关于协程,yield,多线程,GIL,异步
前言:对异步,协程一直以来都有点疑惑,认识的层面是在于同步和异步的字面意思,这篇作为异步的原理和学习的笔记
异步实现的原理
硬盘,显卡这些硬件是可以不消耗CPU资源而自动与内存交换数据的,这也是实现异步的基本条件,当数据交互完成,再触发指定的回调函数,来实现异步之后的同步。所以这也是异步I/O操作全部是通过异步回调来实现的原因。
参考文章:https://www.cnblogs.com/ckym/p/11438497.html
多线程和异步的关系
什么是多线程?多线程是实现异步的一种技术。
异步是一种技术功能要求,多线程是实现异步的一种手段。除了使用多线程可以实现异步,异步I/O操作也能实现(这个操作就是python的gevent和asyncio)。
为什么想要了解协程?
在讨论 CPython 基于线程的并行时,全局解释器锁(GIL)是一个大家都有讨论的问题。
根据 Python 的官方文档,我们知道 GIL 是一个互斥锁,用于防止本机多个线程同时执行字节码。换句话说,GIL确保 CPython 在程序执行期间,同一时刻只会使用操作系统的一个线程。不管你的 CPU 是多少核,以及你开了多少个线程,但是同一时刻只会使用操作系统的一个线程、去调度一个CPU。

协程与多线程
协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
参考文章:https://www.cnblogs.com/traditional/p/13289905.html
那上面的意思是不是在python以cpython解释器运行的时候,对于threading模块是不是就毫无作用?
因为 GIL 的存在使得同一时刻只有一个核被使用,所以对于纯计算的代码来说,理论上多线程和单线程是没有区别的。并且由于多线程涉及上下文的切换,会额外有一些开销,所以反而还慢一些。
什么时候threading模块能起作用?
对于处理IO操作而非计算操作的线程,python的多线程还是非常有用的,但是比起协程,多线程还是慢了一点
原因:python多线程在处理IO的时候,一个线程获得GIL发送消息,然后等待返回消息(阻塞),此时得python则会释放GIL锁,其他线程得到GIL发送消息,然后同样等待返回消息(阻塞),这样保证了IO传输过程时间的合理利用,提高IO传输效率,节省了一个http请求访问响应返回这个过程中间所用的时间。
解决GIL问题的方案
1.使用其它语言,例如C,Java
2.使用其它解释器,如java的解释器jpython
3.使用多进程
线程释放GIL锁的情况:
1.在IO操作等可能会引起阻塞的system call之前,可以暂时释放GIL,但在执行完毕后,必须重新获取GIL。
2.Python 3.x使用计时器(执行时间达到阈值后,当前线程释放GIL)或Python 2.x,tickets计数达到100。
python中协程实现的原理
想要实现协程异步IO,那么就需要自己来进行代码运行的控制流程,那么就不得不开始从yield开始谈起,如下代码所示
def A():
print('1')
print('2')
print('3')
def B():
print('x')
print('y')
print('z')
如果我想要它运行的结果为,那么我该如何进行编写
1
2
x
y
3
z
yield编写
def A():
print('1')
yield None
print('2')
yield None
print('3')
def B():
print('x')
yield None
print('y')
yield None
print('z')
genA = A()
genB = B()
next(genA)
next(genA)
next(genB)
next(genB)
# 因为生成器/协程在正常返回退出时会抛出一个StopIteration异常,而原来的返回值会存放在StopIteration对象的value属性中,通过以下捕获可以获取协程真正的返回值
try:
