
网络爬虫-处理cookie登录的问题,seesion的用法
一、以17k的小说网的登录为例,网址小说_17K小说网|最新小说下载-一起免费看小说
当想要在小说网中看一下书架上的书都有哪些,必须得先登录一个账户才能看到,不同的用户登录看到内容也是不一样的,服务器是如何区分的呢?
这里要引入cookie,不同的用户访问到服务器的时候,除了访问地址外,会带cookie去访问
通过输入用户名和密码来检查网页的情况,请求地址和方式,POST请求肯定会有参数的,
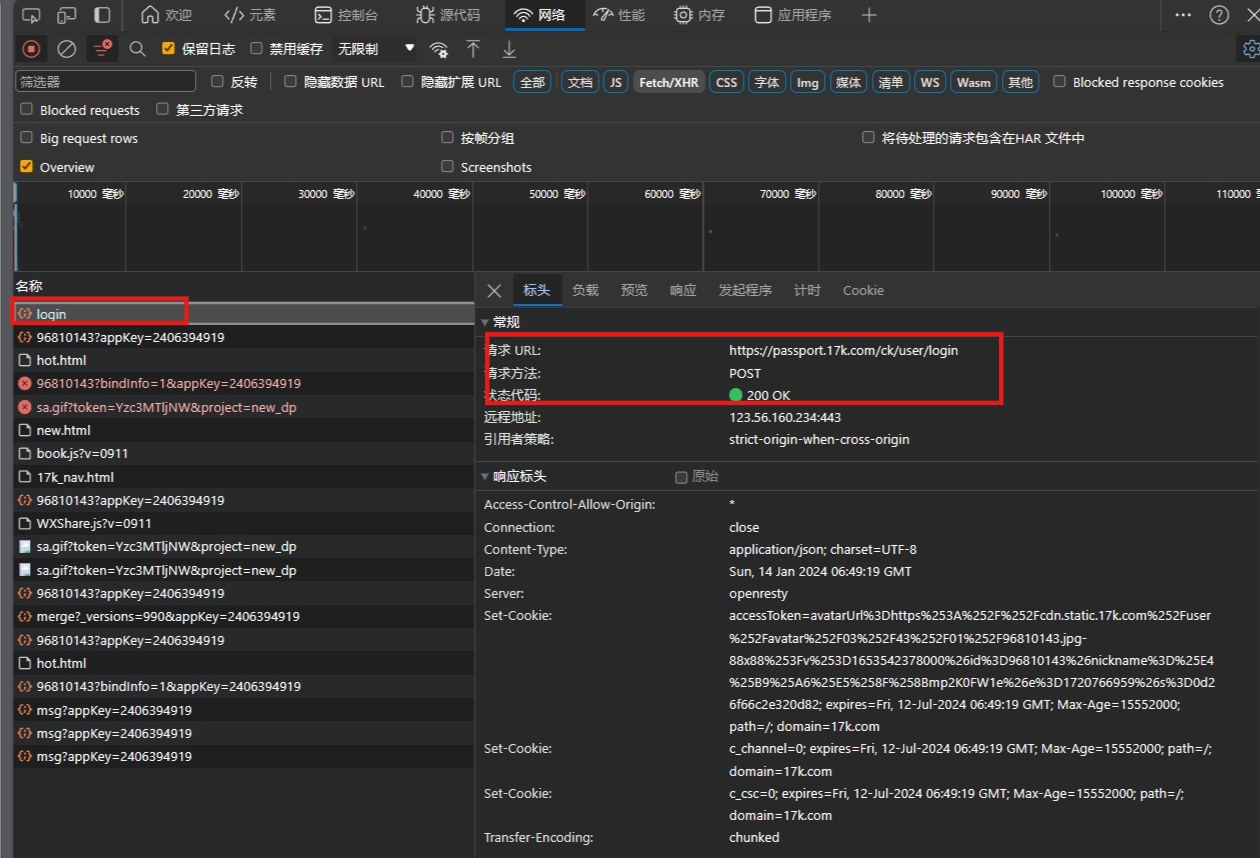
post的参数可以在负载里面找到:如下

在账户登录成功后,可以查看书架上的内容了,通过网页分析发现,书架上的内容可以在网页请求返回值里找到
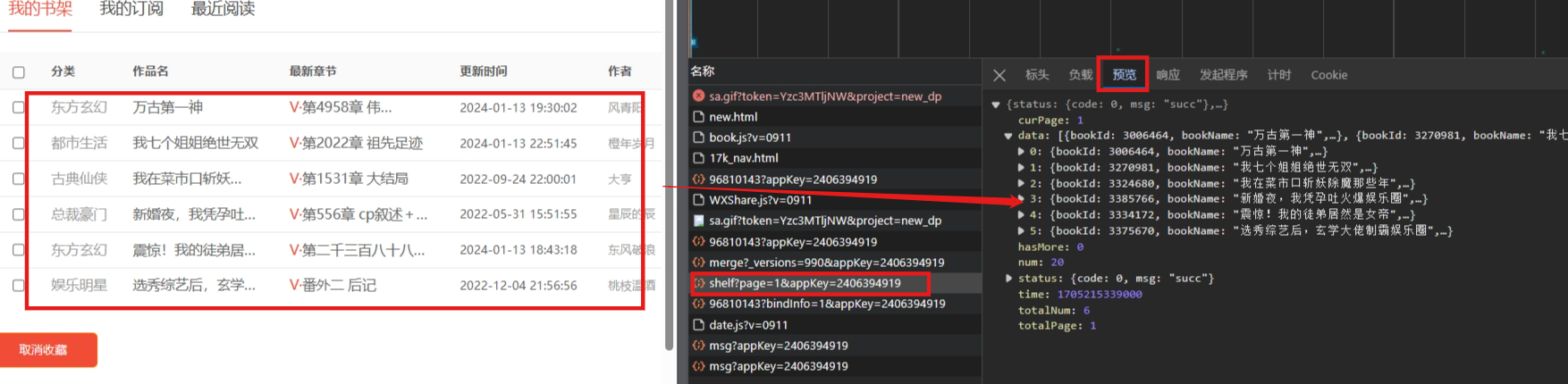
截止到目前,书架内容已经可以拿到了,后续解析一下数据内容
二、代码如下【流程】:
import requests #导包 import time #建立session会话 session = requests.Session() data = { "loginName":"13383868xxxx", "password":"xxxxx" } #1、登录:(这里的浏览器必须是login登录按钮的链接) url = "https://passport.17k.com/ck/user/login" #2、可以用F12检查浏览器的请求情况:可以找到cookie 把请求和cookie带进去 post还是get可以在浏览器中看到 session.post(url=url,data=data) # book_list = 'https://user.17k.com/www/bookshelf/' book_list = 'https://user.17k.com/ck/user/myInfo/96810143?bindInfo=1&appKey=2406394919' html = session.get(url=book_list) html.encoding = 'UTF-8' print(html.json())
运行结果:

上面注意事项:
注意要先建立会话,注意大小写
先登录请求,然后再获取数据内容的请求,在获取数据请求的时候,注意请求的链接,要用网页分析得到的链接来请求
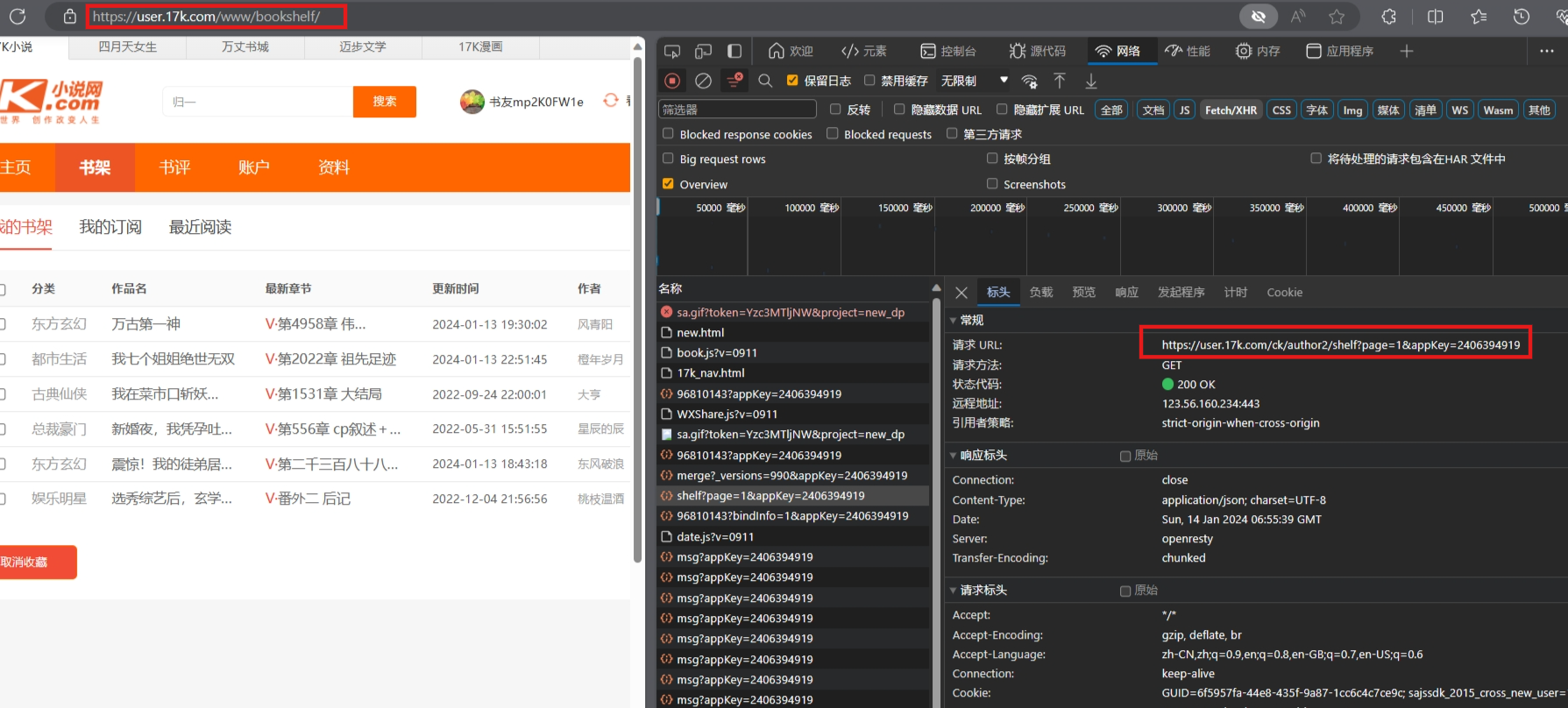
乱码的问题 :在request的时候就要指定编码格式:
html.encoding = 'UTF-8'
