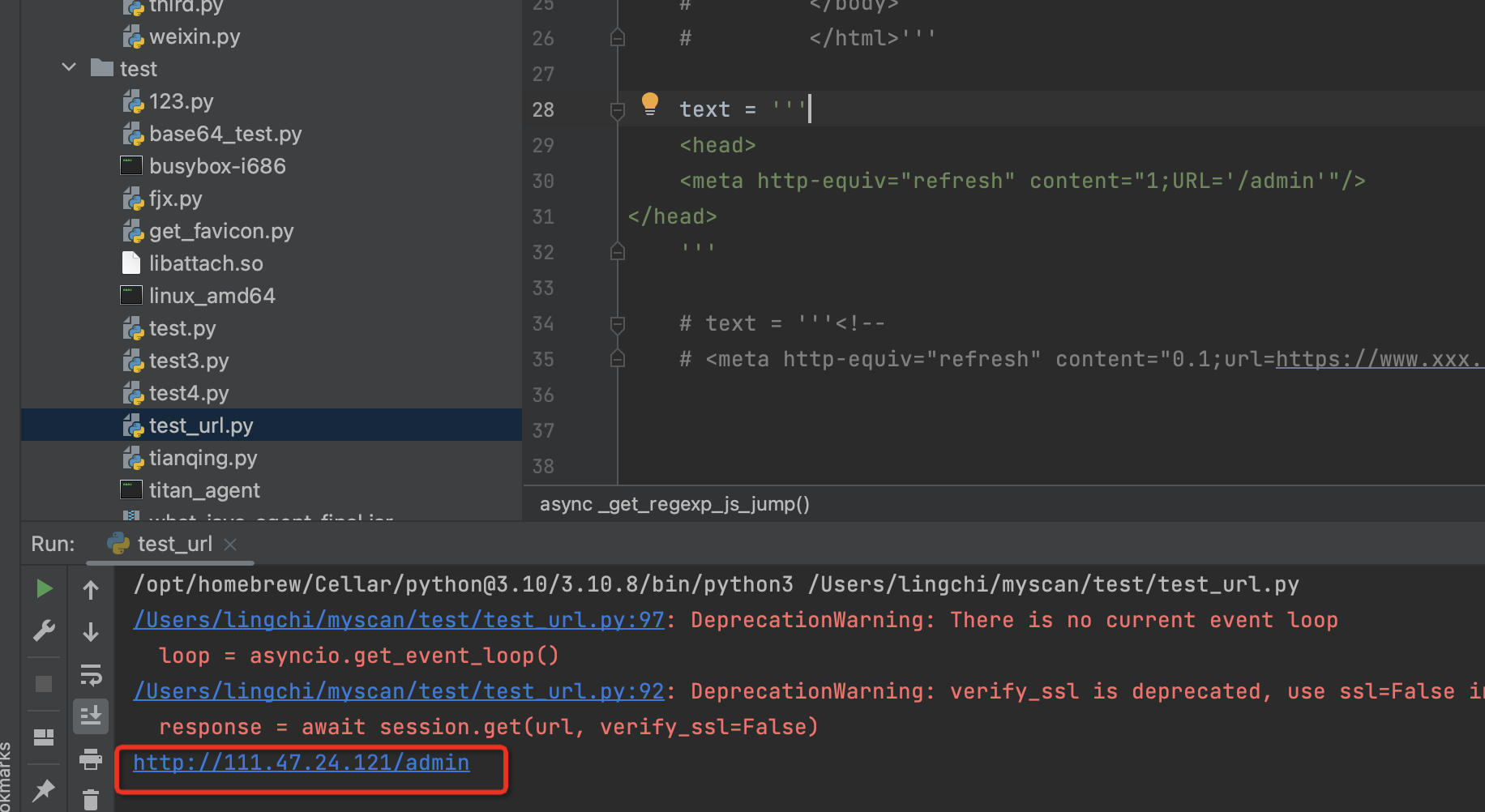
第三种情况
<!--
<meta http-equiv="refresh" content="0.1;url=https://www.xxx.cn/">
-->
正确处理应该就是不处理,应该存在<!--的情况

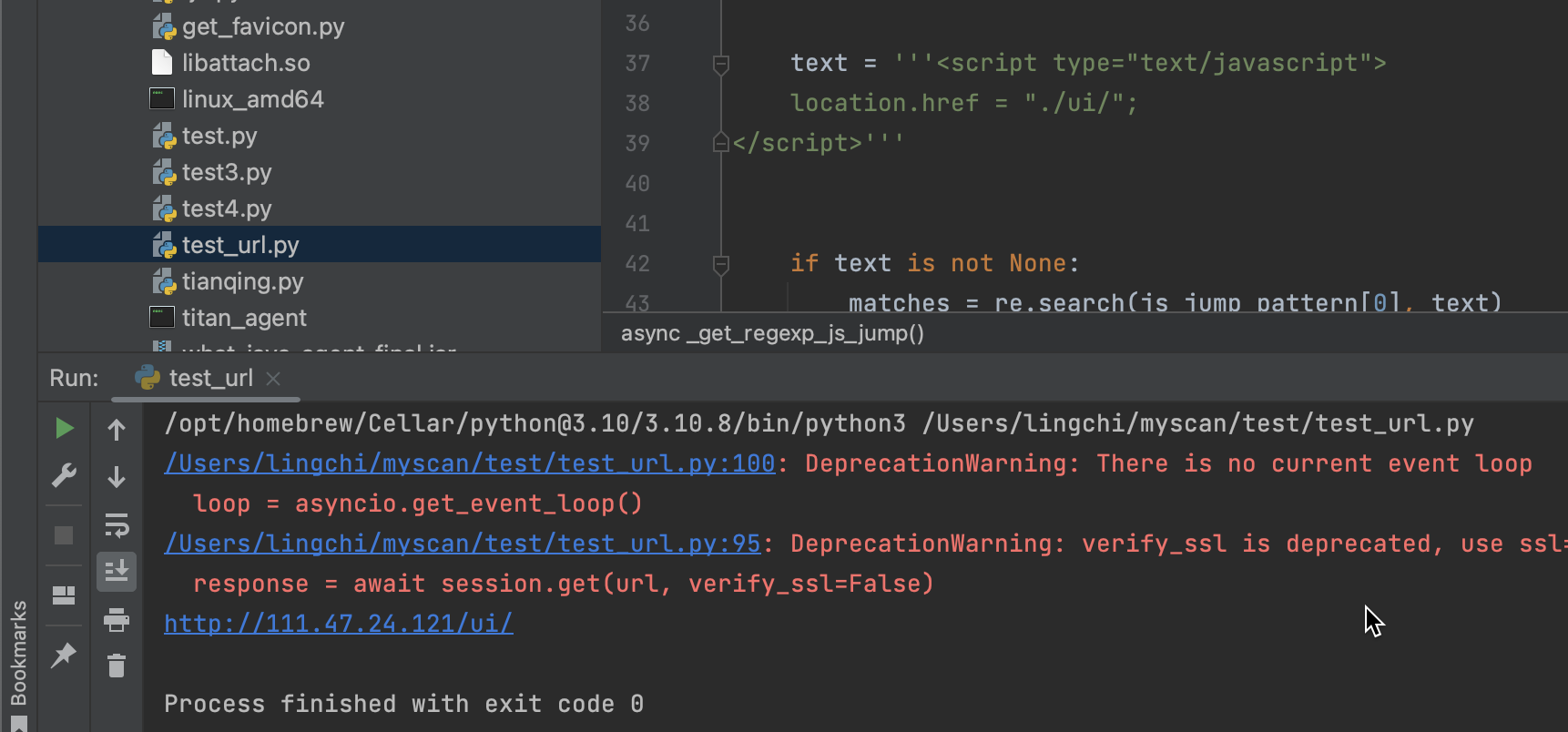
location.href重定向情况
<script type="text/javascript">
location.href = "./ui/";
</script>
正确处理应该是原url拼接/ui
window.location.replace重定向情况
<script language="javascript">
window.location.replace("/mymeetings/");
</script>
正确处理应该是原url拼接/mymeetings/
代码实现
# coding=utf-8
import asyncio
import hashlib
from ipaddress import ip_address
from random import random
from typing import Tuple, Any, Union
import aiohttp
import re
js_jump_pattern = [
re.compile(r'(?i)<meta.*?http-equiv=.*?refresh.*?url=(.*?)/?>'),
re.compile(r'(?i)[window\.]?location[\.href]?.*?=.*?[\"\'](.*?)[\"\']'),
re.compile(r'(?i)[window\.]?location\.replace\([\'\"](.*?)[\'\"]\)'),
]
# host_pattern = re.compile(r'(?i)https?://(.*?)/')
# replace_string = {}
async def _get_regexp_js_jump(response: aiohttp.ClientResponse):
text = await response.text()
# for r_string in replace_string:
# text = text.replace(r_string, '', replace_string[r_string])
if text is not None:
# replace_flag = True
matches = re.search(js_jump_pattern[0], text)