next(genA)
except StopIteration as e:
pass
try:
next(genB)
except StopIteration as e:
pass

这里可以想下,如果此时yield的是正在进行读写的任务,那么我们来进行控制代码的流程走向,让它先去干其他的事情,等读写完了再回来进行操作不就实现了异步IO的相关操作了
关于yield
先介绍下yield,个人认为,Python中的yield,也是说的生成器,最大的特点就是yield能中断函数(同时保存函数的状态),而"产生"出一个中间结果,而在中间结果的时候能进行切换运行操作。
我这里介绍了三种应用
第一种:通过yield来进行指定大小读取文件
通过 yield,我们不再需要编写读文件的迭代类
# 通过yield来进行指定大小读取
def test():
with open("TTTT.exe", "rb") as f:
while True:
lineContent = f.read(1024)
if lineContent:
print(lineContent)
yield lineContent
gen = test()
print(next(gen))
print(next(gen))
print(next(gen))

第二种:转化可迭代对象
# 字符串
astr = 'ABC'
# 列表
alist = [1, 2, 3]
# 字典
adict = {"name": "wangbm", "age": 18}
# 生成器
agen = (i for i in range(4, 8))
def test(*args, **kwargs):
for item in args:
for i in item:
yield i
gen = test(astr, alist, adict, agen)
a = list(gen) # 当list进行调用的时候,内部一次性进行next完全,返回所有的值和主键(字典),且转化为可迭代对象
for i in a: # 通过for来转化为迭代器进行遍历
print(i)
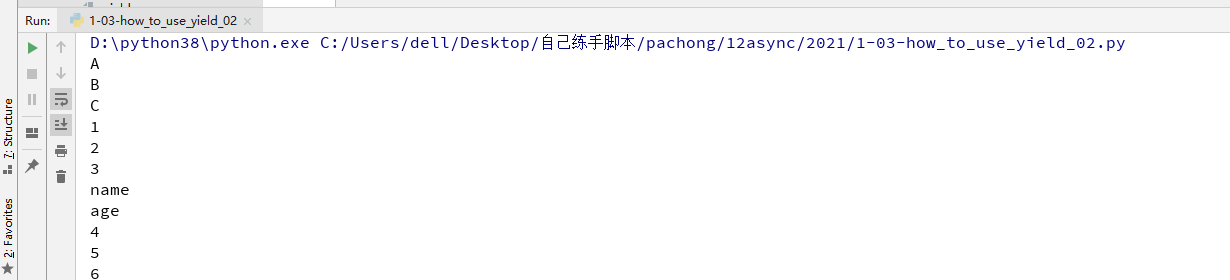
第三种,也就是上面的控制运行流程的实现,这里代码就不重复贴了
第四种:生产者与消费者
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK'
def produce(c):
c.send(None)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)

关于yield from
如果想要让生成器与生成器之间进行互相切换的话,这里就需要用到yield from
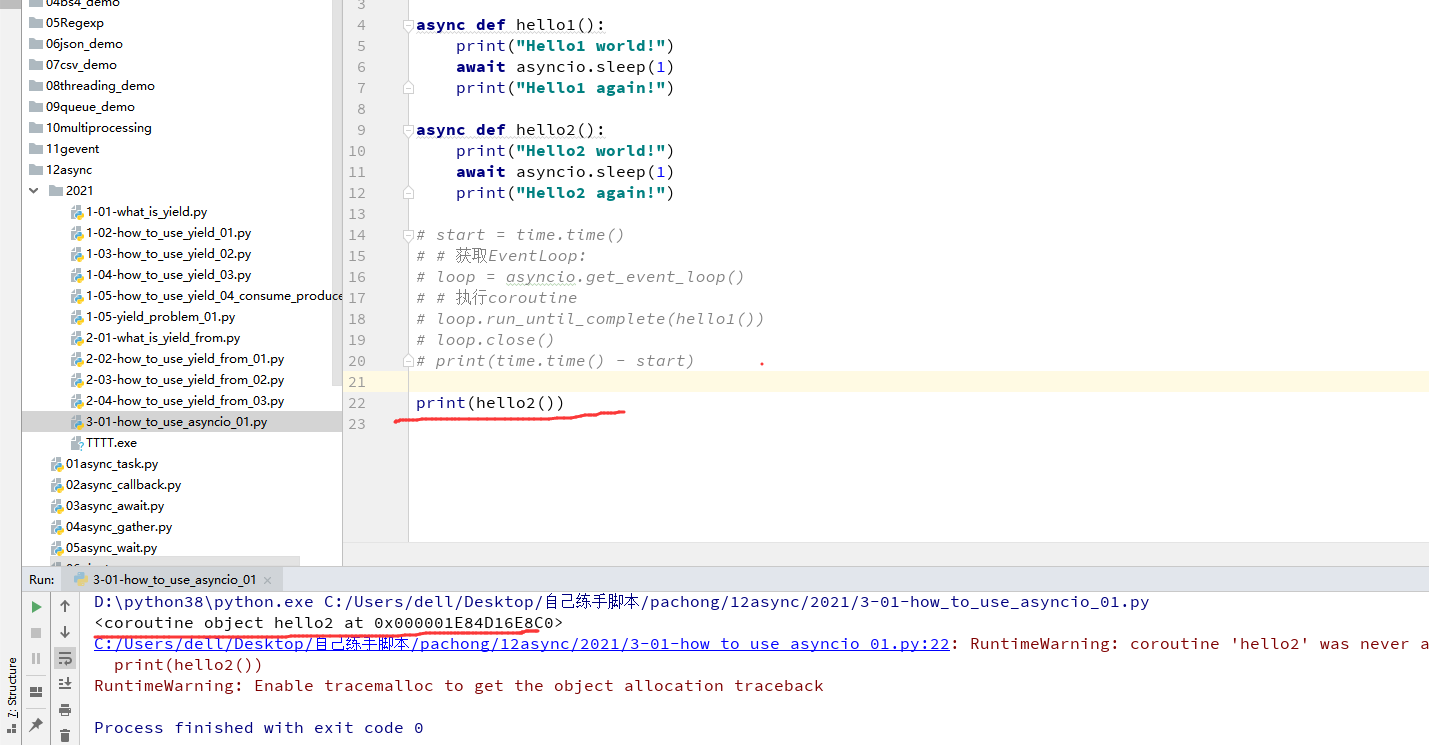
我这里运行的话是报错了, 因为我的版本是3.8的这种方式调用已经被废弃了,如下图所示
import threading
import asyncio
@asyncio.coroutine
def hello():
print('Hello world! (%s)' % threading.currentThread())
yield from asyncio.sleep(1)
print('Hello again! (%s)' % threading.currentThread())
loop = asyncio.get_event_loop()
loop.run_until_complete(hello())

上面的图中说用async def来进行代替,那么我们这里就用这种方法来进行代替,同时yield from也需要替换为await,写法不同,这里的await和yield from的作用一样,当遇到了相关的IO操作的时候,就会切换到另一个生成器中进行运行!
