
爬虫-多线程抓取图片
一、目的
利用多线程的方式爬取图片,地址:其他电脑动态壁纸 - 其他桌面动态壁纸 - 元气壁纸 (cheetahfun.com)
二、分析
F12分析网页结构,图片的地址都在class = "flex flex-wrap justify-between font-normal"标签中的li里面,只需要在a标签中img中
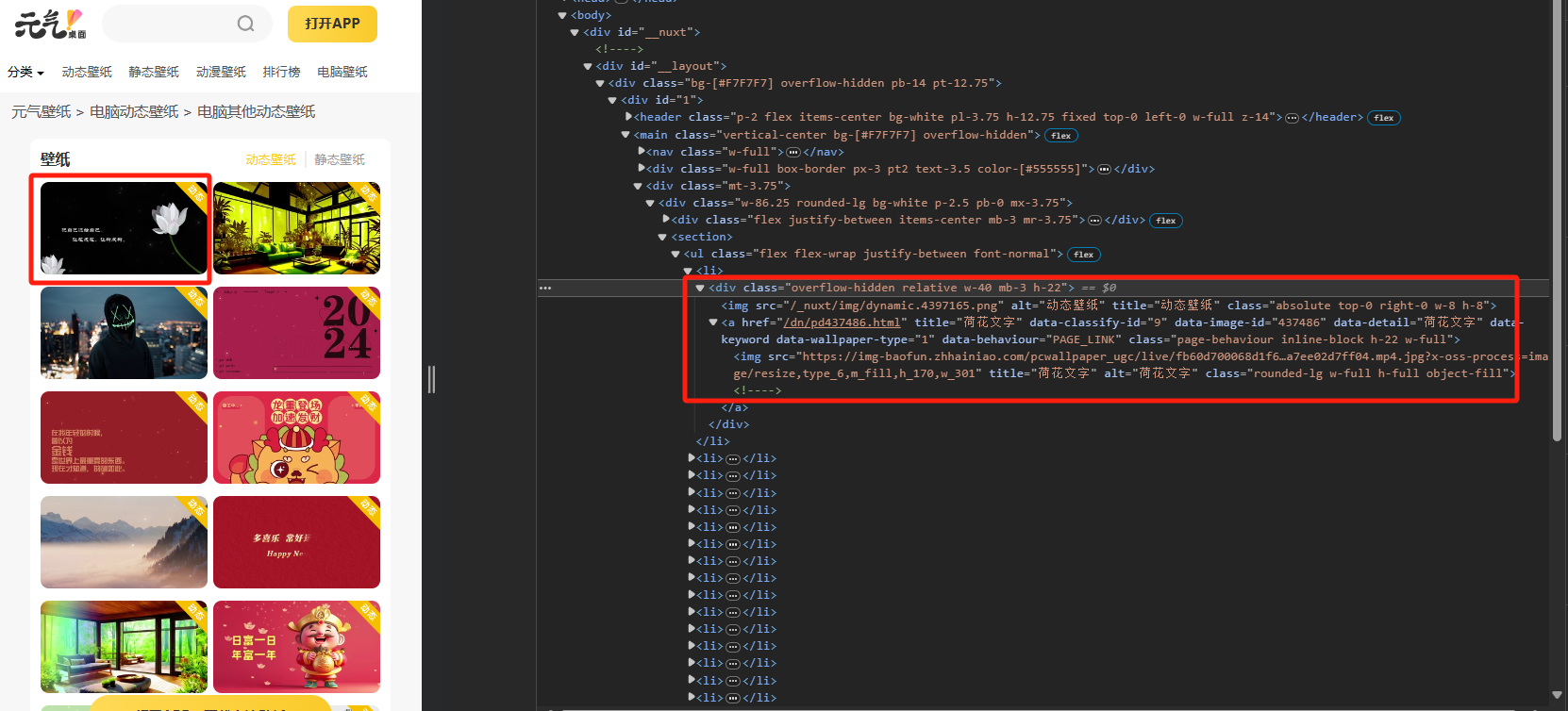
根据前面学过的内容,可以先写出单线程爬取图片的方式,在此基础上添加多线程

# -*- coding: utf-8 -*- #第一步:导包 from concurrent.futures import ThreadPoolExecutor import requests from lxml import etree import time headers = { "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36 Edg/120.0.0.0" } def download(url): resp = requests.get(url,headers) html = etree.HTML(resp.text) li_list = html.xpath('//*[@id="1"]/main/div[2]/div/section/ul/li') for li in li_list: pic_url = li.xpath('./div/a/img/@src')[0] pic_name = li.xpath('./div/a/img/@title')[0] # print(pic_name) # print(pic_url) with open("E:/元气图片/" + pic_name + ".png", mode="wb")as fp: fp.write(requests.get(pic_url).content) print(pic_name + "下载完成!!") time.sleep(1) if __name__ == '__main__': with ThreadPoolExecutor(5) as t: for i in range(1,10): url_Temp = f"https://mbizhi.cheetahfun.com/dn/c11d/p{i}" # print(url) t.submit(download, url=url_Temp)
注:多线程需要导包
from concurrent.futures import ThreadPoolExecutor
download方式,可以开启多个线程去同时调用此方法来请求获取图片,
with ThreadPoolExecutor(5) as t: for i in range(1,10): url_Temp = f"https://mbizhi.cheetahfun.com/dn/c11d/p{i}" t.submit(download, url=url_Temp)
这里的要开启5个线程去调用download方法


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现