if matches is not None and len(matches.group()) > 0:
if text is not None and '<!--' not in text \
and 'nojavascript.html' not in matches.group(1) \
and '<!--[if lt IE 7]>' not in text:
# for r_string in replace_string:
# if r_string == matches.group(0):
# replace_string[r_string] += 1
# replace_flag = False
# if replace_flag:
# replace_string[matches.group(0)] = 1
return matches.group(1)
# 这个是针对用友nc的设置
if len(text) > 700:
text = text[:700]
matches = re.search(js_jump_pattern[1], text)
if matches is not None and len(matches.group()) > 0:
# for r_string in replace_string:
# if r_string == matches.group(0):
# replace_string[r_string] += 1
# replace_flag = False
# if replace_flag:
# replace_string[matches.group(0)] = 1
return matches.group(1)
matches = re.search(js_jump_pattern[2], text)
if matches is not None and len(matches.group()) > 0:
# for r_string in replace_string:
# if r_string == matches.group(0):
# replace_string[r_string] += 1
# replace_flag = False
# if replace_flag:
# replace_string[matches.group(0)] = 1
return matches.group(1)
return ''
async def _get_js_jump(response: aiohttp.ClientResponse):
match_result = await _get_regexp_js_jump(response)
jump_url = ''
if match_result != '':
match_result = match_result.strip()
match_result = match_result.replace( "\"", "")
match_result = match_result.replace("'", "")
match_result = match_result.replace("./", "/")
if match_result.startswith('http'):
jump_url = match_result
elif match_result.startswith('/'):
# // 前缀存在 / 时拼接绝对目录
base_url = response.url.scheme + '://' + response.url.host
jump_url = base_url + match_result
else:
# // 前缀不存在 / 时拼接相对目录
base_url = response.url.scheme + '://' + response.url.host + ':' + str(response.url.port) + '/' + response.url.path + '/'
base_url = base_url.replace('./', '')
base_url = base_url.replace('///', '/')
jump_url = base_url + match_result
return jump_url
async def test(url):
# http://111.47.24.121:8081/
async with aiohttp.ClientSession() as session:
response = await AsyncFetcher.fetch_response(session=session, url=url, timeout=60)
for i in range(3):
jump_url = await _get_js_jump(response)
print(jump_url)
if jump_url == '':
break
response = await AsyncFetcher.fetch_response(session=session, url=jump_url, timeout=60)
print(await response.text())
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(test('http://111.47.24.121:8081/'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号