import threading
import asyncio
async def hello():
print('Hello world! (%s)' % threading.currentThread())
await asyncio.sleep(1)
print('Hello again! (%s)' % threading.currentThread())
loop = asyncio.get_event_loop()
loop.run_until_complete(hello())

async和@asyncio.coroutine的作用一样,声明这个函数为一个协程对象,如下图所示
这里可能看不出协程切换IO的作用,我们这里改成一次性运行两个生成器,就能体现协程的异步IO的作用了,测试代码如下图所示
import threading
import asyncio
async def hello():
print('Hello world! (%s)' % threading.currentThread())
await asyncio.sleep(1)
print('Hello again! (%s)' % threading.currentThread())
loop = asyncio.get_event_loop()
tasks = [hello(), hello()]
loop.run_until_complete(asyncio.wait(tasks))
可以看到两个任务,运行的时间还是1s

协程实现:标准的asyncio库
上面有简单的演示了下asyncio的使用,这里详细的讲下asyncio库的使用
asyncio是Python 3.4版本引入的标准库,直接内置了对异步IO的支持。
asyncio的编程模型就是一个事件循环EventLoop,每一个线程内部都存在一个 事件循环 的对象EventLoop,里面保存着需要进行的任务。
我们从asyncio模块中直接获取一个EventLoop的引用,然后把需要执行的多个协程扔到EventLoop中执行,EventLoop在处理的时候就会根据我们await的代码来对应的实现切换协程中的任务来进行运行。
