redis常见面试题
redis常见面试题
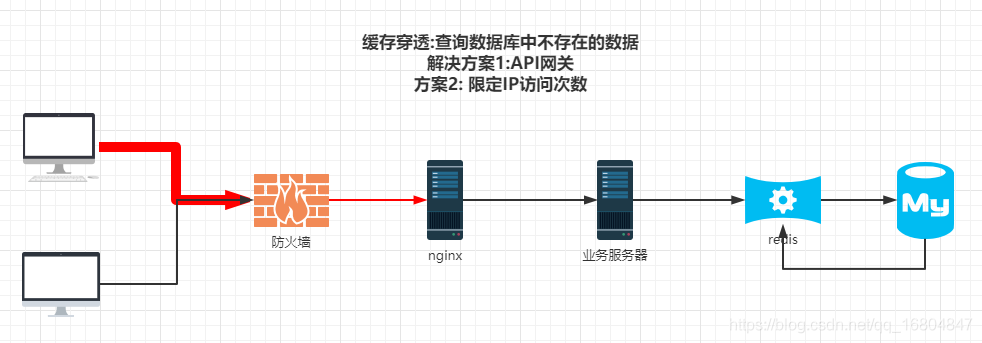
1. 缓存穿透
特点: 用户高并发环境下,访问数据库中根本不存在的数据.
影响:由于用户高并发访问,则数据库可能存在宕机的风险.
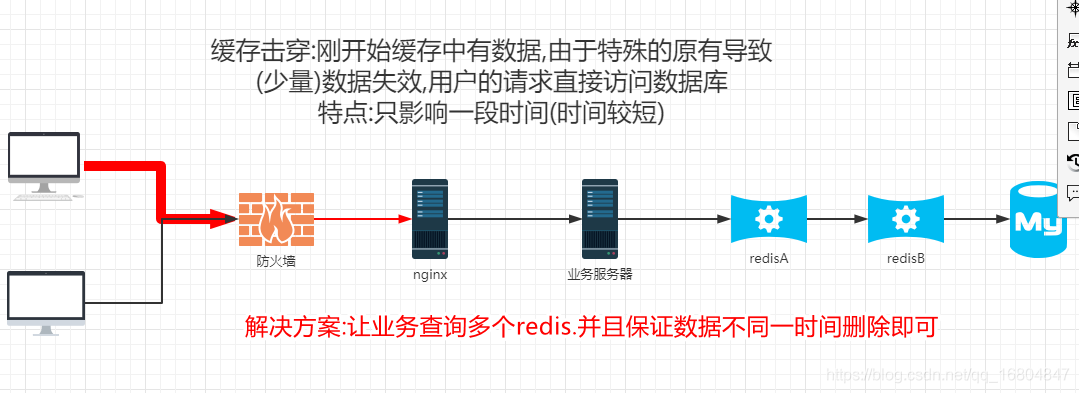
2. 缓存击穿
说明: 由于用户高并发的访问. 访问的数据刚开始有缓存,但是由于特殊原有 导致缓存失效.(数据’‘单个’’)
解决方案: 串联redis服务器, 并是redis缓存失效时间相差几秒至几十秒, 保证不再同一时间删除
3. 缓存雪崩
说明: 由于高并发的环境下.大量的用户访问服务器. redis中有大量的数据在同一时间超时(删除).
解决方案: 串联redis服务器, 并是redis缓存失效时间相差几秒至几十秒, 保证不再同一时间删除 (根缓存击穿解决方案类似)

4. Redis持久化问题
问题说明:
Redis中的数据都保存在内存中.如果服务关闭或者宕机则内存资源直接丢失.导致缓存失效.
持久化原理说明
Redis中有自己的持久化策略.Redis启动时根据配置文件中指定的持久化方式进行持久化操作. Redis中默认的持久化的方式为RDB模式.
4.1 RDB模式
特点说明:
- RDB模式采用定期持久化的方式. 风险:可能丢失数据.
- RDB模式记录的是当前Redis的内存记录快照. 只记录当前状态. 持久化效率最高的 (快照文件默认为redis目录下的dump.rdb)
- RDB模式是默认的持久化方式.
持久化命令:
- 命令1: save 同步操作. 要求记录马上持久化. 可能对现有的操作造成阻塞
- 名来2: bgsave 异步操作. 开启单独的线程实现持久化任务.
持久化周期:
save 900 1在900秒内,如果执行一次更新操作,则持久化一次.save 300 10在300秒内,如果执行10次更新操作,则持久化一次.save 60 10000在60秒内,如果执行10000次更新操作,则持久化一次.save 1 1不可以这样配置, 容易阻塞 性能太低.不建议使用.
用户操作越频繁,则持久化周期越短.
4.2 AOF模式
特点:
- AOF模式默认是关闭状态 如果需要则手动开启.
- AOF能够记录程序的执行过程可以实现数据的实时持久化. AOF文件占用的空间较大.回复数据的速度较慢.
- AOF模式开启之后.RDB模式将不生效.
AOF配置:
在redis配置文件中修改如下 (文件内容过多, 建议搜索关键字找到此配置)
# 开启AOF模式
appendonly=yes
# aof更新日志文件
appendfilename "appendonly.aof"
持久化周期配置:
-
appendfsync always实时持久化. -
appendfsync everysec每秒持久化一次 略低于rdb模式 -
appendfsync no自己不主动持久化(被动:由操作系统解决)手动持久化命令:
save由主进程完成(可能会阻塞),bgsave使用新的进程完成
4.3 如何选择持久化方式
思路: 如果允许数据少量的丢失,则首选RDB.(快),如果不允许数据丢失则使用AOF模式.
情景题案例
小张在双11前夜误操作将Redis服务器执行了flushAll命令. 问项目经理应该如何解决??
A: 痛批一顿 ,让其提交离职申请.
B: 批评教育, 让其深刻反省,并且请主管 捏脚.
C:项目经理快速解决.并且通知全部门注意.
解决方案:
修改aof文件中的命令.删除flushAll之后重启redis即可.
5. Redis内存优化策略
修改Redis内存大小
修改redis.conf配置文件 (大约566行), 以下为注释内容, 默认是注释掉的
# maxmemory <bytes>
修改bytes参数即可
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
场景说明
Redis运行的空间是内存.内存的资源比较紧缺.所以应该维护redis内存数据,将改让redis保留热点数据.
LRU算法
以下为百度内容, 下面所说的页面可以理解为redis中保存的数据
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
维度: 自上一次使用的时间T
最为理想的内存置换算法.
LFU算法
以下为百度内容, 下面所说的页面可以理解为redis中保存的数据
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
least frequently used (LFU) page-replacement algorithm
即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
维度: 引用次数
RANDOM算法
随机算法, 即内存不足的时候随机删除一些已有的数据
内存策略优化配置
大约在配置文件597行, 有以下被注释的内容
# maxmemory-policy noeviction
解除注释, 把noeviction改为以下配置即可, 默认为noeviction策略
volatile-lru在设定了超时时间的数据, 采用lru算法进行删除.allkeys-lru所有数据采用lru算法volatile-lfu在设定了超时时间的数据, 采用LFU算法进行删除.allkeys-lfu所有数据采用LFU算法volatile-random设定超时时间数据采用随机算法allkeys-random所有数据采用随机算法volatile-ttl设定了超时时间的数据 根据ttl规则删除. 将剩余时间少的提前删除noeviction内存满了 不做任何操作.报错返回.