继续看这一段代码,跟上面的演示代码还是一样。
import threading
import asyncio
async def hello():
print('Hello world! (%s)' % threading.currentThread())
await asyncio.sleep(1)
print('Hello again! (%s)' % threading.currentThread())
loop = asyncio.get_event_loop()
tasks = [hello(), hello()]
loop.run_until_complete(asyncio.wait(tasks))
这里的await asyncio.sleep(1)看成是一个耗时1秒的IO操作(被await修饰则说明是一个可以挂起的协程),在此期间,主线程并未等待,而是去执行EventLoop中其他可以执行的coroutine了,因此可以实现并发执行。
如下所示,整体运行1秒
那么这里的asyncio.get_event_loop 和 asyncio.wait 和 loop.run_until_complete 如何理解呢?
异步事件循环
asyncio.get_event_loop被调用的时候,主线程会获得一个异步事件循环的对象

loop.run_until_complete它会将传入的一个对象,并且堵塞当前线程直到其中的协程对象
如果要一次性执行多个协程对象的话,可以通过asyncio.wait来进行包装多个协程对象
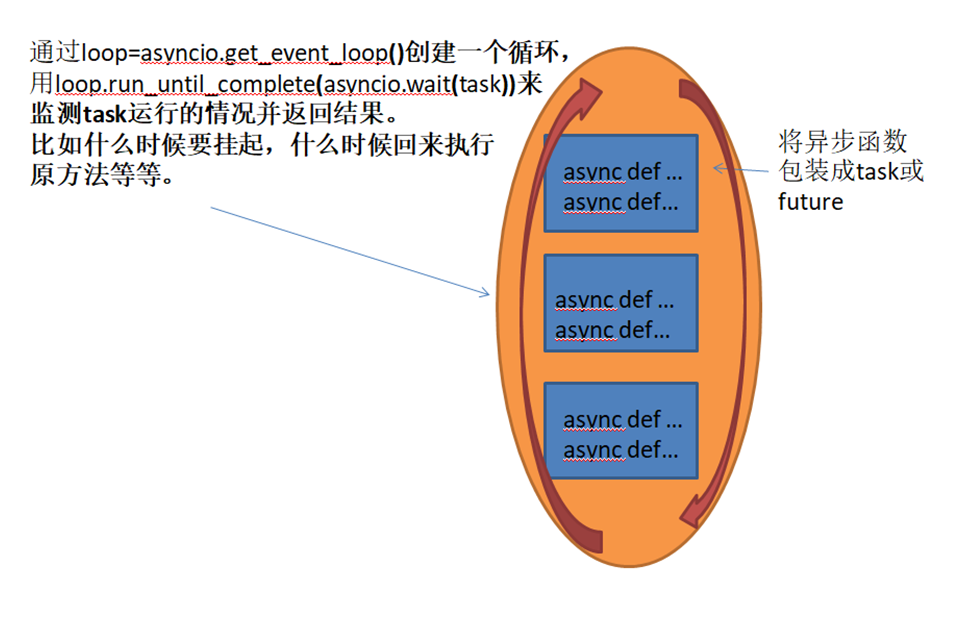
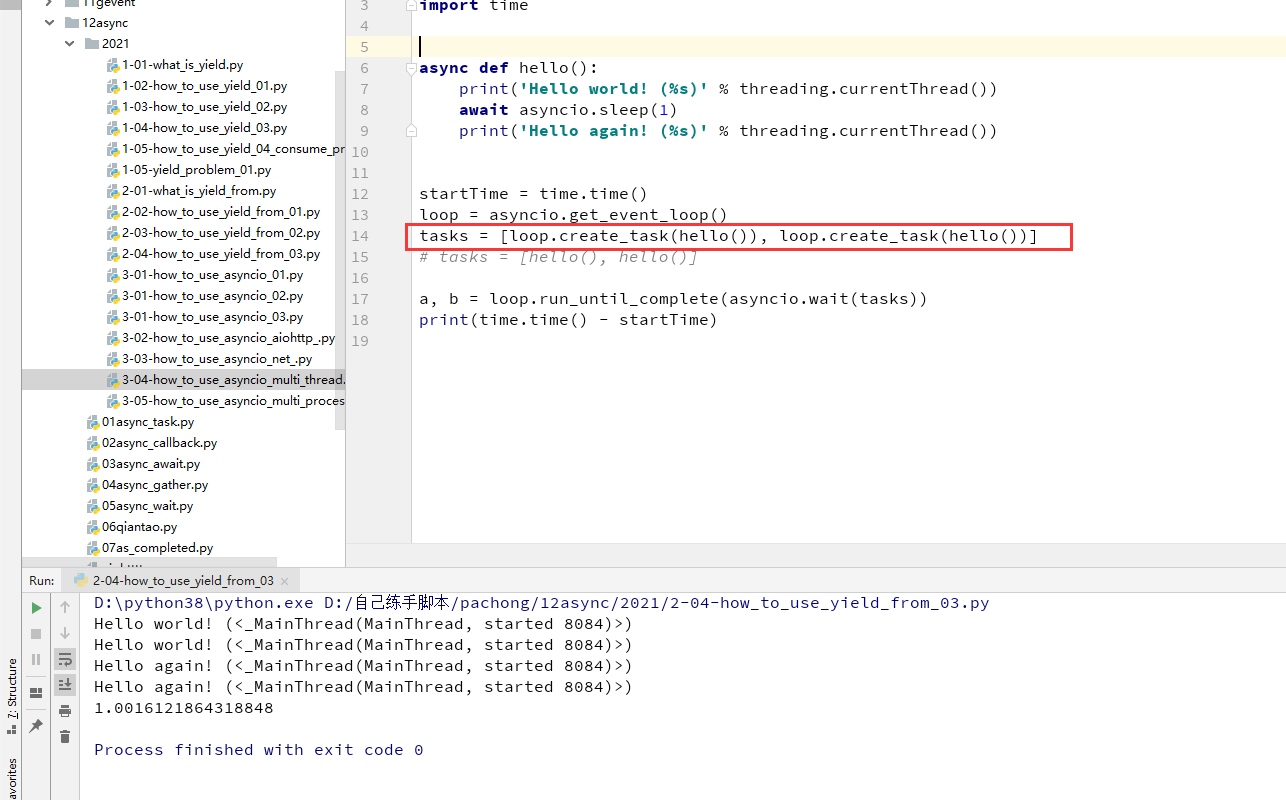
asyncio.wait可以看到,有时候可以直接传入协程对象,有时候又可以传入loop.create_task返回的对象,为什么两个对象都可以被asyncio.wait作为参数,如下面两图展示
async def hello():
print('Hello world! (%s)' % threading.currentThread())
await asyncio.sleep(1)
print('Hello again! (%s)' % threading.currentThread())
startTime = time.time()
loop = asyncio.get_event_loop()
tasks = [loop.create_task(hello()), loop.create_task(hello())]
# tasks = [hello(), hello()]
a, b = loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - startTime)
async def hello():
print('Hello world! (%s)' % threading.currentThread())
await asyncio.sleep(1)
print('Hello again! (%s)' % threading.currentThread())
startTime = time.time()
loop = asyncio.get_event_loop()
# tasks = [loop.create_task(hello()), loop.create_task(hello())]
tasks = [hello(), hello()]
a, b = loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - startTime)
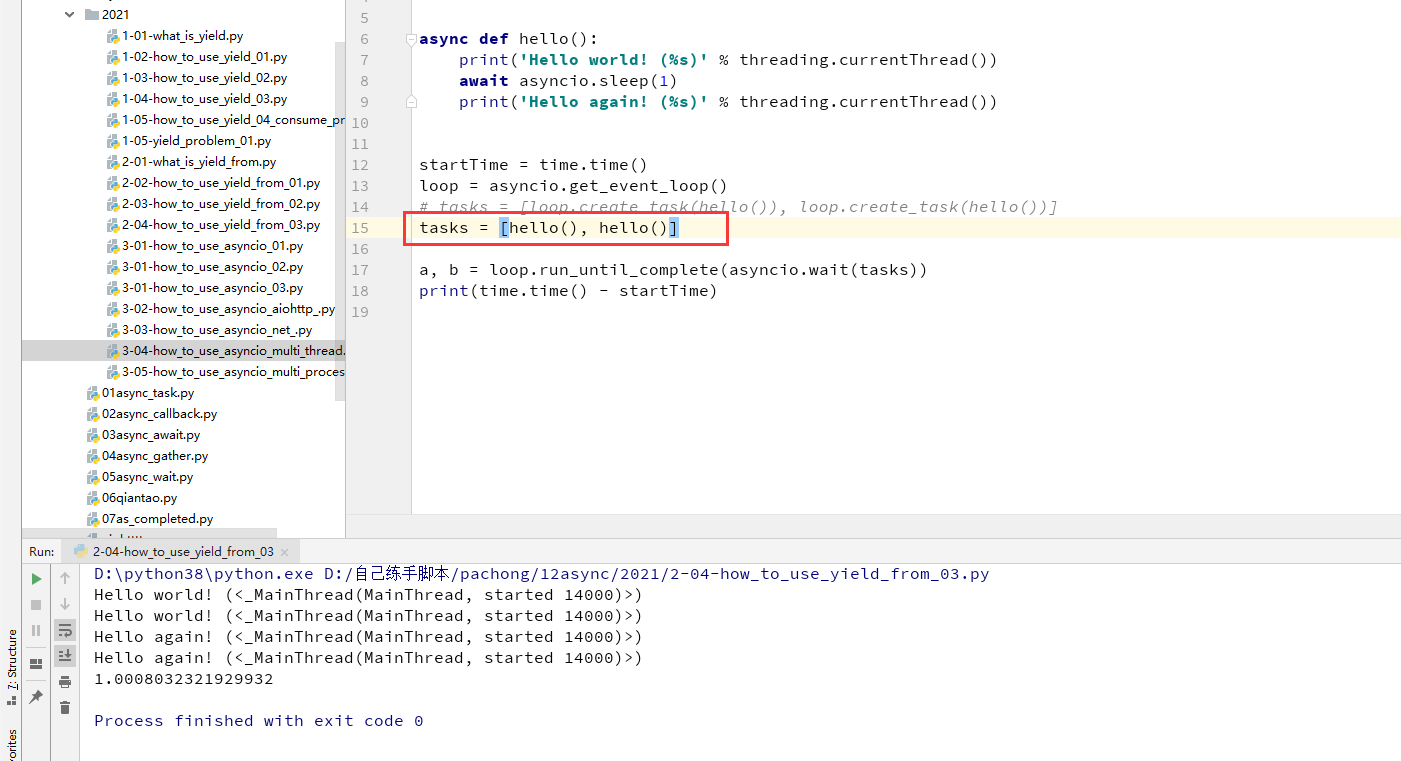
这里就需要说下关于"可等待对象",也就是await 后面的对象
可等待对象有三种主要类型: 协程,任务,Future。
create_task 函数所返回的是 Task(任务)类型,所以满足
直接传入协程对象,所以也同样满足!
异步网络请求IO
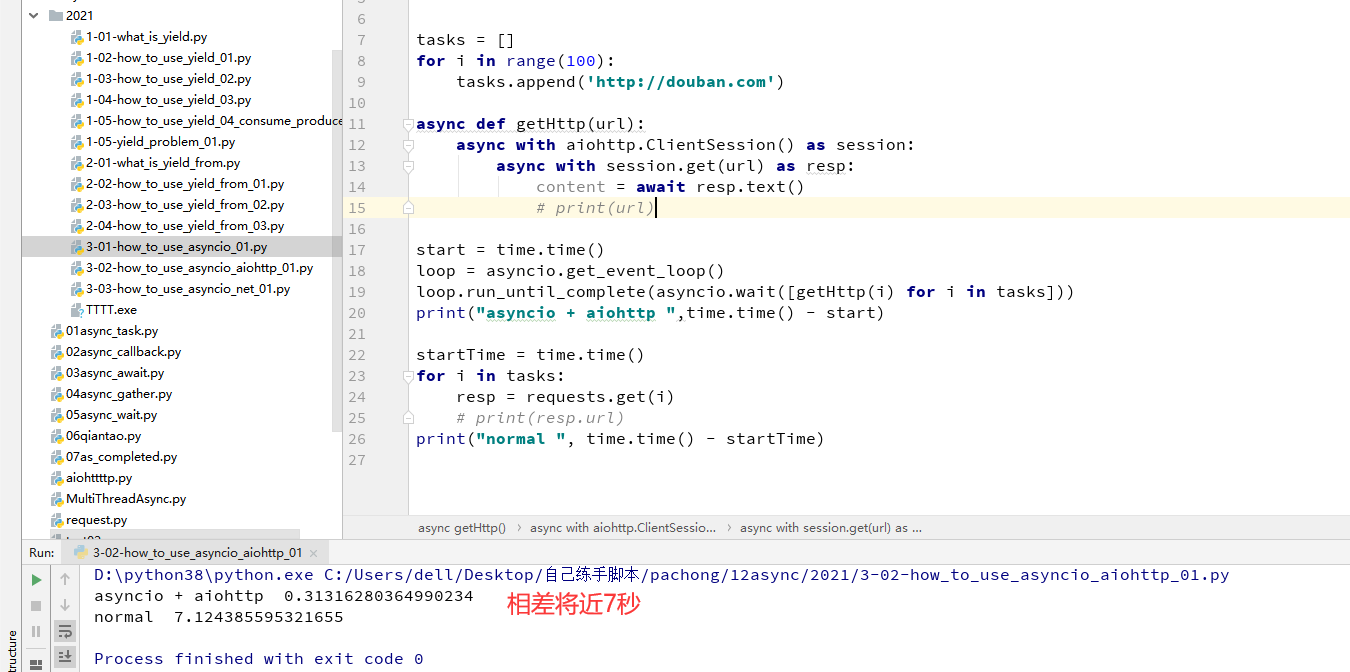
之前都是用asyncio.sleep(1)来进行模拟IO操作的,这里我们实战来实现异步IO的操作,因为使用的HTTP的异步IO操作,所以我们还需要用一个第三方库的aiohttp库的支持,它封装的就是可await的HTTP请求函数
这里对单线程和单线程异步IO来进行比较下,只请求了100条,时间相差将近7s
import asyncio
import aiohttp
import time
import requests
tasks = []
for i in range(100):
tasks.append('http://douban.com')
async def getHttp(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
content = await resp.text()
# print(url)
start = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait([getHttp(i) for i in tasks]))
print("asyncio + aiohttp ",time.time() - start)
startTime = time.time()
for i in tasks:
resp = requests.get(i)
# print(resp.url)
print("normal ", time.time() - startTime)
异步全端口扫描
from socket import socket, AF_INET, SOCK_STREAM
import time
import asyncio
from async_timeout import timeout
class ScanPort(object):
def __init__(self, ip, time_out=0.1, port=None, concurrency=500):
self.ip = ip
self.port = port
self.result = []
self.loop = asyncio.get_event_loop()
self.queue = asyncio.Queue()
self.timeout = time_out
self.concurrency = concurrency
async def scan(self):
while True:
t1 = time.time()
port = await self.queue.get()
sock = socket(AF_INET, SOCK_STREAM)
try:
with timeout(self.timeout):
# 这里windows和Linux返回值不一样
# windows返回sock对象,Linux返回None
await self.loop.sock_connect(sock, (self.ip, port))
t2 = time.time()
# 所以这里直接直接判断sock
print("扫描端口: ", port)
if sock:
self.result.append(port)
print(time.strftime('%Y-%m-%d %H:%M:%S'), port, 'open', round(t2 - t1, 2))
# 这里要捕获所有可能的异常,windows会抛出前两个异常,Linux直接抛最后一个异常
# 如果有异常不处理的话会卡在这
except (asyncio.TimeoutError, PermissionError, ConnectionRefusedError) as _:
sock.close()
sock.close()
self.queue.task_done()
async def start(self):
start = time.time()
if self.port:
for a in self.port:
self.queue.put_nowait(a)
else:
for a in range(1, 65535+1):
self.queue.put_nowait(a)
task = [self.loop.create_task(self.scan()) for _ in range(self.concurrency)]
# 如果队列不为空,则一直在这里阻塞
await self.queue.join()
# 依次退出
for a in task:
a.cancel()
# Wait until all worker tasks are cancelled.
await asyncio.gather(*task, return_exceptions=True)
print(f'扫描所用时间为:{time.time() - start:.2f}')
if __name__ == '__main__':
scan = ScanPort('150.158.186.39')
scan.loop.run_until_complete(scan.start())
还是有点问题,误报率很高,后面的开放端口基本就探测不到了,应该是代码哪里有问题,这个代码写的不行

多线程+协程的实现
根据asyncio的文档介绍,asyncio的事件循环不是线程安全的,一个event loop只能在一个线程内调度和执行任务,并且同一时间只有一个任务在运行。
这可以在asyncio的源码中观察到,当程序调用get_event_loop获取event loop时,会从一个本地的Thread Local对象获取属于当前线程的event loop:
class _Local(threading.local):
_loop = None
_set_called = False
def get_event_loop(self):
"""Get the event loop.
This may be None or an instance of EventLoop.
"""
if (self._local._loop is None and
not self._local._set_called and
isinstance(threading.current_thread(), threading._MainThread)):
self.set_event_loop(self.new_event_loop())
if self._local._loop is None:
raise RuntimeError('There is no current event loop in thread %r.'
% threading.current_thread().name)
return self._local._loop
如果启动了一个子线程,想要在子线程中进行相关协程操作的话,在获取事件循环的时候需要注意:
1、需要在子线程中进行new_event_loop,然后调用set_event_loop方法指定一个这个新的event_loop对象,这样在子线程中进行get_event_loop才会获取到被标记的event_loop对象
import asyncio
import threading
import time
import aiohttp
tasks = []
for i in range(10):
tasks.append('http://douban.com')
async def getHttp(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
content = await resp.text()
async def task():
print("task")
await asyncio.sleep(1)
async def task2():
print("task2")
await asyncio.sleep(1)
async def test():
await asyncio.sleep(1)
print('Hello again! (%s)' % threading.currentThread())
def run_loop_inside_thread():
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(asyncio.wait([getHttp(i) for i in tasks]))
if __name__ == '__main__':
startTime = time.time()
loop = asyncio.get_event_loop()
threadTasks = []
for i in range(10):
threadTasks.append(threading.Thread(target=run_loop_inside_thread).start())
asyncio和gevent的区别
1、asyncio 需要自己在代码中让出CPU,控制权在自己手中
2、gevent 用会替换标准库,你以为调用的是标准库的方法实际已经被patch,被替换成gevent自己的实现,遇到阻塞调用,gevent会自动让出CPU
asyncio可以理解为手动挡,gevent可以理解为自动挡
继续来写例子
协程本身无法进行异步IO操作,需要通过create_task
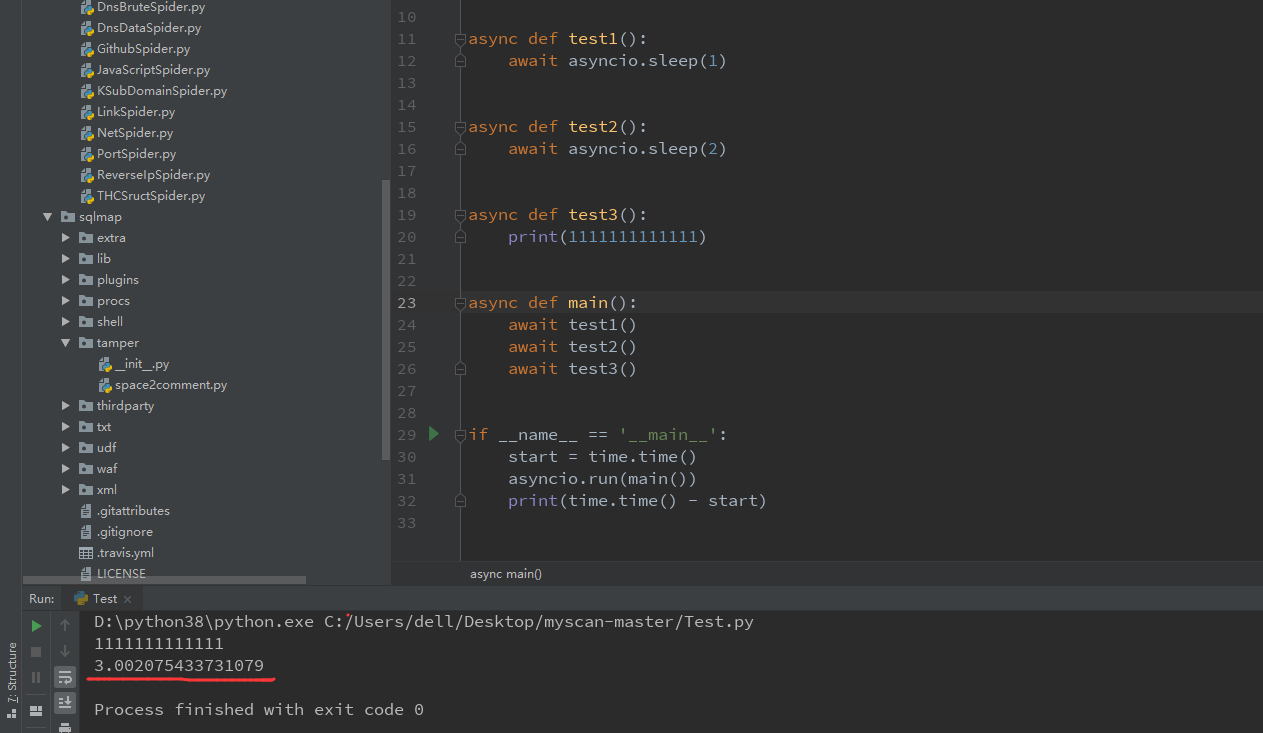
通过create_task封装之后的结果如下:

asyncio.run() 方法一般在当前线程中只调用一次,只作为asyncio的主程序入口点
asyncio.Queue
# coding=utf-8
# @Author : zpchcbd
# @Time : 2021-08-25 1:14
import asyncio
import time
async def test(queue: asyncio.Queue):
while 1:
item = await queue.get()
await asyncio.sleep(1)
print(item)
queue.task_done()
async def main():
queue = asyncio.Queue(-1)
for i in range(50):
await queue.put(i)
taskList = []
for i in range(5):
task = asyncio.create_task(test(queue))
taskList.append(task)
await queue.join()
for k in taskList:
k.cancel()
# await asyncio.gather(*taskList, return_exceptions=True)
if __name__ == '__main__':
start = time.time()
asyncio.run(main())
print(time.time() - start)
asyncio的一个小坑点
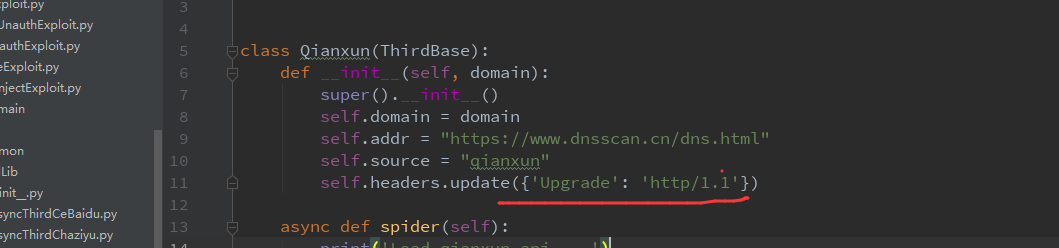
今天写东西的时候碰到了,记录下,有些网站用aiohttp访问,发现报错,内容为 ClientPayloadError: Response payload is not completed
我这里的问题就是,该网站请求是通过HTTP 2.0,但是aiohttp不支持,所以这里请求我们需要修改下请求,强制为HTTP/1.1来进行请求,解决方法如下图所示
Semaphore信号量同步机制限制并发量
from aiohttp import ClientSession
import asyncio
######################
# 限制协程并发量
######################
async def hello(sem, url):
async with sem:
async with ClientSession() as session:
async with session.get(f'http://localhost:8080/{url}') as response:
r = await response.read()
print(r)
await asyncio.sleep(1)
def main():
loop = asyncio.get_event_loop()
tasks = []
sem = asyncio.Semaphore(5) # this
for i in range(100000):
task = asyncio.ensure_future(hello(sem, i))
tasks.append(task)
feature = asyncio.ensure_future(asyncio.gather(*tasks))
loop.run_until_complete(feature)
if __name__ == "__main__":
main()
asyncio的一个小坑点
今天在windows上面跑东西的时候遇到如下的错误
ValueError: too many file descriptors in select()
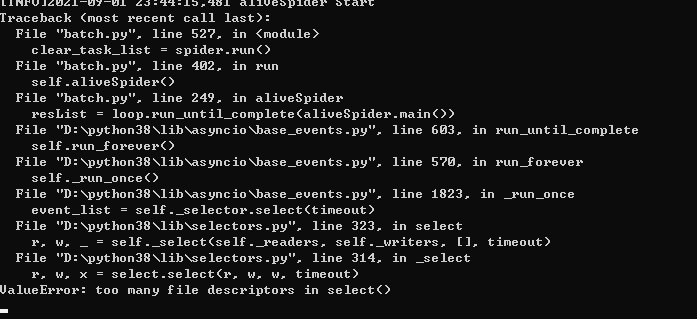
猜测可能是windows上面并发量的原因,查询得知如下
参考文章:https://blog.csdn.net/ranerju/article/details/88079852
假如你的并发达到2000个,程序会报错:ValueError: too many file descriptors in select()。 报错的原因字面上看是 Python 调取的 select 对打开的文件有最大数量的限制,这个其实是操作系统的限制,linux打开文件的最大数默认是1024,windows默认是509,超过了这个值,程序就开始报错。
这里我们有三种方法解决这个问题:
1、限制并发数量。(一次不要塞那么多任务,或者限制最大并发数量)
2、使用回调的方式。
3、修改操作系统打开文件数的最大限制,在系统里有个配置文件可以修改默认值,我这里说的是linux的环境,windows我不知道如何解决,我在windows环境上尝试用其他的时间循环,但是发现还是有其他的报错,最后还是使用了linux的环境来解决

 浙公网安备 33010602011771号
浙公网安备 33010602011771号